 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntroducing the Hidden Neural Markov Chain framework
Feb 17, 2021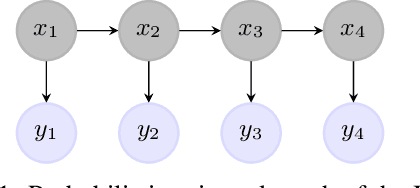

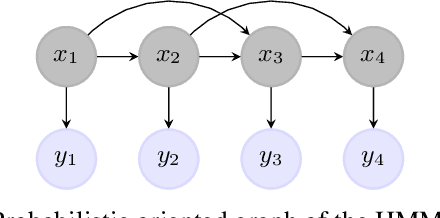

Nowadays, neural network models achieve state-of-the-art results in many areas as computer vision or speech processing. For sequential data, especially for Natural Language Processing (NLP) tasks, Recurrent Neural Networks (RNNs) and their extensions, the Long Short Term Memory (LSTM) network and the Gated Recurrent Unit (GRU), are among the most used models, having a "term-to-term" sequence processing. However, if many works create extensions and improvements of the RNN, few have focused on developing other ways for sequential data processing with neural networks in a "term-to-term" way. This paper proposes the original Hidden Neural Markov Chain (HNMC) framework, a new family of sequential neural models. They are not based on the RNN but on the Hidden Markov Model (HMM), a probabilistic graphical model. This neural extension is possible thanks to the recent Entropic Forward-Backward algorithm for HMM restoration. We propose three different models: the classic HNMC, the HNMC2, and the HNMC-CN. After describing our models' whole construction, we compare them with classic RNN and Bidirectional RNN (BiRNN) models for some sequence labeling tasks: Chunking, Part-Of-Speech Tagging, and Named Entity Recognition. For every experiment, whatever the architecture or the embedding method used, one of our proposed models has the best results. It shows this new neural sequential framework's potential, which can open the way to new models, and might eventually compete with the prevalent BiLSTM and BiGRU.
Highly Fast Text Segmentation With Pairwise Markov Chains
Feb 17, 2021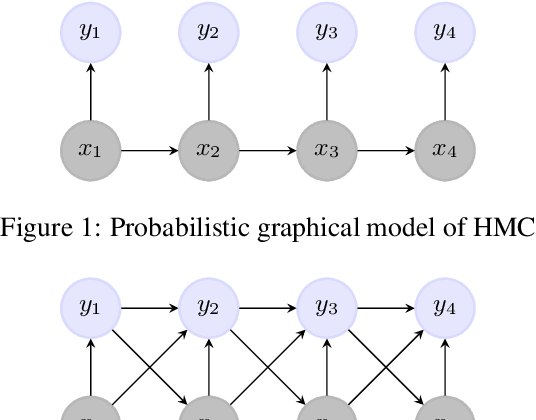
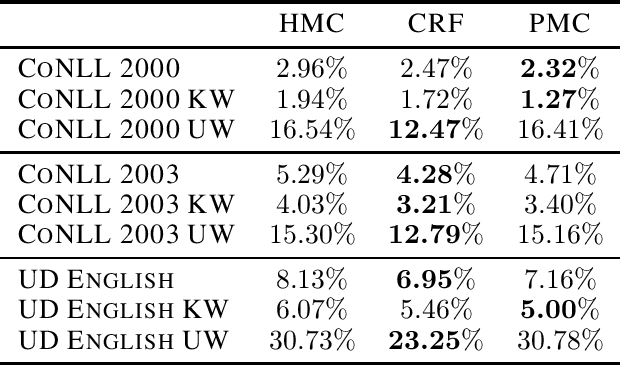
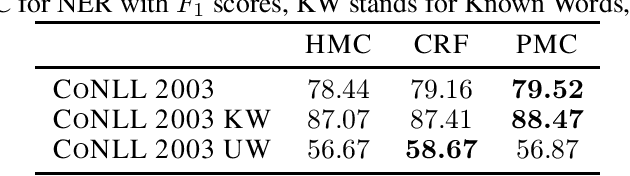
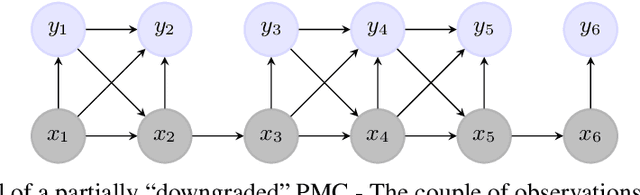
Natural Language Processing (NLP) models' current trend consists of using increasingly more extra-data to build the best models as possible. It implies more expensive computational costs and training time, difficulties for deployment, and worries about these models' carbon footprint reveal a critical problem in the future. Against this trend, our goal is to develop NLP models requiring no extra-data and minimizing training time. To do so, in this paper, we explore Markov chain models, Hidden Markov Chain (HMC) and Pairwise Markov Chain (PMC), for NLP segmentation tasks. We apply these models for three classic applications: POS Tagging, Named-Entity-Recognition, and Chunking. We develop an original method to adapt these models for text segmentation's specific challenges to obtain relevant performances with very short training and execution times. PMC achieves equivalent results to those obtained by Conditional Random Fields (CRF), one of the most applied models for these tasks when no extra-data are used. Moreover, PMC has training times 30 times shorter than the CRF ones, which validates this model given our objectives.
Hidden Markov Chains, Entropic Forward-Backward, and Part-Of-Speech Tagging
May 21, 2020
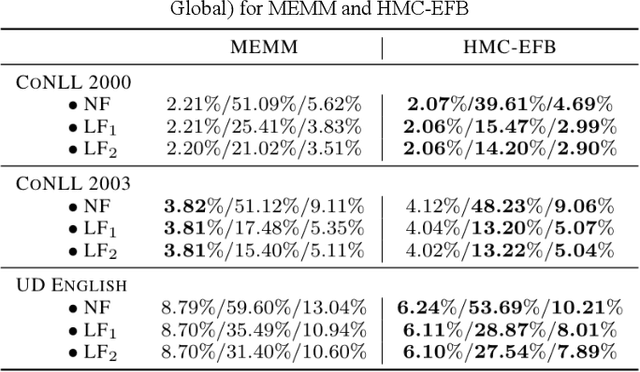
The ability to take into account the characteristics - also called features - of observations is essential in Natural Language Processing (NLP) problems. Hidden Markov Chain (HMC) model associated with classic Forward-Backward probabilities cannot handle arbitrary features like prefixes or suffixes of any size, except with an independence condition. For twenty years, this default has encouraged the development of other sequential models, starting with the Maximum Entropy Markov Model (MEMM), which elegantly integrates arbitrary features. More generally, it led to neglect HMC for NLP. In this paper, we show that the problem is not due to HMC itself, but to the way its restoration algorithms are computed. We present a new way of computing HMC based restorations using original Entropic Forward and Entropic Backward (EFB) probabilities. Our method allows taking into account features in the HMC framework in the same way as in the MEMM framework. We illustrate the efficiency of HMC using EFB in Part-Of-Speech Tagging, showing its superiority over MEMM based restoration. We also specify, as a perspective, how HMCs with EFB might appear as an alternative to Recurrent Neural Networks to treat sequential data with a deep architecture.
Heavy-tailed Representations, Text Polarity Classification & Data Augmentation
Mar 25, 2020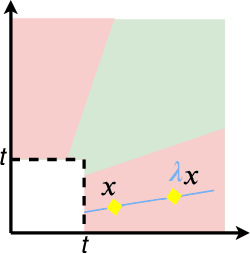
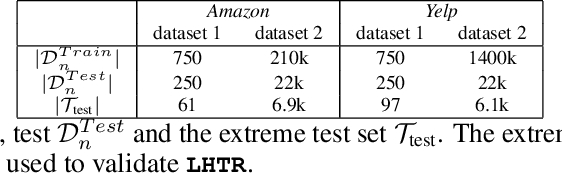
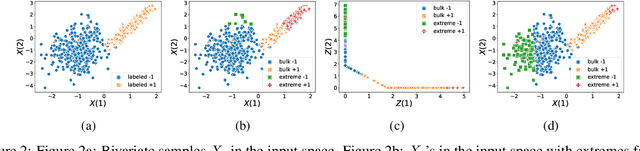
The dominant approaches to text representation in natural language rely on learning embeddings on massive corpora which have convenient properties such as compositionality and distance preservation. In this paper, we develop a novel method to learn a heavy-tailed embedding with desirable regularity properties regarding the distributional tails, which allows to analyze the points far away from the distribution bulk using the framework of multivariate extreme value theory. In particular, a classifier dedicated to the tails of the proposed embedding is obtained which performance outperforms the baseline. This classifier exhibits a scale invariance property which we leverage by introducing a novel text generation method for label preserving dataset augmentation. Numerical experiments on synthetic and real text data demonstrate the relevance of the proposed framework and confirm that this method generates meaningful sentences with controllable attribute, e.g. positive or negative sentiment.
Guider l'attention dans les modeles de sequence a sequence pour la prediction des actes de dialogue
Feb 26, 2020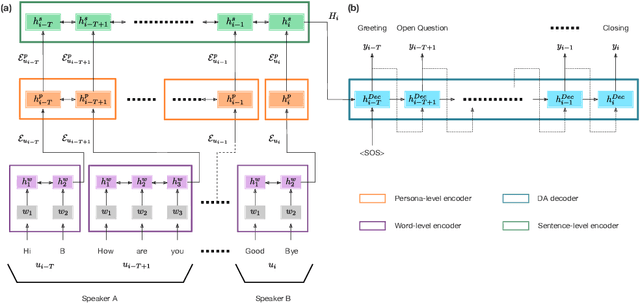
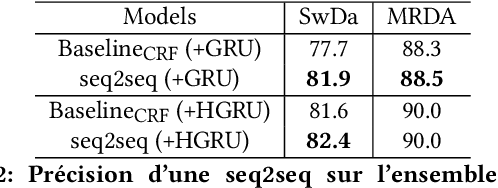
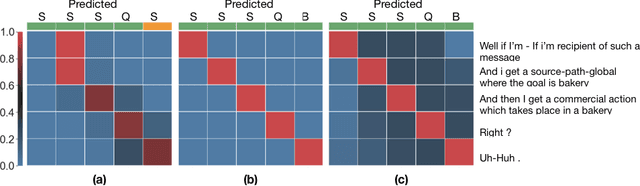

The task of predicting dialog acts (DA) based on conversational dialog is a key component in the development of conversational agents. Accurately predicting DAs requires a precise modeling of both the conversation and the global tag dependencies. We leverage seq2seq approaches widely adopted in Neural Machine Translation (NMT) to improve the modelling of tag sequentiality. Seq2seq models are known to learn complex global dependencies while currently proposed approaches using linear conditional random fields (CRF) only model local tag dependencies. In this work, we introduce a seq2seq model tailored for DA classification using: a hierarchical encoder, a novel guided attention mechanism and beam search applied to both training and inference. Compared to the state of the art our model does not require handcrafted features and is trained end-to-end. Furthermore, the proposed approach achieves an unmatched accuracy score of 85% on SwDA, and state-of-the-art accuracy score of 91.6% on MRDA.
* in French
Guiding attention in Sequence-to-sequence models for Dialogue Act prediction
Feb 26, 2020
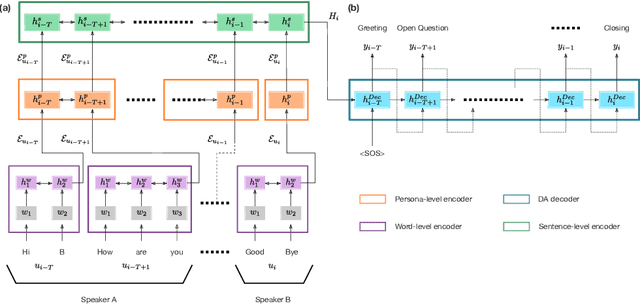
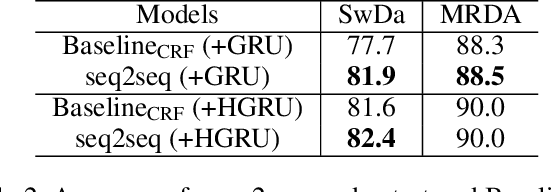

The task of predicting dialog acts (DA) based on conversational dialog is a key component in the development of conversational agents. Accurately predicting DAs requires a precise modeling of both the conversation and the global tag dependencies. We leverage seq2seq approaches widely adopted in Neural Machine Translation (NMT) to improve the modelling of tag sequentiality. Seq2seq models are known to learn complex global dependencies while currently proposed approaches using linear conditional random fields (CRF) only model local tag dependencies. In this work, we introduce a seq2seq model tailored for DA classification using: a hierarchical encoder, a novel guided attention mechanism and beam search applied to both training and inference. Compared to the state of the art our model does not require handcrafted features and is trained end-to-end. Furthermore, the proposed approach achieves an unmatched accuracy score of 85% on SwDA, and state-of-the-art accuracy score of 91.6% on MRDA.