 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHighly Fast Text Segmentation With Pairwise Markov Chains
Paper and Code
Feb 17, 2021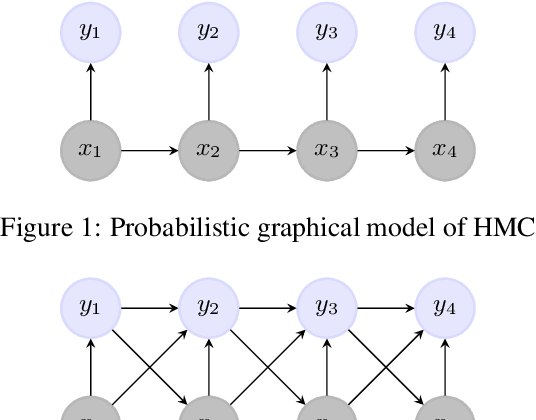
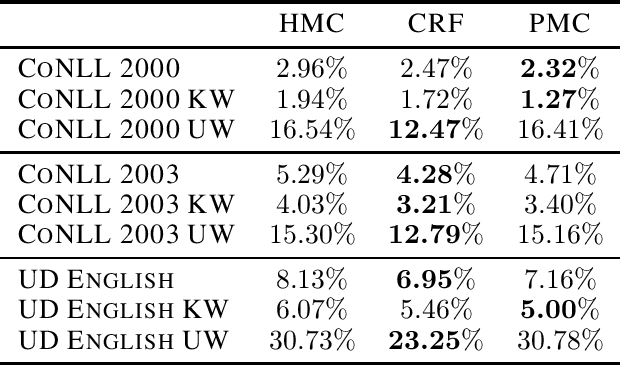
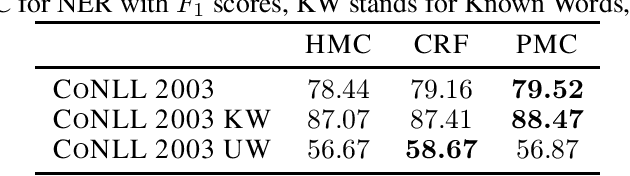
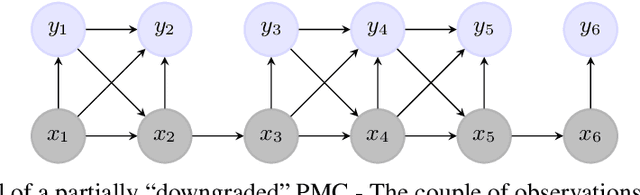
Natural Language Processing (NLP) models' current trend consists of using increasingly more extra-data to build the best models as possible. It implies more expensive computational costs and training time, difficulties for deployment, and worries about these models' carbon footprint reveal a critical problem in the future. Against this trend, our goal is to develop NLP models requiring no extra-data and minimizing training time. To do so, in this paper, we explore Markov chain models, Hidden Markov Chain (HMC) and Pairwise Markov Chain (PMC), for NLP segmentation tasks. We apply these models for three classic applications: POS Tagging, Named-Entity-Recognition, and Chunking. We develop an original method to adapt these models for text segmentation's specific challenges to obtain relevant performances with very short training and execution times. PMC achieves equivalent results to those obtained by Conditional Random Fields (CRF), one of the most applied models for these tasks when no extra-data are used. Moreover, PMC has training times 30 times shorter than the CRF ones, which validates this model given our objectives.