 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHidden Markov Chains, Entropic Forward-Backward, and Part-Of-Speech Tagging
Paper and Code
May 21, 2020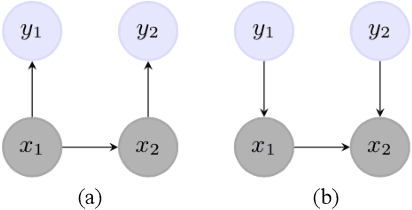
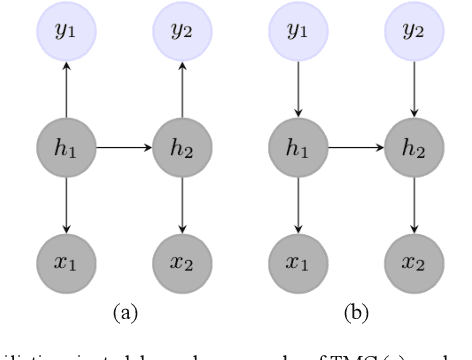
The ability to take into account the characteristics - also called features - of observations is essential in Natural Language Processing (NLP) problems. Hidden Markov Chain (HMC) model associated with classic Forward-Backward probabilities cannot handle arbitrary features like prefixes or suffixes of any size, except with an independence condition. For twenty years, this default has encouraged the development of other sequential models, starting with the Maximum Entropy Markov Model (MEMM), which elegantly integrates arbitrary features. More generally, it led to neglect HMC for NLP. In this paper, we show that the problem is not due to HMC itself, but to the way its restoration algorithms are computed. We present a new way of computing HMC based restorations using original Entropic Forward and Entropic Backward (EFB) probabilities. Our method allows taking into account features in the HMC framework in the same way as in the MEMM framework. We illustrate the efficiency of HMC using EFB in Part-Of-Speech Tagging, showing its superiority over MEMM based restoration. We also specify, as a perspective, how HMCs with EFB might appear as an alternative to Recurrent Neural Networks to treat sequential data with a deep architecture.