 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLOT-V: Supervised Learning of Observer Models for Legible Robot Motion Planning in Manipulation
Oct 04, 2022

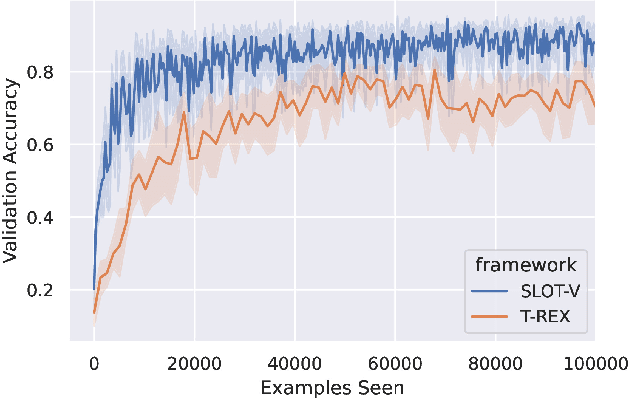
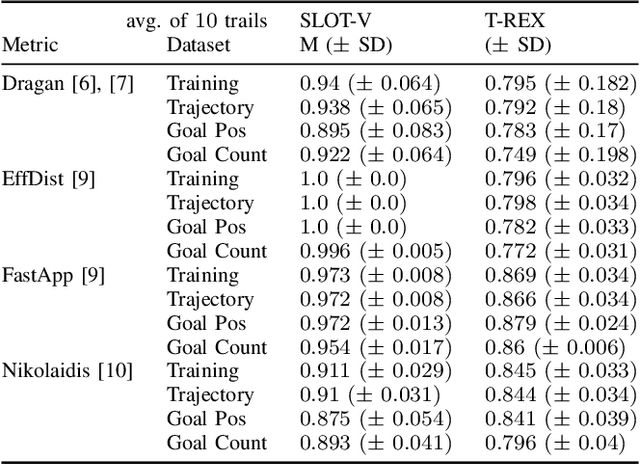
We present SLOT-V, a novel supervised learning framework that learns observer models (human preferences) from robot motion trajectories in a legibility context. Legibility measures how easily a (human) observer can infer the robot's goal from a robot motion trajectory. When generating such trajectories, existing planners often rely on an observer model that estimates the quality of trajectory candidates. These observer models are frequently hand-crafted or, occasionally, learned from demonstrations. Here, we propose to learn them in a supervised manner using the same data format that is frequently used during the evaluation of aforementioned approaches. We then demonstrate the generality of SLOT-V using a Franka Emika in a simulated manipulation environment. For this, we show that it can learn to closely predict various hand-crafted observer models, i.e., that SLOT-V's hypothesis space encompasses existing handcrafted models. Next, we showcase SLOT-V's ability to generalize by showing that a trained model continues to perform well in environments with unseen goal configurations and/or goal counts. Finally, we benchmark SLOT-V's sample efficiency (and performance) against an existing IRL approach and show that SLOT-V learns better observer models with less data. Combined, these results suggest that SLOT-V can learn viable observer models. Better observer models imply more legible trajectories, which may - in turn - lead to better and more transparent human-robot interaction.
A new approach to evaluating legibility: Comparing legibility frameworks using framework-independent robot motion trajectories
Jan 15, 2022
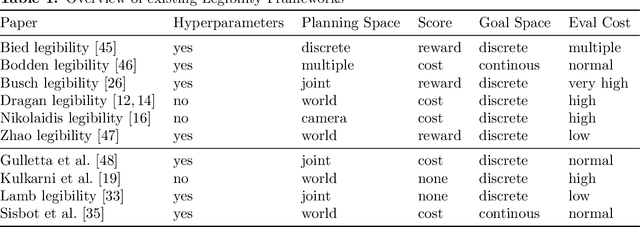


Robots that share an environment with humans may communicate their intent using a variety of different channels. Movement is one of these channels and, particularly in manipulation tasks, intent communication via movement is called legibility. It alters a robot's trajectory to make it intent expressive. Here we propose a novel evaluation method that improves the data efficiency of collected experimental data when benchmarking approaches generating such legible behavior. The primary novelty of the proposed method is that it uses trajectories that were generated independently of the framework being tested. This makes evaluation easier, enables N-way comparisons between approaches, and allows easier comparison across papers. We demonstrate the efficiency of the new evaluation method by comparing 10 legibility frameworks in 2 scenarios. The paper, thus, provides readers with (1) a novel approach to investigate and/or benchmark legibility, (2) an overview of existing frameworks, (3) an evaluation of 10 legibility frameworks (from 6 papers), and (4) evidence that viewing angle and trajectory progression matter when users evaluate the legibility of a motion.
MobiAxis: An Embodied Learning Task for Teaching Multiplication with a Social Robot
Apr 16, 2020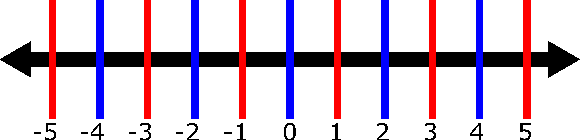

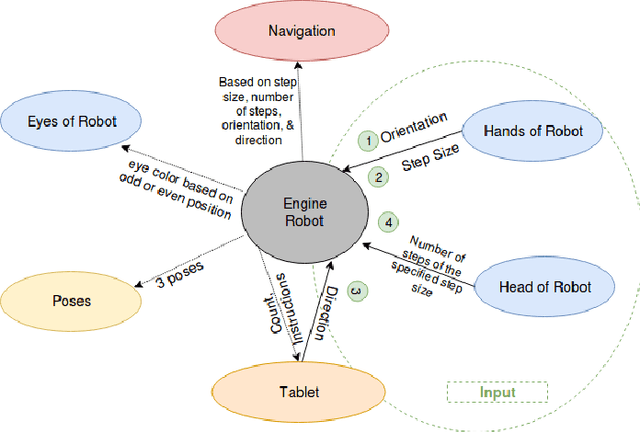

The use of robots in educational settings is growing increasingly popular. Yet, many of the learning tasks involving social robots do not take full advantage of their physical embodiment. MobiAxis is a proposed learning task which uses the physical capabilities of a Pepper robot to teach the concepts of positive and negative multiplication along a number line. The robot is embodied with a number of multi-modal socially intelligent features and behaviours which are designed to enhance learning. This paper is a position paper describing the technical and theoretical implementation of the task, as well as proposed directions for future studies.
A Robot by Any Other Frame: Framing and Behaviour Influence Mind Perception in Virtual but not Real-World Environments
Apr 16, 2020


Mind perception in robots has been an understudied construct in human-robot interaction (HRI) compared to similar concepts such as anthropomorphism and the intentional stance. In a series of three experiments, we identify two factors that could potentially influence mind perception and moral concern in robots: how the robot is introduced (framing), and how the robot acts (social behaviour). In the first two online experiments, we show that both framing and behaviour independently influence participants' mind perception. However, when we combined both variables in the following real-world experiment, these effects failed to replicate. We hence identify a third factor post-hoc: the online versus real-world nature of the interactions. After analysing potential confounds, we tentatively suggest that mind perception is harder to influence in real-world experiments, as manipulations are harder to isolate compared to virtual experiments, which only provide a slice of the interaction.
Explainable Agents Through Social Cues: A Review
Mar 11, 2020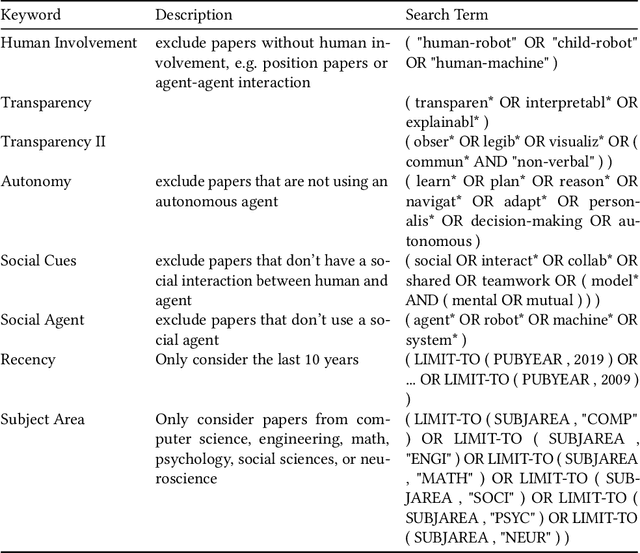
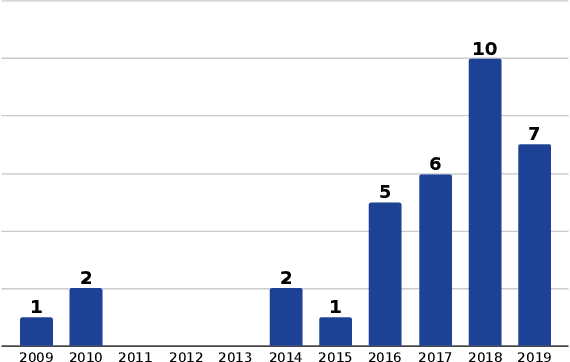

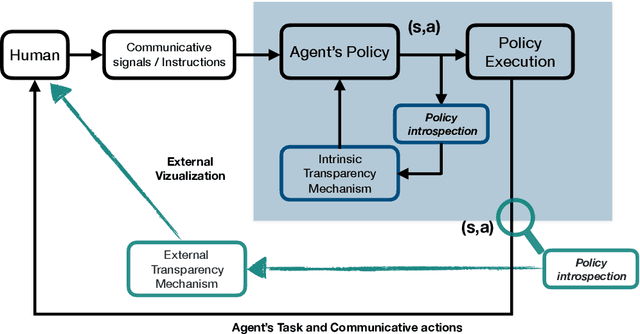
How to provide explanations has experienced a surge of interest in Human-Robot Interaction (HRI) over the last three years. In HRI this is known as explainability, expressivity, transparency or sometimes legibility, and the challenge for embodied agents is that they offer a unique array of modalities to communicate this information thanks to their embodiment. Responding to this surge of interest, we review the existing literature in explainability and organize it by (1) providing an overview of existing definitions, (2) showing how explainability is implemented and how it exploits different modalities, and (3) showing how the impact of explainability is measured. Additionally, we present a list of open questions and challenges that highlight areas that require further investigation by the community. This provides the interested scholar with an overview of the current state-of-the-art.