 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurrent and Future Challenges in Humanoid Robotics -- An Empirical Investigation
Oct 14, 2023
The goal of RoboCup is to make research in the area of robotics measurable over time, and grow a community that works together to solve increasingly difficult challenges over the years. The most ambitious of these challenges it to be able to play against the human world champions in soccer in 2050. To better understand what members of the RoboCup community believes to be the state of the art and the main challenges in the next decade and towards the 2050 game, we developed a survey and distributed it to members of different experience level and background within the community. We present data from 39 responses. Results highlighted that locomotion, awareness and decision-making, and robustness of robots are among those considered of high importance for the community, while human-robot interaction and natural language processing and generation are rated of low in importance and difficulty.
The slurk Interaction Server Framework: Better Data for Better Dialog Models
Feb 02, 2022
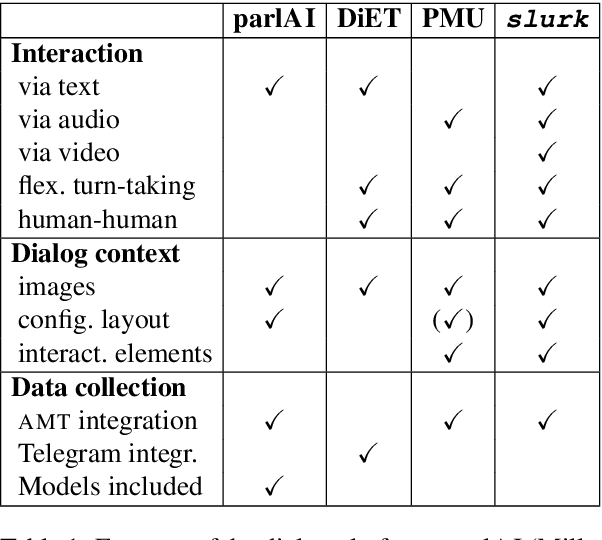
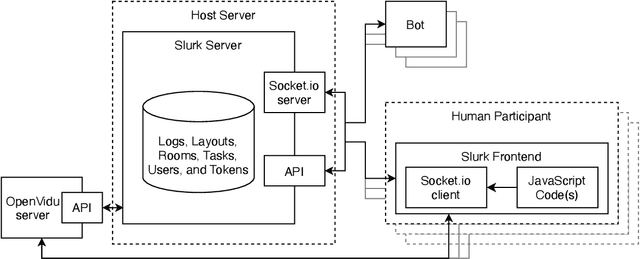
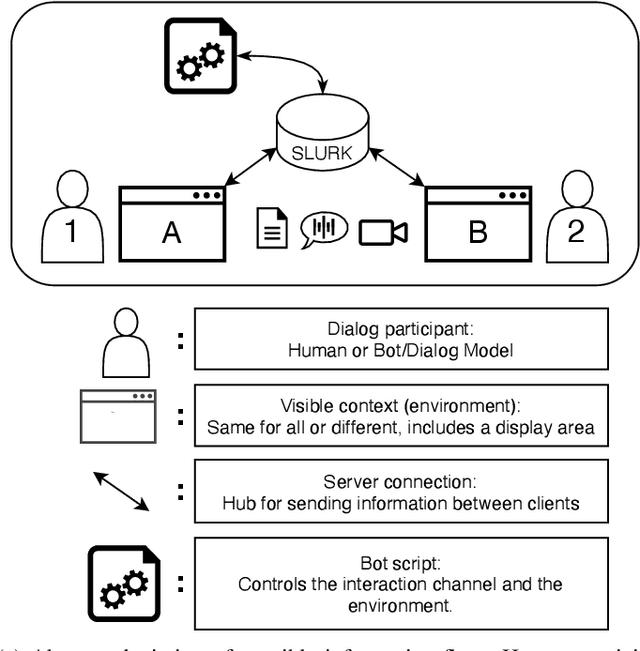
This paper presents the slurk software, a lightweight interaction server for setting up dialog data collections and running experiments. Slurk enables a multitude of settings including text-based, speech and video interaction between two or more humans or humans and bots, and a multimodal display area for presenting shared or private interactive context. The software is implemented in Python with an HTML and JS frontend that can easily be adapted to individual needs. It also provides a setup for pairing participants on common crowdworking platforms such as Amazon Mechanical Turk and some example bot scripts for common interaction scenarios.
Estimating Subjective Crowd-Evaluations as an Additional Objective to Improve Natural Language Generation
Apr 12, 2021
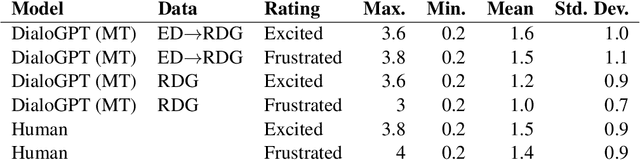

Human ratings are one of the most prevalent methods to evaluate the performance of natural language processing algorithms. Similarly, it is common to measure the quality of sentences generated by a natural language generation model using human raters. In this paper, we argue for exploring the use of subjective evaluations within the process of training language generation models in a multi-task learning setting. As a case study, we use a crowd-authored dialogue corpus to fine-tune six different language generation models. Two of these models incorporate multi-task learning and use subjective ratings of lines as part of an explicit learning goal. A human evaluation of the generated dialogue lines reveals that utterances generated by the multi-tasking models were subjectively rated as the most typical, most moving the conversation forward, and least offensive. Based on these promising first results, we discuss future research directions for incorporating subjective human evaluations into language model training and to hence keep the human user in the loop during the development process.
I Can See it in Your Eyes: Gaze towards a Robot as an Implicit Cue of Uncanniness and Task Performance in Long-term Interactions
Jan 13, 2021
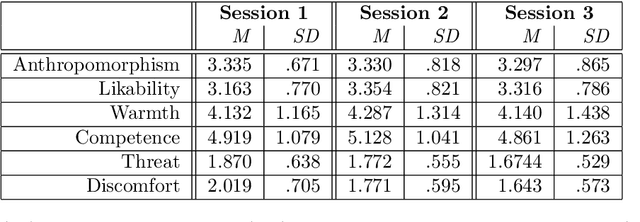
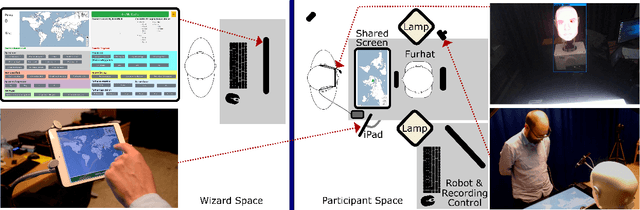
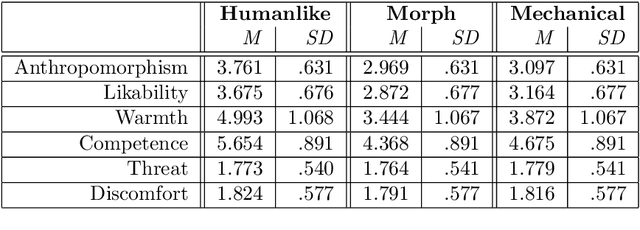
Over the past years, extensive research has been dedicated to developing robust platforms and data-driven dialogue models to support long-term human-robot interactions. However, little is known about how people's perception of robots and engagement with them develop over time and how these can be accurately assessed through implicit and continuous measurement techniques. In this paper, we investigate this by involving participants in three interaction sessions with multiple days of zero exposure in between. Each session consists of a joint task with a robot as well as two short social chats with it before and after the task. We measure participants' gaze patterns with a wearable eye-tracker and gauge their perception of the robot and engagement with it and the joint task using questionnaires. Results disclose that aversion of gaze in a social chat is an indicator of a robot's uncanniness and that the more people gaze at the robot in a joint task, the worse they perform. In contrast with most HRI literature, our results show that gaze towards an object of shared attention, rather than gaze towards a robotic partner, is the most meaningful predictor of engagement in a joint task. Furthermore, the analyses of long-term gaze patterns disclose that people's mutual gaze in a social chat develops congruently with their perceptions of the robot over time. These are key findings for the HRI community as they entail that gaze behavior can be used as an implicit measure of people's perception of robots in a social chat and of their engagement and task performance in a joint task.