 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVejde: A Framework for Inductive Deep Reinforcement Learning Based on Factor Graph Color Refinement
Sep 11, 2025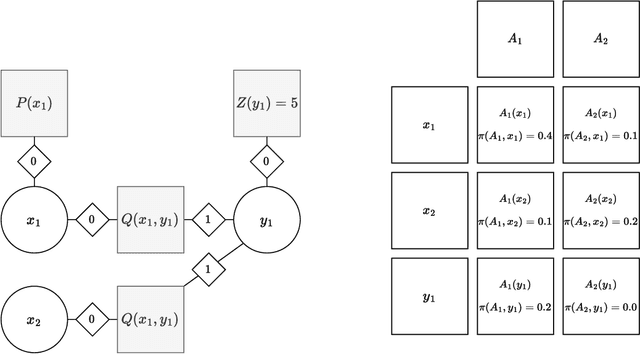
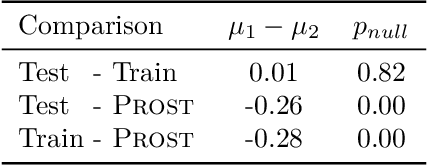
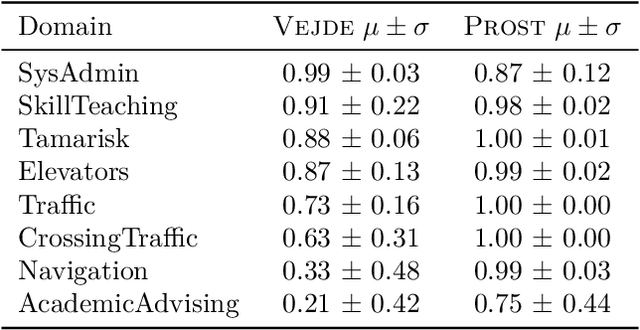
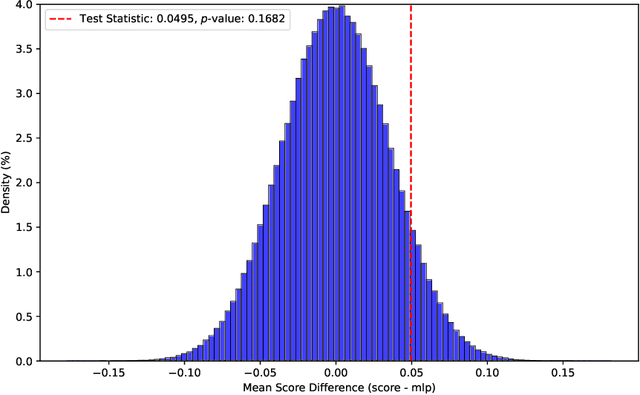
We present and evaluate Vejde; a framework which combines data abstraction, graph neural networks and reinforcement learning to produce inductive policy functions for decision problems with richly structured states, such as object classes and relations. MDP states are represented as data bases of facts about entities, and Vejde converts each state to a bipartite graph, which is mapped to latent states through neural message passing. The factored representation of both states and actions allows Vejde agents to handle problems of varying size and structure. We tested Vejde agents on eight problem domains defined in RDDL, with ten problem instances each, where policies were trained using both supervised and reinforcement learning. To test policy generalization, we separate problem instances in two sets, one for training and the other solely for testing. Test results on unseen instances for the Vejde agents were compared to MLP agents trained on each problem instance, as well as the online planning algorithm Prost. Our results show that Vejde policies in average generalize to the test instances without a significant loss in score. Additionally, the inductive agents received scores on unseen test instances that on average were close to the instance-specific MLP agents.
Structural Generalization in Autonomous Cyber Incident Response with Message-Passing Neural Networks and Reinforcement Learning
Jul 08, 2024



We believe that agents for automated incident response based on machine learning need to handle changes in network structure. Computer networks are dynamic, and can naturally change in structure over time. Retraining agents for small network changes costs time and energy. We attempt to address this issue with an existing method of relational agent learning, where the relations between objects are assumed to remain consistent across problem instances. The state of the computer network is represented as a relational graph and encoded through a message passing neural network. The message passing neural network and an agent policy using the encoding are optimized end-to-end using reinforcement learning. We evaluate the approach on the second instance of the Cyber Autonomy Gym for Experimentation (CAGE~2), a cyber incident simulator that simulates attacks on an enterprise network. We create variants of the original network with different numbers of hosts and agents are tested without additional training on them. Our results show that agents using relational information are able to find solutions despite changes to the network, and can perform optimally in some instances. Agents using the default vector state representation perform better, but need to be specially trained on each network variant, demonstrating a trade-off between specialization and generalization.
Training Automated Defense Strategies Using Graph-based Cyber Attack Simulations
Apr 17, 2023


We implemented and evaluated an automated cyber defense agent. The agent takes security alerts as input and uses reinforcement learning to learn a policy for executing predefined defensive measures. The defender policies were trained in an environment intended to simulate a cyber attack. In the simulation, an attacking agent attempts to capture targets in the environment, while the defender attempts to protect them by enabling defenses. The environment was modeled using attack graphs based on the Meta Attack Language language. We assumed that defensive measures have downtime costs, meaning that the defender agent was penalized for using them. We also assumed that the environment was equipped with an imperfect intrusion detection system that occasionally produces erroneous alerts based on the environment state. To evaluate the setup, we trained the defensive agent with different volumes of intrusion detection system noise. We also trained agents with different attacker strategies and graph sizes. In experiments, the defensive agent using policies trained with reinforcement learning outperformed agents using heuristic policies. Experiments also demonstrated that the policies could generalize across different attacker strategies. However, the performance of the learned policies decreased as the attack graphs increased in size.
Estimating Subjective Crowd-Evaluations as an Additional Objective to Improve Natural Language Generation
Apr 12, 2021
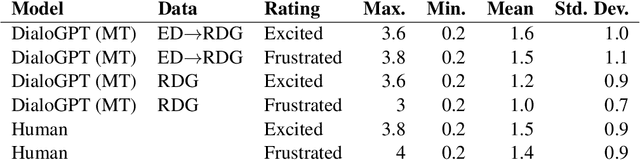

Human ratings are one of the most prevalent methods to evaluate the performance of natural language processing algorithms. Similarly, it is common to measure the quality of sentences generated by a natural language generation model using human raters. In this paper, we argue for exploring the use of subjective evaluations within the process of training language generation models in a multi-task learning setting. As a case study, we use a crowd-authored dialogue corpus to fine-tune six different language generation models. Two of these models incorporate multi-task learning and use subjective ratings of lines as part of an explicit learning goal. A human evaluation of the generated dialogue lines reveals that utterances generated by the multi-tasking models were subjectively rated as the most typical, most moving the conversation forward, and least offensive. Based on these promising first results, we discuss future research directions for incorporating subjective human evaluations into language model training and to hence keep the human user in the loop during the development process.