 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMechanical Chameleons: Evaluating the effects of a social robot's non-verbal behavior on social influence
Sep 02, 2021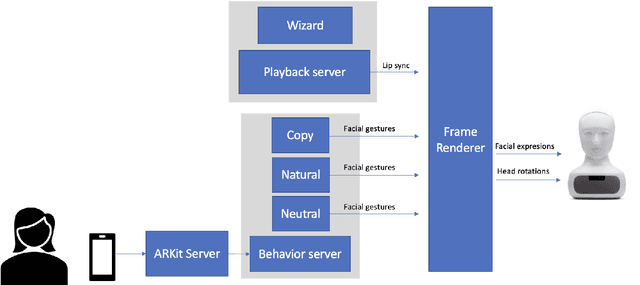

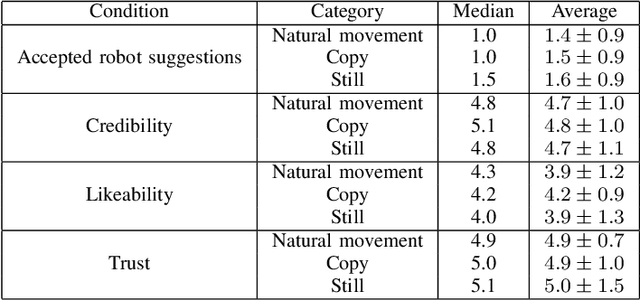
In this paper we present a pilot study which investigates how non-verbal behavior affects social influence in social robots. We also present a modular system which is capable of controlling the non-verbal behavior based on the interlocutor's facial gestures (head movements and facial expressions) in real time, and a study investigating whether three different strategies for facial gestures ("still", "natural movement", i.e. movements recorded from another conversation, and "copy", i.e. mimicking the user with a four second delay) has any affect on social influence and decision making in a "survival task". Our preliminary results show there was no significant difference between the three conditions, but this might be due to among other things a low number of study participants (12).
Speech2Properties2Gestures: Gesture-Property Prediction as a Tool for Generating Representational Gestures from Speech
Jun 28, 2021
We propose a new framework for gesture generation, aiming to allow data-driven approaches to produce more semantically rich gestures. Our approach first predicts whether to gesture, followed by a prediction of the gesture properties. Those properties are then used as conditioning for a modern probabilistic gesture-generation model capable of high-quality output. This empowers the approach to generate gestures that are both diverse and representational.
Let's face it: Probabilistic multi-modal interlocutor-aware generation of facial gestures in dyadic settings
Jun 11, 2020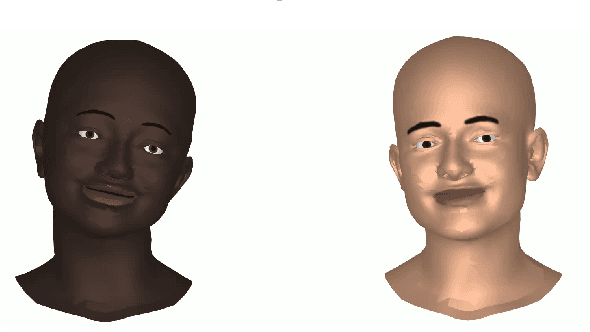
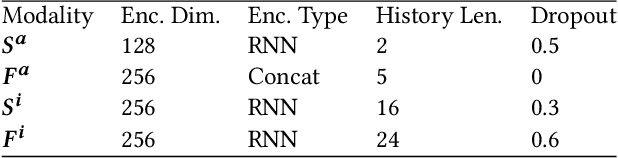
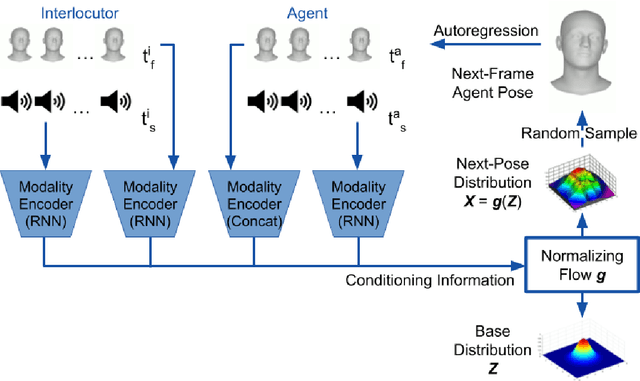

To enable more natural face-to-face interactions, conversational agents need to adapt their behavior to their interlocutors. One key aspect of this is generation of appropriate non-verbal behavior for the agent, for example facial gestures, here defined as facial expressions and head movements. Most existing gesture-generating systems do not utilize multi-modal cues from the interlocutor when synthesizing non-verbal behavior. Those that do, typically use deterministic methods that risk producing repetitive and non-vivid motions. In this paper, we introduce a probabilistic method to synthesize interlocutor-aware facial gestures - represented by highly expressive FLAME parameters - in dyadic conversations. Our contributions are: a) a method for feature extraction from multi-party video and speech recordings, resulting in a representation that allows for independent control and manipulation of expression and speech articulation in a 3D avatar; b) an extension to MoGlow, a recent motion-synthesis method based on normalizing flows, to also take multi-modal signals from the interlocutor as input and subsequently output interlocutor-aware facial gestures; and c) subjective and objective experiments assessing the use and relative importance of the different modalities in the synthesized output. The results show that the model successfully leverages the input from the interlocutor to generate more appropriate behavior.
Gesticulator: A framework for semantically-aware speech-driven gesture generation
Jan 25, 2020
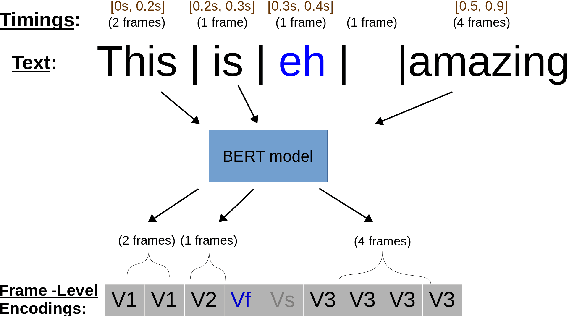

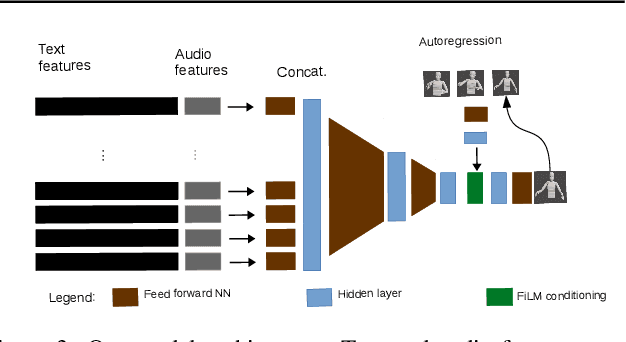
During speech, people spontaneously gesticulate, which plays a key role in conveying information. Similarly, realistic co-speech gestures are crucial to enable natural and smooth interactions with social agents. Current data-driven co-speech gesture generation systems use a single modality for representing speech: either audio or text. These systems are therefore confined to producing either acoustically-linked beat gestures or semantically-linked gesticulation (e.g., raising a hand when saying ``high''): they cannot appropriately learn to generate both gesture types. We present a model designed to produce arbitrary beat and semantic gestures together. Our deep-learning based model takes both acoustic and semantic representations of speech as input, and generates gestures as a sequence of joint angle rotations as output. The resulting gestures can be applied to both virtual agents and humanoid robots. We illustrate the model's efficacy with subjective and objective evaluations.
Machine Learning and Social Robotics for Detecting Early Signs of Dementia
Sep 05, 2017
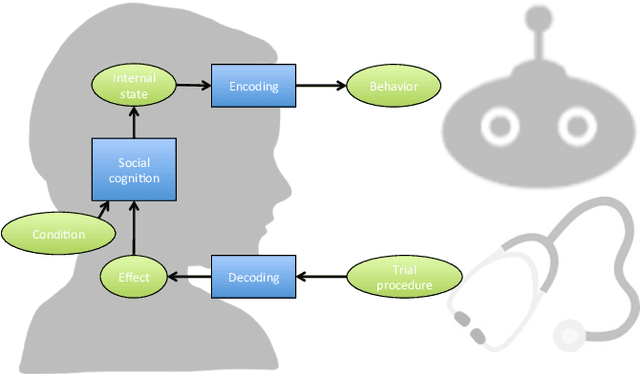
This paper presents the EACare project, an ambitious multi-disciplinary collaboration with the aim to develop an embodied system, capable of carrying out neuropsychological tests to detect early signs of dementia, e.g., due to Alzheimer's disease. The system will use methods from Machine Learning and Social Robotics, and be trained with examples of recorded clinician-patient interactions. The interaction will be developed using a participatory design approach. We describe the scope and method of the project, and report on a first Wizard of Oz prototype.