 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLook and Tell: A Dataset for Multimodal Grounding Across Egocentric and Exocentric Views
Oct 26, 2025



We introduce Look and Tell, a multimodal dataset for studying referential communication across egocentric and exocentric perspectives. Using Meta Project Aria smart glasses and stationary cameras, we recorded synchronized gaze, speech, and video as 25 participants instructed a partner to identify ingredients in a kitchen. Combined with 3D scene reconstructions, this setup provides a benchmark for evaluating how different spatial representations (2D vs. 3D; ego vs. exo) affect multimodal grounding. The dataset contains 3.67 hours of recordings, including 2,707 richly annotated referential expressions, and is designed to advance the development of embodied agents that can understand and engage in situated dialogue.
Gesture Evaluation in Virtual Reality
Sep 16, 2025Gestures are central to human communication, enriching interactions through non-verbal expression. Virtual avatars increasingly use AI-generated gestures to enhance life-likeness, yet evaluations have largely been confined to 2D. Virtual Reality (VR) provides an immersive alternative that may affect how gestures are perceived. This paper presents a comparative evaluation of computer-generated gestures in VR and 2D, examining three models from the 2023 GENEA Challenge. Results show that gestures viewed in VR were rated slightly higher on average, with the strongest effect observed for motion-capture "true movement." While model rankings remained consistent across settings, VR influenced participants' overall perception and offered unique benefits over traditional 2D evaluation.
* Published in Proceedings of the 26th International Conference on Multimodal Interaction (ICMI '24), ACM. Copyright 2024 ACM. Licensed under CC BY
Towards Context-Aware Human-like Pointing Gestures with RL Motion Imitation
Sep 16, 2025Pointing is a key mode of interaction with robots, yet most prior work has focused on recognition rather than generation. We present a motion capture dataset of human pointing gestures covering diverse styles, handedness, and spatial targets. Using reinforcement learning with motion imitation, we train policies that reproduce human-like pointing while maximizing precision. Results show our approach enables context-aware pointing behaviors in simulation, balancing task performance with natural dynamics.
Learning to Generate Pointing Gestures in Situated Embodied Conversational Agents
Sep 15, 2025One of the main goals of robotics and intelligent agent research is to enable natural communication with humans in physically situated settings. While recent work has focused on verbal modes such as language and speech, non-verbal communication is crucial for flexible interaction. We present a framework for generating pointing gestures in embodied agents by combining imitation and reinforcement learning. Using a small motion capture dataset, our method learns a motor control policy that produces physically valid, naturalistic gestures with high referential accuracy. We evaluate the approach against supervised learning and retrieval baselines in both objective metrics and a virtual reality referential game with human users. Results show that our system achieves higher naturalness and accuracy than state-of-the-art supervised models, highlighting the promise of imitation-RL for communicative gesture generation and its potential application to robots.
* DOI: 10.3389/frobt.2023.1110534. This is the author's LaTeX version
Incorporating Spatial Awareness in Data-Driven Gesture Generation for Virtual Agents
Aug 07, 2024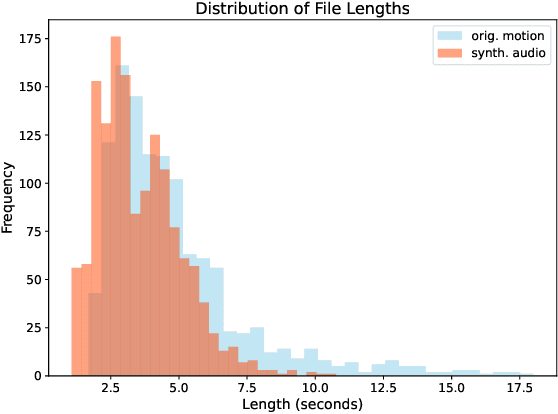
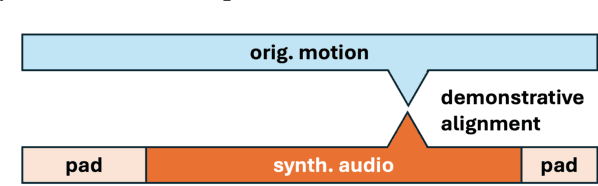
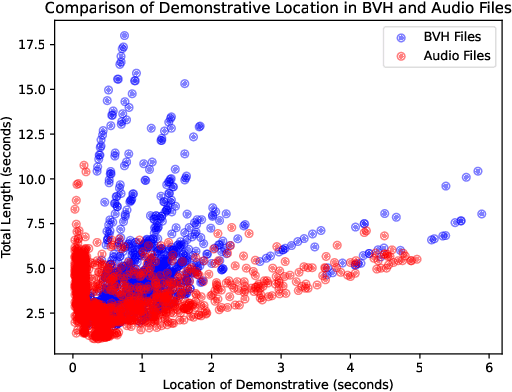

This paper focuses on enhancing human-agent communication by integrating spatial context into virtual agents' non-verbal behaviors, specifically gestures. Recent advances in co-speech gesture generation have primarily utilized data-driven methods, which create natural motion but limit the scope of gestures to those performed in a void. Our work aims to extend these methods by enabling generative models to incorporate scene information into speech-driven gesture synthesis. We introduce a novel synthetic gesture dataset tailored for this purpose. This development represents a critical step toward creating embodied conversational agents that interact more naturally with their environment and users.
Fake it to make it: Using synthetic data to remedy the data shortage in joint multimodal speech-and-gesture synthesis
Apr 30, 2024Although humans engaged in face-to-face conversation simultaneously communicate both verbally and non-verbally, methods for joint and unified synthesis of speech audio and co-speech 3D gesture motion from text are a new and emerging field. These technologies hold great promise for more human-like, efficient, expressive, and robust synthetic communication, but are currently held back by the lack of suitably large datasets, as existing methods are trained on parallel data from all constituent modalities. Inspired by student-teacher methods, we propose a straightforward solution to the data shortage, by simply synthesising additional training material. Specifically, we use unimodal synthesis models trained on large datasets to create multimodal (but synthetic) parallel training data, and then pre-train a joint synthesis model on that material. In addition, we propose a new synthesis architecture that adds better and more controllable prosody modelling to the state-of-the-art method in the field. Our results confirm that pre-training on large amounts of synthetic data improves the quality of both the speech and the motion synthesised by the multimodal model, with the proposed architecture yielding further benefits when pre-trained on the synthetic data. See https://shivammehta25.github.io/MAGI/ for example output.
Diffusion-Based Co-Speech Gesture Generation Using Joint Text and Audio Representation
Sep 11, 2023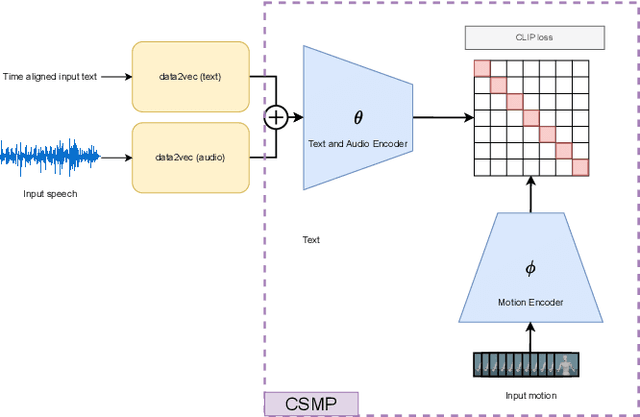
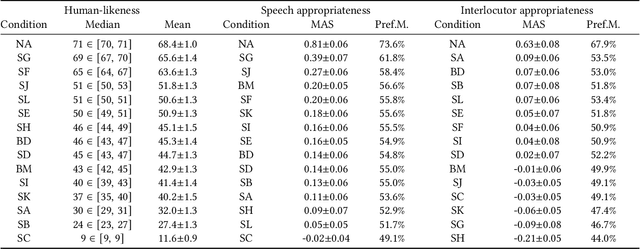
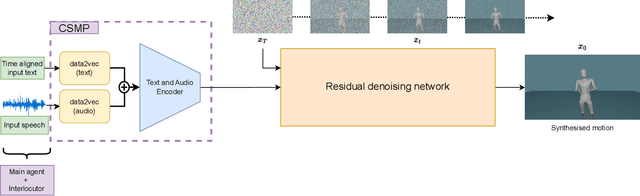
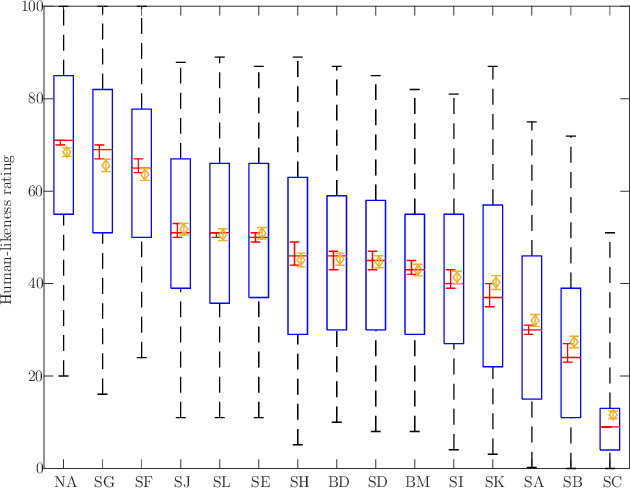
This paper describes a system developed for the GENEA (Generation and Evaluation of Non-verbal Behaviour for Embodied Agents) Challenge 2023. Our solution builds on an existing diffusion-based motion synthesis model. We propose a contrastive speech and motion pretraining (CSMP) module, which learns a joint embedding for speech and gesture with the aim to learn a semantic coupling between these modalities. The output of the CSMP module is used as a conditioning signal in the diffusion-based gesture synthesis model in order to achieve semantically-aware co-speech gesture generation. Our entry achieved highest human-likeness and highest speech appropriateness rating among the submitted entries. This indicates that our system is a promising approach to achieve human-like co-speech gestures in agents that carry semantic meaning.
Mechanical Chameleons: Evaluating the effects of a social robot's non-verbal behavior on social influence
Sep 02, 2021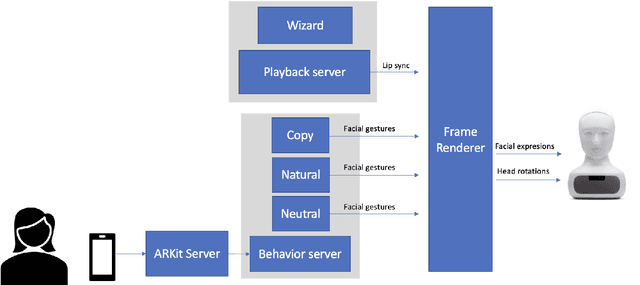

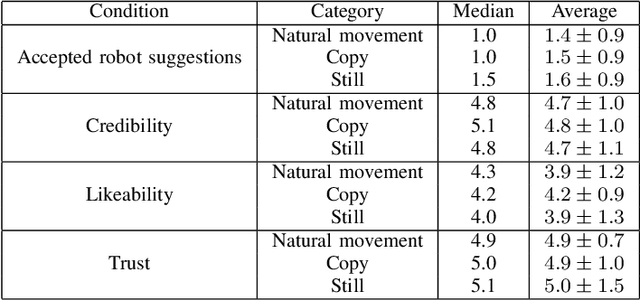
In this paper we present a pilot study which investigates how non-verbal behavior affects social influence in social robots. We also present a modular system which is capable of controlling the non-verbal behavior based on the interlocutor's facial gestures (head movements and facial expressions) in real time, and a study investigating whether three different strategies for facial gestures ("still", "natural movement", i.e. movements recorded from another conversation, and "copy", i.e. mimicking the user with a four second delay) has any affect on social influence and decision making in a "survival task". Our preliminary results show there was no significant difference between the three conditions, but this might be due to among other things a low number of study participants (12).
Think Too Fast Nor Too Slow: The Computational Trade-off Between Planning And Reinforcement Learning
May 15, 2020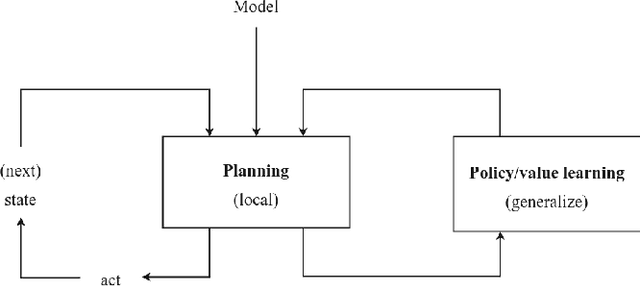

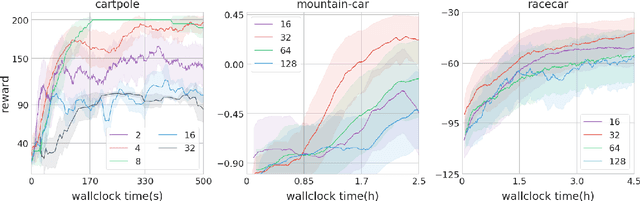
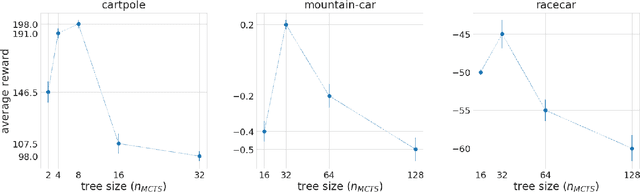
Planning and reinforcement learning are two key approaches to sequential decision making. Multi-step approximate real-time dynamic programming, a recently successful algorithm class of which AlphaZero [Silver et al., 2018] is an example, combines both by nesting planning within a learning loop. However, the combination of planning and learning introduces a new question: how should we balance time spend on planning, learning and acting? The importance of this trade-off has not been explicitly studied before. We show that it is actually of key importance, with computational results indicating that we should neither plan too long nor too short. Conceptually, we identify a new spectrum of planning-learning algorithms which ranges from exhaustive search (long planning) to model-free RL (no planning), with optimal performance achieved midway.