Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncorporating Spatial Awareness in Data-Driven Gesture Generation for Virtual Agents
Paper and Code
Aug 07, 2024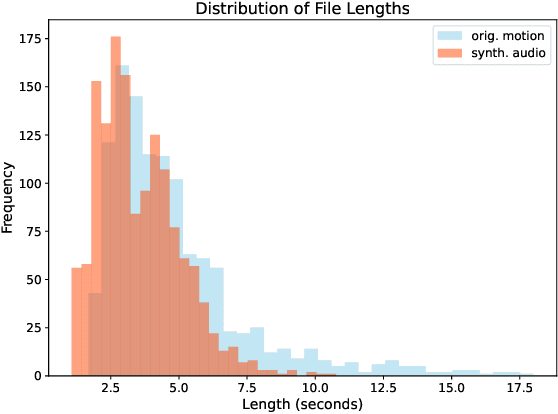
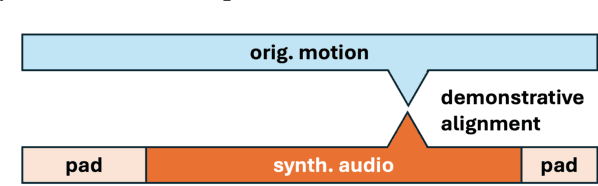
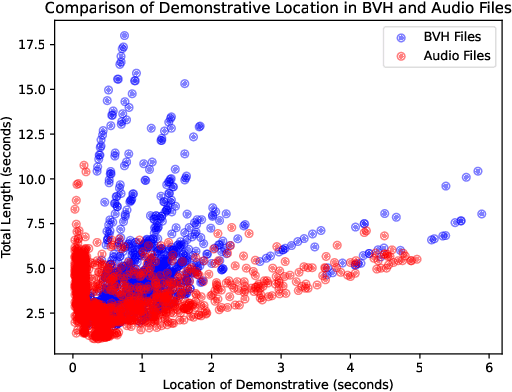

This paper focuses on enhancing human-agent communication by integrating spatial context into virtual agents' non-verbal behaviors, specifically gestures. Recent advances in co-speech gesture generation have primarily utilized data-driven methods, which create natural motion but limit the scope of gestures to those performed in a void. Our work aims to extend these methods by enabling generative models to incorporate scene information into speech-driven gesture synthesis. We introduce a novel synthetic gesture dataset tailored for this purpose. This development represents a critical step toward creating embodied conversational agents that interact more naturally with their environment and users.
View paper on