 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGesticulator: A framework for semantically-aware speech-driven gesture generation
Paper and Code
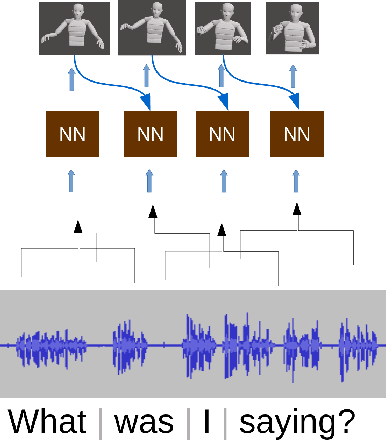
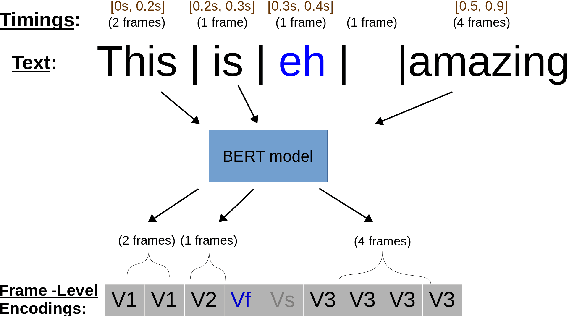

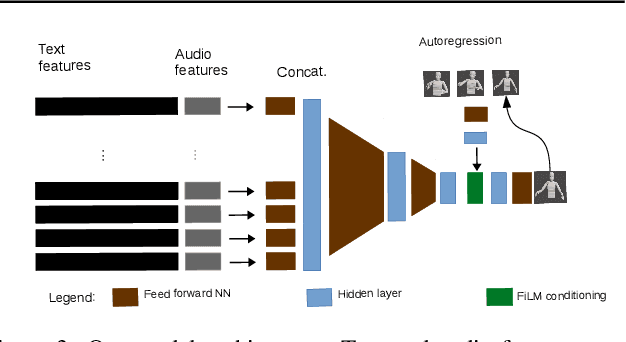
During speech, people spontaneously gesticulate, which plays a key role in conveying information. Similarly, realistic co-speech gestures are crucial to enable natural and smooth interactions with social agents. Current data-driven co-speech gesture generation systems use a single modality for representing speech: either audio or text. These systems are therefore confined to producing either acoustically-linked beat gestures or semantically-linked gesticulation (e.g., raising a hand when saying ``high''): they cannot appropriately learn to generate both gesture types. We present a model designed to produce arbitrary beat and semantic gestures together. Our deep-learning based model takes both acoustic and semantic representations of speech as input, and generates gestures as a sequence of joint angle rotations as output. The resulting gestures can be applied to both virtual agents and humanoid robots. We illustrate the model's efficacy with subjective and objective evaluations.