 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePartner Modelling Emerges in Recurrent Agents (But Only When It Matters)
May 22, 2025Humans are remarkably adept at collaboration, able to infer the strengths and weaknesses of new partners in order to work successfully towards shared goals. To build AI systems with this capability, we must first understand its building blocks: does such flexibility require explicit, dedicated mechanisms for modelling others -- or can it emerge spontaneously from the pressures of open-ended cooperative interaction? To investigate this question, we train simple model-free RNN agents to collaborate with a population of diverse partners. Using the `Overcooked-AI' environment, we collect data from thousands of collaborative teams, and analyse agents' internal hidden states. Despite a lack of additional architectural features, inductive biases, or auxiliary objectives, the agents nevertheless develop structured internal representations of their partners' task abilities, enabling rapid adaptation and generalisation to novel collaborators. We investigated these internal models through probing techniques, and large-scale behavioural analysis. Notably, we find that structured partner modelling emerges when agents can influence partner behaviour by controlling task allocation. Our results show that partner modelling can arise spontaneously in model-free agents -- but only under environmental conditions that impose the right kind of social pressure.
Emergent kin selection of altruistic feeding via non-episodic neuroevolution
Nov 15, 2024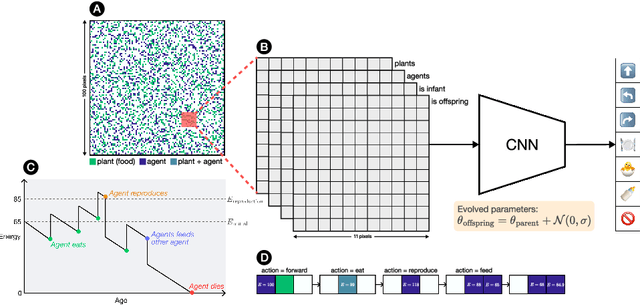

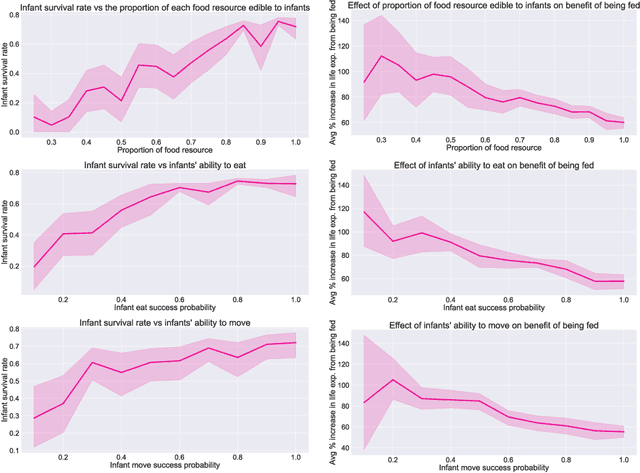
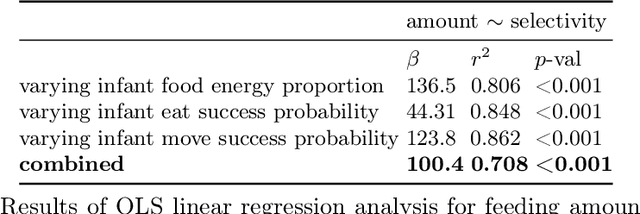
Kin selection theory has proven to be a popular and widely accepted account of how altruistic behaviour can evolve under natural selection. Hamilton's rule, first published in 1964, has since been experimentally validated across a range of different species and social behaviours. In contrast to this large body of work in natural populations, however, there has been relatively little study of kin selection \emph{in silico}. In the current work, we offer what is to our knowledge the first demonstration of kin selection emerging naturally within a population of agents undergoing continuous neuroevolution. Specifically, we find that zero-sum transfer of resources from parents to their infant offspring evolves through kin selection in environments where it is hard for offspring to survive alone. In an additional experiment, we show that kin selection in our simulations relies on a combination of kin recognition and population viscosity. We believe that our work may contribute to the understanding of kin selection in minimal evolutionary systems, without explicit notions of genes and fitness maximisation.
Is Feedback All You Need? Leveraging Natural Language Feedback in Goal-Conditioned Reinforcement Learning
Dec 07, 2023Despite numerous successes, the field of reinforcement learning (RL) remains far from matching the impressive generalisation power of human behaviour learning. One possible way to help bridge this gap be to provide RL agents with richer, more human-like feedback expressed in natural language. To investigate this idea, we first extend BabyAI to automatically generate language feedback from the environment dynamics and goal condition success. Then, we modify the Decision Transformer architecture to take advantage of this additional signal. We find that training with language feedback either in place of or in addition to the return-to-go or goal descriptions improves agents' generalisation performance, and that agents can benefit from feedback even when this is only available during training, but not at inference.
Balancing utility and cognitive cost in social representation
Oct 07, 2023


To successfully navigate its environment, an agent must construct and maintain representations of the other agents that it encounters. Such representations are useful for many tasks, but they are not without cost. As a result, agents must make decisions regarding how much information they choose to represent about the agents in their environment. Using selective imitation as an example task, we motivate the problem of finding agent representations that optimally trade off between downstream utility and information cost, and illustrate two example approaches to resource-constrained social representation.
Selective imitation on the basis of reward function similarity
May 12, 2023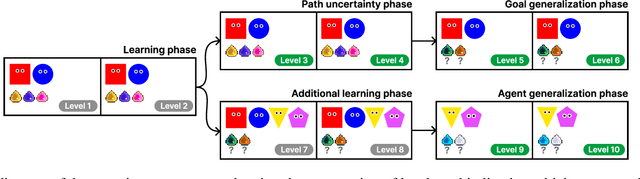


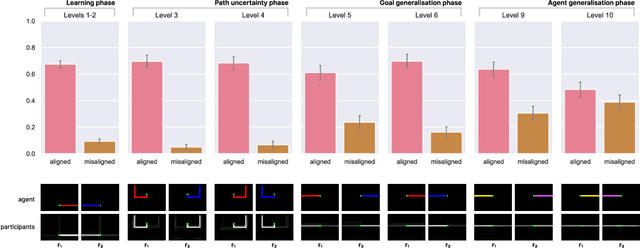
Imitation is a key component of human social behavior, and is widely used by both children and adults as a way to navigate uncertain or unfamiliar situations. But in an environment populated by multiple heterogeneous agents pursuing different goals or objectives, indiscriminate imitation is unlikely to be an effective strategy -- the imitator must instead determine who is most useful to copy. There are likely many factors that play into these judgements, depending on context and availability of information. Here we investigate the hypothesis that these decisions involve inferences about other agents' reward functions. We suggest that people preferentially imitate the behavior of others they deem to have similar reward functions to their own. We further argue that these inferences can be made on the basis of very sparse or indirect data, by leveraging an inductive bias toward positing the existence of different \textit{groups} or \textit{types} of people with similar reward functions, allowing learners to select imitation targets without direct evidence of alignment.