 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePeople Attribute Purpose to Autonomous Vehicles When Explaining Their Behavior
Mar 11, 2024

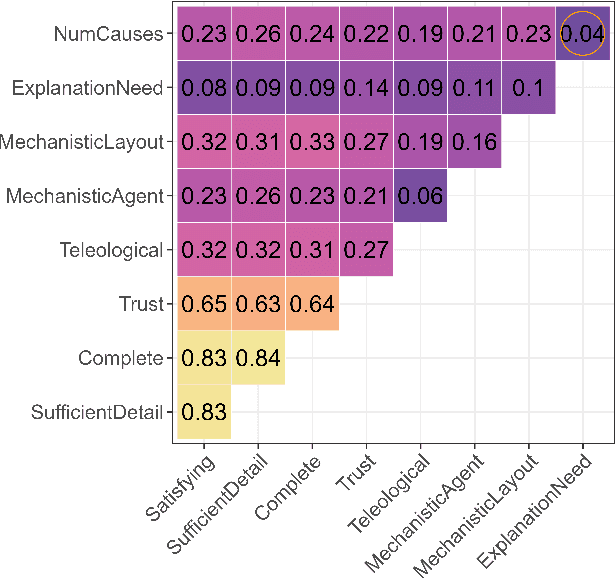
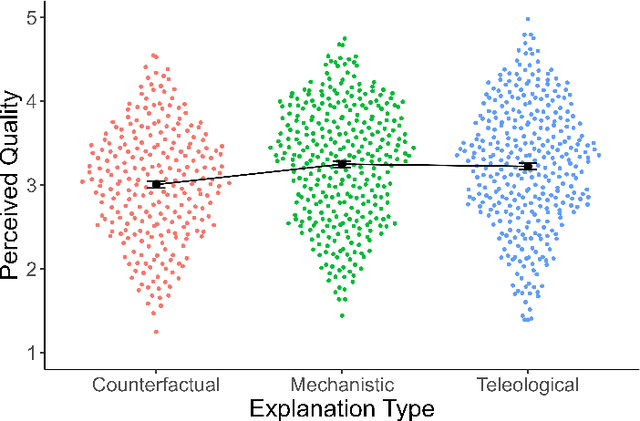
A hallmark of a good XAI system is explanations that users can understand and act on. In many cases, this requires a system to offer causal or counterfactual explanations that are intelligible. Cognitive science can help us understand what kinds of explanations users might expect, and in which format to frame these explanations. We briefly review relevant literature from the cognitive science of explanation, particularly as it concerns teleology, the tendency to explain a decision in terms of the purpose it was meant to achieve. We then report empirical data on how people generate explanations for the behavior of autonomous vehicles, and how they evaluate these explanations. In a first survey, participants (n=54) were shown videos of a road scene and asked to generate either mechanistic, counterfactual, or teleological verbal explanations for a vehicle's actions. In the second survey, a different set of participants (n=356) rated these explanations along various metrics including quality, trustworthiness, and how much each explanatory mode was emphasized in the explanation. Participants deemed mechanistic and teleological explanations as significantly higher quality than counterfactual explanations. In addition, perceived teleology was the best predictor of perceived quality and trustworthiness. Neither perceived teleology nor quality ratings were affected by whether the car whose actions were being explained was an autonomous vehicle or was being driven by a person. The results show people use and value teleological concepts to evaluate information about both other people and autonomous vehicles, indicating they find the 'intentional stance' a convenient abstraction. We make our dataset of annotated video situations with explanations, called Human Explanations for Autonomous Driving Decisions (HEADD), publicly available, which we hope will prompt further research.
Selective imitation on the basis of reward function similarity
May 12, 2023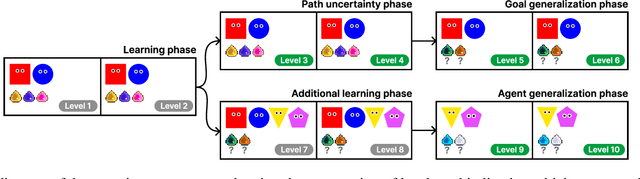


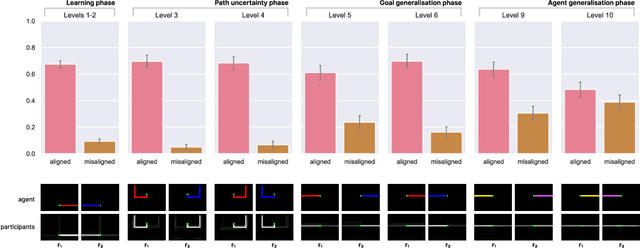
Imitation is a key component of human social behavior, and is widely used by both children and adults as a way to navigate uncertain or unfamiliar situations. But in an environment populated by multiple heterogeneous agents pursuing different goals or objectives, indiscriminate imitation is unlikely to be an effective strategy -- the imitator must instead determine who is most useful to copy. There are likely many factors that play into these judgements, depending on context and availability of information. Here we investigate the hypothesis that these decisions involve inferences about other agents' reward functions. We suggest that people preferentially imitate the behavior of others they deem to have similar reward functions to their own. We further argue that these inferences can be made on the basis of very sparse or indirect data, by leveraging an inductive bias toward positing the existence of different \textit{groups} or \textit{types} of people with similar reward functions, allowing learners to select imitation targets without direct evidence of alignment.