 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAvatarPointillist: AutoRegressive 4D Gaussian Avatarization
Apr 06, 2026We introduce AvatarPointillist, a novel framework for generating dynamic 4D Gaussian avatars from a single portrait image. At the core of our method is a decoder-only Transformer that autoregressively generates a point cloud for 3D Gaussian Splatting. This sequential approach allows for precise, adaptive construction, dynamically adjusting point density and the total number of points based on the subject's complexity. During point generation, the AR model also jointly predicts per-point binding information, enabling realistic animation. After generation, a dedicated Gaussian decoder converts the points into complete, renderable Gaussian attributes. We demonstrate that conditioning the decoder on the latent features from the AR generator enables effective interaction between stages and markedly improves fidelity. Extensive experiments validate that AvatarPointillist produces high-quality, photorealistic, and controllable avatars. We believe this autoregressive formulation represents a new paradigm for avatar generation, and we will release our code inspire future research.
UIKA: Fast Universal Head Avatar from Pose-Free Images
Jan 12, 2026We present UIKA, a feed-forward animatable Gaussian head model from an arbitrary number of unposed inputs, including a single image, multi-view captures, and smartphone-captured videos. Unlike the traditional avatar method, which requires a studio-level multi-view capture system and reconstructs a human-specific model through a long-time optimization process, we rethink the task through the lenses of model representation, network design, and data preparation. First, we introduce a UV-guided avatar modeling strategy, in which each input image is associated with a pixel-wise facial correspondence estimation. Such correspondence estimation allows us to reproject each valid pixel color from screen space to UV space, which is independent of camera pose and character expression. Furthermore, we design learnable UV tokens on which the attention mechanism can be applied at both the screen and UV levels. The learned UV tokens can be decoded into canonical Gaussian attributes using aggregated UV information from all input views. To train our large avatar model, we additionally prepare a large-scale, identity-rich synthetic training dataset. Our method significantly outperforms existing approaches in both monocular and multi-view settings. Project page: https://zijian-wu.github.io/uika-page/
HeadLighter: Disentangling Illumination in Generative 3D Gaussian Heads via Lightstage Captures
Jan 05, 2026Recent 3D-aware head generative models based on 3D Gaussian Splatting achieve real-time, photorealistic and view-consistent head synthesis. However, a fundamental limitation persists: the deep entanglement of illumination and intrinsic appearance prevents controllable relighting. Existing disentanglement methods rely on strong assumptions to enable weakly supervised learning, which restricts their capacity for complex illumination. To address this challenge, we introduce HeadLighter, a novel supervised framework that learns a physically plausible decomposition of appearance and illumination in head generative models. Specifically, we design a dual-branch architecture that separately models lighting-invariant head attributes and physically grounded rendering components. A progressive disentanglement training is employed to gradually inject head appearance priors into the generative architecture, supervised by multi-view images captured under controlled light conditions with a light stage setup. We further introduce a distillation strategy to generate high-quality normals for realistic rendering. Experiments demonstrate that our method preserves high-quality generation and real-time rendering, while simultaneously supporting explicit lighting and viewpoint editing. We will publicly release our code and dataset.
Tessellation GS: Neural Mesh Gaussians for Robust Monocular Reconstruction of Dynamic Objects
Dec 08, 20253D Gaussian Splatting (GS) enables highly photorealistic scene reconstruction from posed image sequences but struggles with viewpoint extrapolation due to its anisotropic nature, leading to overfitting and poor generalization, particularly in sparse-view and dynamic scene reconstruction. We propose Tessellation GS, a structured 2D GS approach anchored on mesh faces, to reconstruct dynamic scenes from a single continuously moving or static camera. Our method constrains 2D Gaussians to localized regions and infers their attributes via hierarchical neural features on mesh faces. Gaussian subdivision is guided by an adaptive face subdivision strategy driven by a detail-aware loss function. Additionally, we leverage priors from a reconstruction foundation model to initialize Gaussian deformations, enabling robust reconstruction of general dynamic objects from a single static camera, previously extremely challenging for optimization-based methods. Our method outperforms previous SOTA method, reducing LPIPS by 29.1% and Chamfer distance by 49.2% on appearance and mesh reconstruction tasks.
ManiVideo: Generating Hand-Object Manipulation Video with Dexterous and Generalizable Grasping
Dec 18, 2024



In this paper, we introduce ManiVideo, a novel method for generating consistent and temporally coherent bimanual hand-object manipulation videos from given motion sequences of hands and objects. The core idea of ManiVideo is the construction of a multi-layer occlusion (MLO) representation that learns 3D occlusion relationships from occlusion-free normal maps and occlusion confidence maps. By embedding the MLO structure into the UNet in two forms, the model enhances the 3D consistency of dexterous hand-object manipulation. To further achieve the generalizable grasping of objects, we integrate Objaverse, a large-scale 3D object dataset, to address the scarcity of video data, thereby facilitating the learning of extensive object consistency. Additionally, we propose an innovative training strategy that effectively integrates multiple datasets, supporting downstream tasks such as human-centric hand-object manipulation video generation. Through extensive experiments, we demonstrate that our approach not only achieves video generation with plausible hand-object interaction and generalizable objects, but also outperforms existing SOTA methods.
Tele-Aloha: A Low-budget and High-authenticity Telepresence System Using Sparse RGB Cameras
May 23, 2024
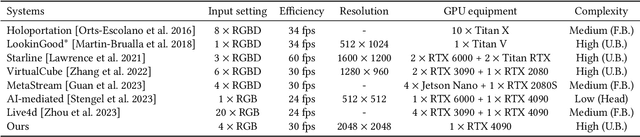

In this paper, we present a low-budget and high-authenticity bidirectional telepresence system, Tele-Aloha, targeting peer-to-peer communication scenarios. Compared to previous systems, Tele-Aloha utilizes only four sparse RGB cameras, one consumer-grade GPU, and one autostereoscopic screen to achieve high-resolution (2048x2048), real-time (30 fps), low-latency (less than 150ms) and robust distant communication. As the core of Tele-Aloha, we propose an efficient novel view synthesis algorithm for upper-body. Firstly, we design a cascaded disparity estimator for obtaining a robust geometry cue. Additionally a neural rasterizer via Gaussian Splatting is introduced to project latent features onto target view and to decode them into a reduced resolution. Further, given the high-quality captured data, we leverage weighted blending mechanism to refine the decoded image into the final resolution of 2K. Exploiting world-leading autostereoscopic display and low-latency iris tracking, users are able to experience a strong three-dimensional sense even without any wearable head-mounted display device. Altogether, our telepresence system demonstrates the sense of co-presence in real-life experiments, inspiring the next generation of communication.
Ins-HOI: Instance Aware Human-Object Interactions Recovery
Dec 15, 2023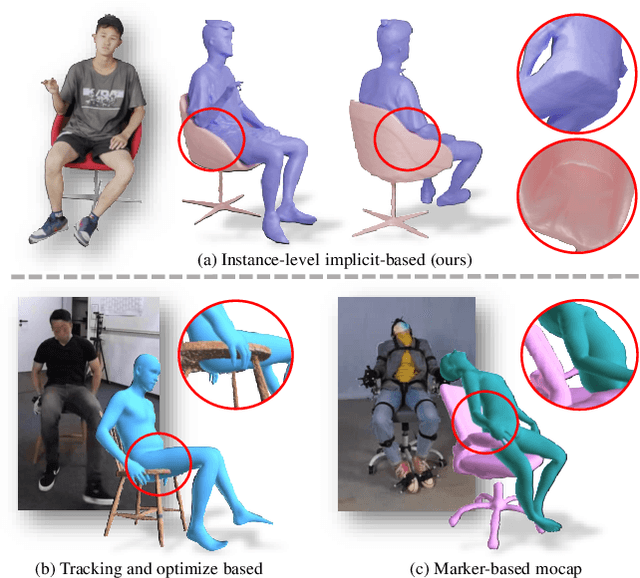



Recovering detailed interactions between humans/hands and objects is an appealing yet challenging task. Existing methods typically use template-based representations to track human/hand and objects in interactions. Despite the progress, they fail to handle the invisible contact surfaces. In this paper, we propose Ins-HOI, an end-to-end solution to recover human/hand-object reconstruction via instance-level implicit reconstruction. To this end, we introduce an instance-level occupancy field to support simultaneous human/hand and object representation, and a complementary training strategy to handle the lack of instance-level ground truths. Such a representation enables learning a contact prior implicitly from sparse observations. During the complementary training, we augment the real-captured data with synthesized data by randomly composing individual scans of humans/hands and objects and intentionally allowing for penetration. In this way, our network learns to recover individual shapes as completely as possible from the synthesized data, while being aware of the contact constraints and overall reasonability based on real-captured scans. As demonstrated in experiments, our method Ins-HOI can produce reasonable and realistic non-visible contact surfaces even in cases of extremely close interaction. To facilitate the research of this task, we collect a large-scale, high-fidelity 3D scan dataset, including 5.2k high-quality scans with real-world human-chair and hand-object interactions. We will release our dataset and source codes. Data examples and the video results of our method can be found on the project page.
GPS-Gaussian: Generalizable Pixel-wise 3D Gaussian Splatting for Real-time Human Novel View Synthesis
Dec 04, 2023We present a new approach, termed GPS-Gaussian, for synthesizing novel views of a character in a real-time manner. The proposed method enables 2K-resolution rendering under a sparse-view camera setting. Unlike the original Gaussian Splatting or neural implicit rendering methods that necessitate per-subject optimizations, we introduce Gaussian parameter maps defined on the source views and regress directly Gaussian Splatting properties for instant novel view synthesis without any fine-tuning or optimization. To this end, we train our Gaussian parameter regression module on a large amount of human scan data, jointly with a depth estimation module to lift 2D parameter maps to 3D space. The proposed framework is fully differentiable and experiments on several datasets demonstrate that our method outperforms state-of-the-art methods while achieving an exceeding rendering speed.
GaussianAvatar: Towards Realistic Human Avatar Modeling from a Single Video via Animatable 3D Gaussians
Dec 04, 2023



We present GaussianAvatar, an efficient approach to creating realistic human avatars with dynamic 3D appearances from a single video. We start by introducing animatable 3D Gaussians to explicitly represent humans in various poses and clothing styles. Such an explicit and animatable representation can fuse 3D appearances more efficiently and consistently from 2D observations. Our representation is further augmented with dynamic properties to support pose-dependent appearance modeling, where a dynamic appearance network along with an optimizable feature tensor is designed to learn the motion-to-appearance mapping. Moreover, by leveraging the differentiable motion condition, our method enables a joint optimization of motions and appearances during avatar modeling, which helps to tackle the long-standing issue of inaccurate motion estimation in monocular settings. The efficacy of GaussianAvatar is validated on both the public dataset and our collected dataset, demonstrating its superior performances in terms of appearance quality and rendering efficiency.
Leveraging Intrinsic Properties for Non-Rigid Garment Alignment
Aug 18, 2023We address the problem of aligning real-world 3D data of garments, which benefits many applications such as texture learning, physical parameter estimation, generative modeling of garments, etc. Existing extrinsic methods typically perform non-rigid iterative closest point and struggle to align details due to incorrect closest matches and rigidity constraints. While intrinsic methods based on functional maps can produce high-quality correspondences, they work under isometric assumptions and become unreliable for garment deformations which are highly non-isometric. To achieve wrinkle-level as well as texture-level alignment, we present a novel coarse-to-fine two-stage method that leverages intrinsic manifold properties with two neural deformation fields, in the 3D space and the intrinsic space, respectively. The coarse stage performs a 3D fitting, where we leverage intrinsic manifold properties to define a manifold deformation field. The coarse fitting then induces a functional map that produces an alignment of intrinsic embeddings. We further refine the intrinsic alignment with a second neural deformation field for higher accuracy. We evaluate our method with our captured garment dataset, GarmCap. The method achieves accurate wrinkle-level and texture-level alignment and works for difficult garment types such as long coats. Our project page is https://jsnln.github.io/iccv2023_intrinsic/index.html.