 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometric Context Transformer for Streaming 3D Reconstruction
Apr 16, 2026Streaming 3D reconstruction aims to recover 3D information, such as camera poses and point clouds, from a video stream, which necessitates geometric accuracy, temporal consistency, and computational efficiency. Motivated by the principles of Simultaneous Localization and Mapping (SLAM), we introduce LingBot-Map, a feed-forward 3D foundation model for reconstructing scenes from streaming data, built upon a geometric context transformer (GCT) architecture. A defining aspect of LingBot-Map lies in its carefully designed attention mechanism, which integrates an anchor context, a pose-reference window, and a trajectory memory to address coordinate grounding, dense geometric cues, and long-range drift correction, respectively. This design keeps the streaming state compact while retaining rich geometric context, enabling stable efficient inference at around 20 FPS on 518 x 378 resolution inputs over long sequences exceeding 10,000 frames. Extensive evaluations across a variety of benchmarks demonstrate that our approach achieves superior performance compared to both existing streaming and iterative optimization-based approaches.
UIKA: Fast Universal Head Avatar from Pose-Free Images
Jan 12, 2026We present UIKA, a feed-forward animatable Gaussian head model from an arbitrary number of unposed inputs, including a single image, multi-view captures, and smartphone-captured videos. Unlike the traditional avatar method, which requires a studio-level multi-view capture system and reconstructs a human-specific model through a long-time optimization process, we rethink the task through the lenses of model representation, network design, and data preparation. First, we introduce a UV-guided avatar modeling strategy, in which each input image is associated with a pixel-wise facial correspondence estimation. Such correspondence estimation allows us to reproject each valid pixel color from screen space to UV space, which is independent of camera pose and character expression. Furthermore, we design learnable UV tokens on which the attention mechanism can be applied at both the screen and UV levels. The learned UV tokens can be decoded into canonical Gaussian attributes using aggregated UV information from all input views. To train our large avatar model, we additionally prepare a large-scale, identity-rich synthetic training dataset. Our method significantly outperforms existing approaches in both monocular and multi-view settings. Project page: https://zijian-wu.github.io/uika-page/
GaussianAvatar: Towards Realistic Human Avatar Modeling from a Single Video via Animatable 3D Gaussians
Dec 04, 2023



We present GaussianAvatar, an efficient approach to creating realistic human avatars with dynamic 3D appearances from a single video. We start by introducing animatable 3D Gaussians to explicitly represent humans in various poses and clothing styles. Such an explicit and animatable representation can fuse 3D appearances more efficiently and consistently from 2D observations. Our representation is further augmented with dynamic properties to support pose-dependent appearance modeling, where a dynamic appearance network along with an optimizable feature tensor is designed to learn the motion-to-appearance mapping. Moreover, by leveraging the differentiable motion condition, our method enables a joint optimization of motions and appearances during avatar modeling, which helps to tackle the long-standing issue of inaccurate motion estimation in monocular settings. The efficacy of GaussianAvatar is validated on both the public dataset and our collected dataset, demonstrating its superior performances in terms of appearance quality and rendering efficiency.
CaPhy: Capturing Physical Properties for Animatable Human Avatars
Aug 11, 2023
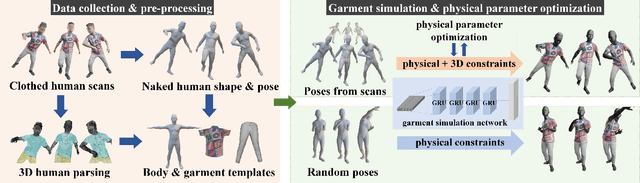


We present CaPhy, a novel method for reconstructing animatable human avatars with realistic dynamic properties for clothing. Specifically, we aim for capturing the geometric and physical properties of the clothing from real observations. This allows us to apply novel poses to the human avatar with physically correct deformations and wrinkles of the clothing. To this end, we combine unsupervised training with physics-based losses and 3D-supervised training using scanned data to reconstruct a dynamic model of clothing that is physically realistic and conforms to the human scans. We also optimize the physical parameters of the underlying physical model from the scans by introducing gradient constraints of the physics-based losses. In contrast to previous work on 3D avatar reconstruction, our method is able to generalize to novel poses with realistic dynamic cloth deformations. Experiments on several subjects demonstrate that our method can estimate the physical properties of the garments, resulting in superior quantitative and qualitative results compared with previous methods.
Real-time Monocular Full-body Capture in World Space via Sequential Proxy-to-Motion Learning
Jul 03, 2023



Learning-based approaches to monocular motion capture have recently shown promising results by learning to regress in a data-driven manner. However, due to the challenges in data collection and network designs, it remains challenging for existing solutions to achieve real-time full-body capture while being accurate in world space. In this work, we contribute a sequential proxy-to-motion learning scheme together with a proxy dataset of 2D skeleton sequences and 3D rotational motions in world space. Such proxy data enables us to build a learning-based network with accurate full-body supervision while also mitigating the generalization issues. For more accurate and physically plausible predictions, a contact-aware neural motion descent module is proposed in our network so that it can be aware of foot-ground contact and motion misalignment with the proxy observations. Additionally, we share the body-hand context information in our network for more compatible wrist poses recovery with the full-body model. With the proposed learning-based solution, we demonstrate the first real-time monocular full-body capture system with plausible foot-ground contact in world space. More video results can be found at our project page: https://liuyebin.com/proxycap.