 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayGA: Layered Gaussian Avatars for Animatable Clothing Transfer
May 12, 2024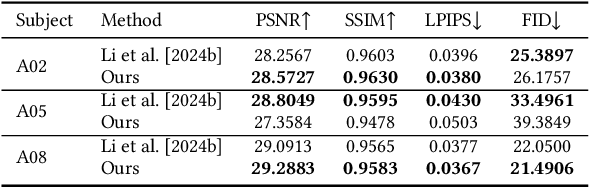

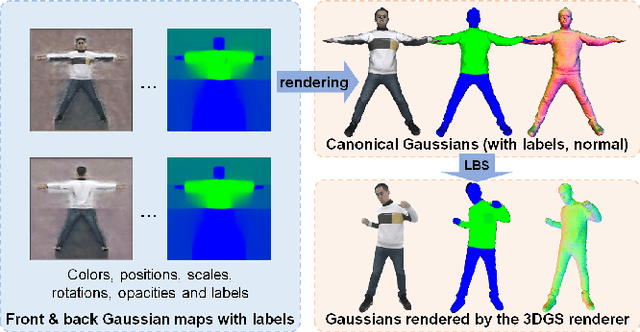
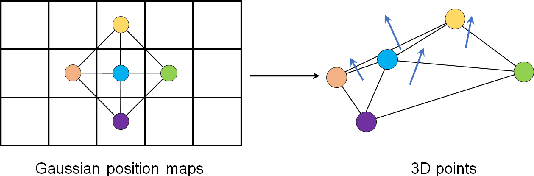
Animatable clothing transfer, aiming at dressing and animating garments across characters, is a challenging problem. Most human avatar works entangle the representations of the human body and clothing together, which leads to difficulties for virtual try-on across identities. What's worse, the entangled representations usually fail to exactly track the sliding motion of garments. To overcome these limitations, we present Layered Gaussian Avatars (LayGA), a new representation that formulates body and clothing as two separate layers for photorealistic animatable clothing transfer from multi-view videos. Our representation is built upon the Gaussian map-based avatar for its excellent representation power of garment details. However, the Gaussian map produces unstructured 3D Gaussians distributed around the actual surface. The absence of a smooth explicit surface raises challenges in accurate garment tracking and collision handling between body and garments. Therefore, we propose two-stage training involving single-layer reconstruction and multi-layer fitting. In the single-layer reconstruction stage, we propose a series of geometric constraints to reconstruct smooth surfaces and simultaneously obtain the segmentation between body and clothing. Next, in the multi-layer fitting stage, we train two separate models to represent body and clothing and utilize the reconstructed clothing geometries as 3D supervision for more accurate garment tracking. Furthermore, we propose geometry and rendering layers for both high-quality geometric reconstruction and high-fidelity rendering. Overall, the proposed LayGA realizes photorealistic animations and virtual try-on, and outperforms other baseline methods. Our project page is https://jsnln.github.io/layga/index.html.
Leveraging Intrinsic Properties for Non-Rigid Garment Alignment
Aug 18, 2023We address the problem of aligning real-world 3D data of garments, which benefits many applications such as texture learning, physical parameter estimation, generative modeling of garments, etc. Existing extrinsic methods typically perform non-rigid iterative closest point and struggle to align details due to incorrect closest matches and rigidity constraints. While intrinsic methods based on functional maps can produce high-quality correspondences, they work under isometric assumptions and become unreliable for garment deformations which are highly non-isometric. To achieve wrinkle-level as well as texture-level alignment, we present a novel coarse-to-fine two-stage method that leverages intrinsic manifold properties with two neural deformation fields, in the 3D space and the intrinsic space, respectively. The coarse stage performs a 3D fitting, where we leverage intrinsic manifold properties to define a manifold deformation field. The coarse fitting then induces a functional map that produces an alignment of intrinsic embeddings. We further refine the intrinsic alignment with a second neural deformation field for higher accuracy. We evaluate our method with our captured garment dataset, GarmCap. The method achieves accurate wrinkle-level and texture-level alignment and works for difficult garment types such as long coats. Our project page is https://jsnln.github.io/iccv2023_intrinsic/index.html.
CaPhy: Capturing Physical Properties for Animatable Human Avatars
Aug 11, 2023
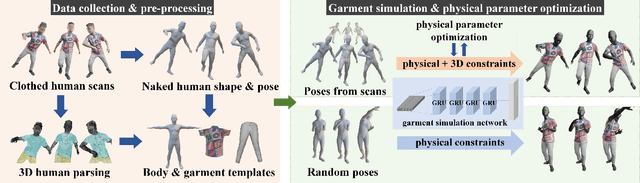


We present CaPhy, a novel method for reconstructing animatable human avatars with realistic dynamic properties for clothing. Specifically, we aim for capturing the geometric and physical properties of the clothing from real observations. This allows us to apply novel poses to the human avatar with physically correct deformations and wrinkles of the clothing. To this end, we combine unsupervised training with physics-based losses and 3D-supervised training using scanned data to reconstruct a dynamic model of clothing that is physically realistic and conforms to the human scans. We also optimize the physical parameters of the underlying physical model from the scans by introducing gradient constraints of the physics-based losses. In contrast to previous work on 3D avatar reconstruction, our method is able to generalize to novel poses with realistic dynamic cloth deformations. Experiments on several subjects demonstrate that our method can estimate the physical properties of the garments, resulting in superior quantitative and qualitative results compared with previous methods.
CloSET: Modeling Clothed Humans on Continuous Surface with Explicit Template Decomposition
Apr 06, 2023Creating animatable avatars from static scans requires the modeling of clothing deformations in different poses. Existing learning-based methods typically add pose-dependent deformations upon a minimally-clothed mesh template or a learned implicit template, which have limitations in capturing details or hinder end-to-end learning. In this paper, we revisit point-based solutions and propose to decompose explicit garment-related templates and then add pose-dependent wrinkles to them. In this way, the clothing deformations are disentangled such that the pose-dependent wrinkles can be better learned and applied to unseen poses. Additionally, to tackle the seam artifact issues in recent state-of-the-art point-based methods, we propose to learn point features on a body surface, which establishes a continuous and compact feature space to capture the fine-grained and pose-dependent clothing geometry. To facilitate the research in this field, we also introduce a high-quality scan dataset of humans in real-world clothing. Our approach is validated on two existing datasets and our newly introduced dataset, showing better clothing deformation results in unseen poses. The project page with code and dataset can be found at https://www.liuyebin.com/closet.
Learning Implicit Templates for Point-Based Clothed Human Modeling
Jul 14, 2022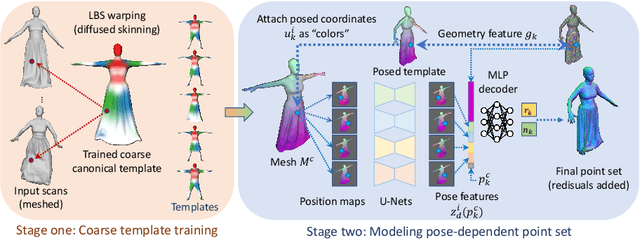

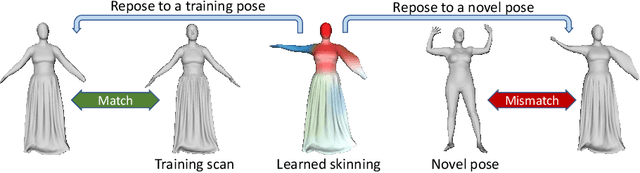

We present FITE, a First-Implicit-Then-Explicit framework for modeling human avatars in clothing. Our framework first learns implicit surface templates representing the coarse clothing topology, and then employs the templates to guide the generation of point sets which further capture pose-dependent clothing deformations such as wrinkles. Our pipeline incorporates the merits of both implicit and explicit representations, namely, the ability to handle varying topology and the ability to efficiently capture fine details. We also propose diffused skinning to facilitate template training especially for loose clothing, and projection-based pose-encoding to extract pose information from mesh templates without predefined UV map or connectivity. Our code is publicly available at https://github.com/jsnln/fite.
Learning Modified Indicator Functions for Surface Reconstruction
Nov 18, 2021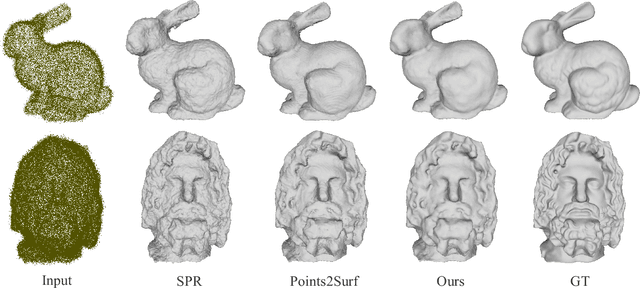
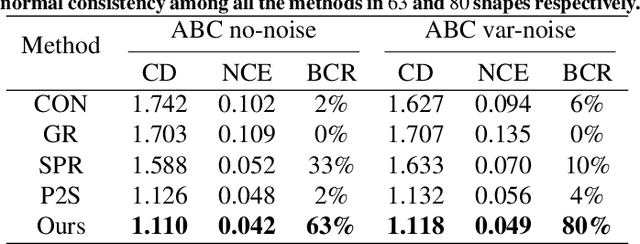
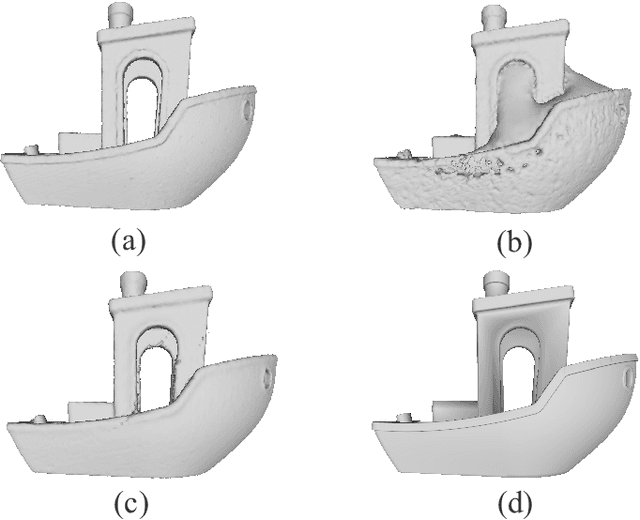
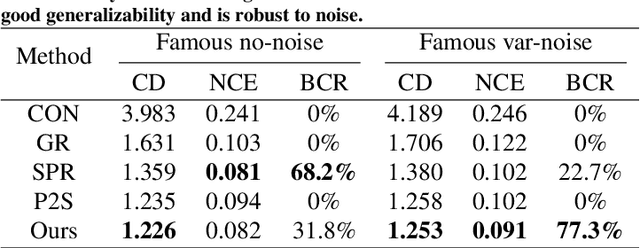
Surface reconstruction is a fundamental problem in 3D graphics. In this paper, we propose a learning-based approach for implicit surface reconstruction from raw point clouds without normals. Our method is inspired by Gauss Lemma in potential energy theory, which gives an explicit integral formula for the indicator functions. We design a novel deep neural network to perform surface integral and learn the modified indicator functions from un-oriented and noisy point clouds. We concatenate features with different scales for accurate point-wise contributions to the integral. Moreover, we propose a novel Surface Element Feature Extractor to learn local shape properties. Experiments show that our method generates smooth surfaces with high normal consistency from point clouds with different noise scales and achieves state-of-the-art reconstruction performance compared with current data-driven and non-data-driven approaches.