 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Implicit Templates for Point-Based Clothed Human Modeling
Paper and Code
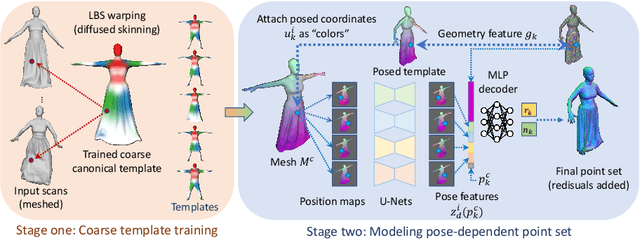

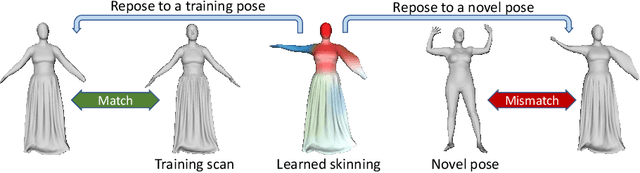

We present FITE, a First-Implicit-Then-Explicit framework for modeling human avatars in clothing. Our framework first learns implicit surface templates representing the coarse clothing topology, and then employs the templates to guide the generation of point sets which further capture pose-dependent clothing deformations such as wrinkles. Our pipeline incorporates the merits of both implicit and explicit representations, namely, the ability to handle varying topology and the ability to efficiently capture fine details. We also propose diffused skinning to facilitate template training especially for loose clothing, and projection-based pose-encoding to extract pose information from mesh templates without predefined UV map or connectivity. Our code is publicly available at https://github.com/jsnln/fite.