 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayGA: Layered Gaussian Avatars for Animatable Clothing Transfer
Paper and Code
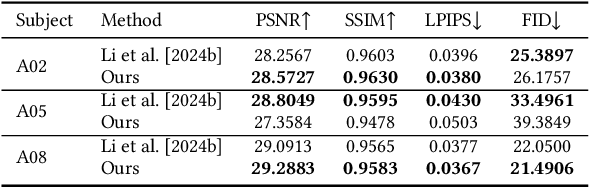

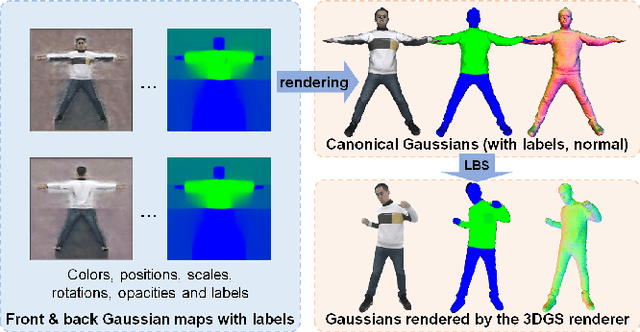
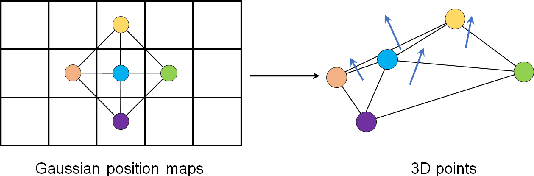
Animatable clothing transfer, aiming at dressing and animating garments across characters, is a challenging problem. Most human avatar works entangle the representations of the human body and clothing together, which leads to difficulties for virtual try-on across identities. What's worse, the entangled representations usually fail to exactly track the sliding motion of garments. To overcome these limitations, we present Layered Gaussian Avatars (LayGA), a new representation that formulates body and clothing as two separate layers for photorealistic animatable clothing transfer from multi-view videos. Our representation is built upon the Gaussian map-based avatar for its excellent representation power of garment details. However, the Gaussian map produces unstructured 3D Gaussians distributed around the actual surface. The absence of a smooth explicit surface raises challenges in accurate garment tracking and collision handling between body and garments. Therefore, we propose two-stage training involving single-layer reconstruction and multi-layer fitting. In the single-layer reconstruction stage, we propose a series of geometric constraints to reconstruct smooth surfaces and simultaneously obtain the segmentation between body and clothing. Next, in the multi-layer fitting stage, we train two separate models to represent body and clothing and utilize the reconstructed clothing geometries as 3D supervision for more accurate garment tracking. Furthermore, we propose geometry and rendering layers for both high-quality geometric reconstruction and high-fidelity rendering. Overall, the proposed LayGA realizes photorealistic animations and virtual try-on, and outperforms other baseline methods. Our project page is https://jsnln.github.io/layga/index.html.