 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Visual Grounding in 3D Gaussians via View Retrieval
Sep 19, 2025


3D Visual Grounding (3DVG) aims to locate objects in 3D scenes based on text prompts, which is essential for applications such as robotics. However, existing 3DVG methods encounter two main challenges: first, they struggle to handle the implicit representation of spatial textures in 3D Gaussian Splatting (3DGS), making per-scene training indispensable; second, they typically require larges amounts of labeled data for effective training. To this end, we propose \underline{G}rounding via \underline{V}iew \underline{R}etrieval (GVR), a novel zero-shot visual grounding framework for 3DGS to transform 3DVG as a 2D retrieval task that leverages object-level view retrieval to collect grounding clues from multiple views, which not only avoids the costly process of 3D annotation, but also eliminates the need for per-scene training. Extensive experiments demonstrate that our method achieves state-of-the-art visual grounding performance while avoiding per-scene training, providing a solid foundation for zero-shot 3DVG research. Video demos can be found in https://github.com/leviome/GVR_demos.
GPS-Gaussian: Generalizable Pixel-wise 3D Gaussian Splatting for Real-time Human Novel View Synthesis
Dec 04, 2023We present a new approach, termed GPS-Gaussian, for synthesizing novel views of a character in a real-time manner. The proposed method enables 2K-resolution rendering under a sparse-view camera setting. Unlike the original Gaussian Splatting or neural implicit rendering methods that necessitate per-subject optimizations, we introduce Gaussian parameter maps defined on the source views and regress directly Gaussian Splatting properties for instant novel view synthesis without any fine-tuning or optimization. To this end, we train our Gaussian parameter regression module on a large amount of human scan data, jointly with a depth estimation module to lift 2D parameter maps to 3D space. The proposed framework is fully differentiable and experiments on several datasets demonstrate that our method outperforms state-of-the-art methods while achieving an exceeding rendering speed.
GaussianAvatar: Towards Realistic Human Avatar Modeling from a Single Video via Animatable 3D Gaussians
Dec 04, 2023



We present GaussianAvatar, an efficient approach to creating realistic human avatars with dynamic 3D appearances from a single video. We start by introducing animatable 3D Gaussians to explicitly represent humans in various poses and clothing styles. Such an explicit and animatable representation can fuse 3D appearances more efficiently and consistently from 2D observations. Our representation is further augmented with dynamic properties to support pose-dependent appearance modeling, where a dynamic appearance network along with an optimizable feature tensor is designed to learn the motion-to-appearance mapping. Moreover, by leveraging the differentiable motion condition, our method enables a joint optimization of motions and appearances during avatar modeling, which helps to tackle the long-standing issue of inaccurate motion estimation in monocular settings. The efficacy of GaussianAvatar is validated on both the public dataset and our collected dataset, demonstrating its superior performances in terms of appearance quality and rendering efficiency.
AvatarReX: Real-time Expressive Full-body Avatars
May 08, 2023


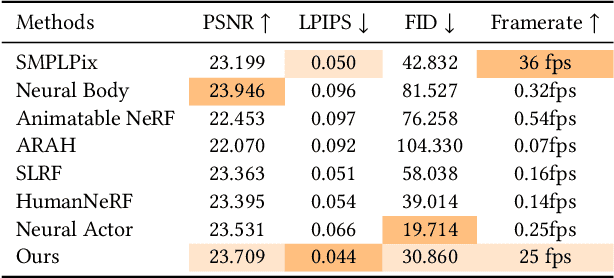
We present AvatarReX, a new method for learning NeRF-based full-body avatars from video data. The learnt avatar not only provides expressive control of the body, hands and the face together, but also supports real-time animation and rendering. To this end, we propose a compositional avatar representation, where the body, hands and the face are separately modeled in a way that the structural prior from parametric mesh templates is properly utilized without compromising representation flexibility. Furthermore, we disentangle the geometry and appearance for each part. With these technical designs, we propose a dedicated deferred rendering pipeline, which can be executed in real-time framerate to synthesize high-quality free-view images. The disentanglement of geometry and appearance also allows us to design a two-pass training strategy that combines volume rendering and surface rendering for network training. In this way, patch-level supervision can be applied to force the network to learn sharp appearance details on the basis of geometry estimation. Overall, our method enables automatic construction of expressive full-body avatars with real-time rendering capability, and can generate photo-realistic images with dynamic details for novel body motions and facial expressions.
Tensor4D : Efficient Neural 4D Decomposition for High-fidelity Dynamic Reconstruction and Rendering
Nov 21, 2022



We present Tensor4D, an efficient yet effective approach to dynamic scene modeling. The key of our solution is an efficient 4D tensor decomposition method so that the dynamic scene can be directly represented as a 4D spatio-temporal tensor. To tackle the accompanying memory issue, we decompose the 4D tensor hierarchically by projecting it first into three time-aware volumes and then nine compact feature planes. In this way, spatial information over time can be simultaneously captured in a compact and memory-efficient manner. When applying Tensor4D for dynamic scene reconstruction and rendering, we further factorize the 4D fields to different scales in the sense that structural motions and dynamic detailed changes can be learned from coarse to fine. The effectiveness of our method is validated on both synthetic and real-world scenes. Extensive experiments show that our method is able to achieve high-quality dynamic reconstruction and rendering from sparse-view camera rigs or even a monocular camera. The code and dataset will be released at https://liuyebin.com/tensor4d/tensor4d.html.
4-D Epanechnikov Mixture Regression in Light Field Image Compression
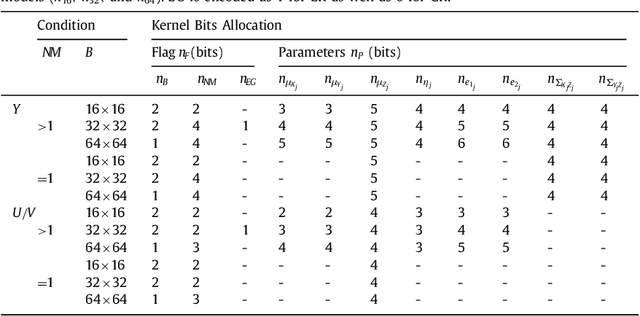
Aug 14, 2021With the emergence of light field imaging in recent years, the compression of its elementary image array (EIA) has become a significant problem. Our coding framework includes modeling and reconstruction. For the modeling, the covariance-matrix form of the 4-D Epanechnikov kernel (4-D EK) and its correlated statistics were deduced to obtain the 4-D Epanechnikov mixture models (4-D EMMs). A 4-D Epanechnikov mixture regression (4-D EMR) was proposed based on this 4-D EK, and a 4-D adaptive model selection (4-D AMLS) algorithm was designed to realize the optimal modeling for a pseudo video sequence (PVS) of the extracted key-EIA. A linear function based reconstruction (LFBR) was proposed based on the correlation between adjacent elementary images (EIs). The decoded images realized a clear outline reconstruction and superior coding efficiency compared to high-efficiency video coding (HEVC) and JPEG 2000 below approximately 0.05 bpp. This work realized an unprecedented theoretical application by (1) proposing the 4-D Epanechnikov kernel theory, (2) exploiting the 4-D Epanechnikov mixture regression and its application in the modeling of the pseudo video sequence of light field images, (3) using 4-D adaptive model selection for the optimal number of models, and (4) employing a linear function-based reconstruction according to the content similarity.
* 16 pages, 17 figures, IEEE Transactions on Circuits and Systems for Video Technology ( Early Access )
Three-dimensional Epanechnikov mixture regression in image coding
Jun 03, 2021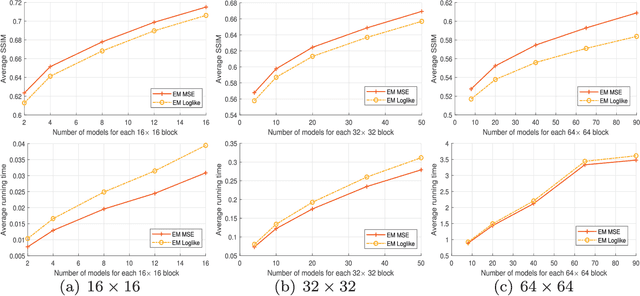

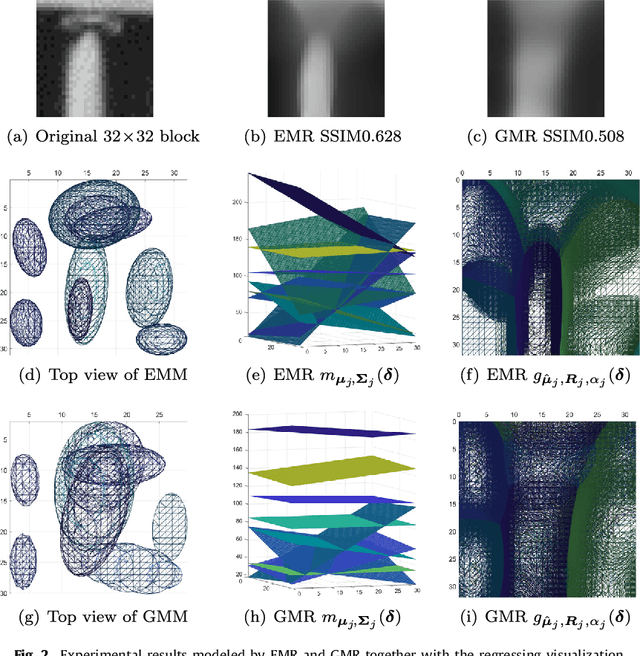
Kernel methods have been studied extensively in recent years. We propose a three-dimensional (3-D) Epanechnikov Mixture Regression (EMR) based on our Epanechnikov Kernel (EK) and realize a complete framework for image coding. In our research, we deduce the covariance-matrix form of 3-D Epanechnikov kernels and their correlated statistics to obtain the Epanechnikov mixture models. To apply our theories to image coding, we propose the 3-D EMR which can better model an image in smaller blocks compared with the conventional Gaussian Mixture Regression (GMR). The regressions are all based on our improved Expectation-Maximization (EM) algorithm with mean square error optimization. Finally, we design an Adaptive Mode Selection (AMS) algorithm to realize the best model pattern combination for coding. Our recovered image has clear outlines and superior coding efficiency compared to JPEG below 0.25bpp. Our work realizes an unprecedented theory application by: (1) enriching the theory of Epanechnikov kernel,(2) improving the EM algorithm using MSE optimization, (3) exploiting the EMR and its application in image coding, and (4) AMS optimal modeling combined with Gaussian and Epanechnikov kernel.
* 12 pages, 9 figures