 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSharpTimeGS: Sharp and Stable Dynamic Gaussian Splatting via Lifespan Modulation
Feb 03, 2026Novel view synthesis of dynamic scenes is fundamental to achieving photorealistic 4D reconstruction and immersive visual experiences. Recent progress in Gaussian-based representations has significantly improved real-time rendering quality, yet existing methods still struggle to maintain a balance between long-term static and short-term dynamic regions in both representation and optimization. To address this, we present SharpTimeGS, a lifespan-aware 4D Gaussian framework that achieves temporally adaptive modeling of both static and dynamic regions under a unified representation. Specifically, we introduce a learnable lifespan parameter that reformulates temporal visibility from a Gaussian-shaped decay into a flat-top profile, allowing primitives to remain consistently active over their intended duration and avoiding redundant densification. In addition, the learned lifespan modulates each primitives' motion, reducing drift in long-lived static points while retaining unrestricted motion for short-lived dynamic ones. This effectively decouples motion magnitude from temporal duration, improving long-term stability without compromising dynamic fidelity. Moreover, we design a lifespan-velocity-aware densification strategy that mitigates optimization imbalance between static and dynamic regions by allocating more capacity to regions with pronounced motion while keeping static areas compact and stable. Extensive experiments on multiple benchmarks demonstrate that our method achieves state-of-the-art performance while supporting real-time rendering up to 4K resolution at 100 FPS on one RTX 4090.
Tessellation GS: Neural Mesh Gaussians for Robust Monocular Reconstruction of Dynamic Objects
Dec 08, 20253D Gaussian Splatting (GS) enables highly photorealistic scene reconstruction from posed image sequences but struggles with viewpoint extrapolation due to its anisotropic nature, leading to overfitting and poor generalization, particularly in sparse-view and dynamic scene reconstruction. We propose Tessellation GS, a structured 2D GS approach anchored on mesh faces, to reconstruct dynamic scenes from a single continuously moving or static camera. Our method constrains 2D Gaussians to localized regions and infers their attributes via hierarchical neural features on mesh faces. Gaussian subdivision is guided by an adaptive face subdivision strategy driven by a detail-aware loss function. Additionally, we leverage priors from a reconstruction foundation model to initialize Gaussian deformations, enabling robust reconstruction of general dynamic objects from a single static camera, previously extremely challenging for optimization-based methods. Our method outperforms previous SOTA method, reducing LPIPS by 29.1% and Chamfer distance by 49.2% on appearance and mesh reconstruction tasks.
ManiVideo: Generating Hand-Object Manipulation Video with Dexterous and Generalizable Grasping
Dec 18, 2024



In this paper, we introduce ManiVideo, a novel method for generating consistent and temporally coherent bimanual hand-object manipulation videos from given motion sequences of hands and objects. The core idea of ManiVideo is the construction of a multi-layer occlusion (MLO) representation that learns 3D occlusion relationships from occlusion-free normal maps and occlusion confidence maps. By embedding the MLO structure into the UNet in two forms, the model enhances the 3D consistency of dexterous hand-object manipulation. To further achieve the generalizable grasping of objects, we integrate Objaverse, a large-scale 3D object dataset, to address the scarcity of video data, thereby facilitating the learning of extensive object consistency. Additionally, we propose an innovative training strategy that effectively integrates multiple datasets, supporting downstream tasks such as human-centric hand-object manipulation video generation. Through extensive experiments, we demonstrate that our approach not only achieves video generation with plausible hand-object interaction and generalizable objects, but also outperforms existing SOTA methods.
Tele-Aloha: A Low-budget and High-authenticity Telepresence System Using Sparse RGB Cameras
May 23, 2024
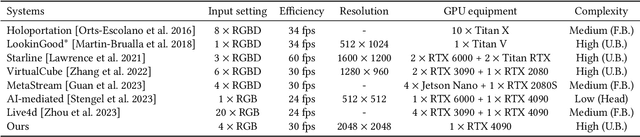

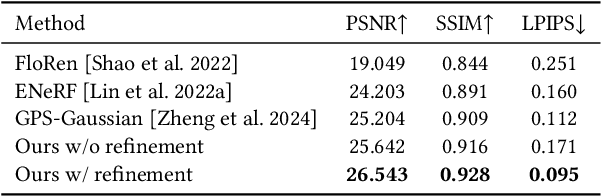
In this paper, we present a low-budget and high-authenticity bidirectional telepresence system, Tele-Aloha, targeting peer-to-peer communication scenarios. Compared to previous systems, Tele-Aloha utilizes only four sparse RGB cameras, one consumer-grade GPU, and one autostereoscopic screen to achieve high-resolution (2048x2048), real-time (30 fps), low-latency (less than 150ms) and robust distant communication. As the core of Tele-Aloha, we propose an efficient novel view synthesis algorithm for upper-body. Firstly, we design a cascaded disparity estimator for obtaining a robust geometry cue. Additionally a neural rasterizer via Gaussian Splatting is introduced to project latent features onto target view and to decode them into a reduced resolution. Further, given the high-quality captured data, we leverage weighted blending mechanism to refine the decoded image into the final resolution of 2K. Exploiting world-leading autostereoscopic display and low-latency iris tracking, users are able to experience a strong three-dimensional sense even without any wearable head-mounted display device. Altogether, our telepresence system demonstrates the sense of co-presence in real-life experiments, inspiring the next generation of communication.
Tensor4D : Efficient Neural 4D Decomposition for High-fidelity Dynamic Reconstruction and Rendering
Nov 21, 2022



We present Tensor4D, an efficient yet effective approach to dynamic scene modeling. The key of our solution is an efficient 4D tensor decomposition method so that the dynamic scene can be directly represented as a 4D spatio-temporal tensor. To tackle the accompanying memory issue, we decompose the 4D tensor hierarchically by projecting it first into three time-aware volumes and then nine compact feature planes. In this way, spatial information over time can be simultaneously captured in a compact and memory-efficient manner. When applying Tensor4D for dynamic scene reconstruction and rendering, we further factorize the 4D fields to different scales in the sense that structural motions and dynamic detailed changes can be learned from coarse to fine. The effectiveness of our method is validated on both synthetic and real-world scenes. Extensive experiments show that our method is able to achieve high-quality dynamic reconstruction and rendering from sparse-view camera rigs or even a monocular camera. The code and dataset will be released at https://liuyebin.com/tensor4d/tensor4d.html.