 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeU-Mind: A Unified Framework for Real-Time Multimodal Interaction with Audiovisual Generation
Feb 27, 2026Full-stack multimodal interaction in real-time is a central goal in building intelligent embodied agents capable of natural, dynamic communication. However, existing systems are either limited to unimodal generation or suffer from degraded reasoning and poor cross-modal alignment, preventing coherent and perceptually grounded interactions. In this work, we introduce U-Mind, the first unified system for high-intelligence multimodal dialogue that supports real-time generation and jointly models language, speech, motion, and video synthesis within a single interactive loop. At its core, U-Mind implements a Unified Alignment and Reasoning Framework that addresses two key challenges: enhancing cross-modal synchronization via a segment-wise alignment strategy, and preserving reasoning abilities through Rehearsal-Driven Learning. During inference, U-Mind adopts a text-first decoding pipeline that performs internal chain-of-thought planning followed by temporally synchronized generation across modalities. To close the loop, we implement a real-time video rendering framework conditioned on pose and speech, enabling expressive and synchronized visual feedback. Extensive experiments demonstrate that U-Mind achieves state-of-the-art performance on a range of multimodal interaction tasks, including question answering, instruction following, and motion generation, paving the way toward intelligent, immersive conversational agents.
ManiVideo: Generating Hand-Object Manipulation Video with Dexterous and Generalizable Grasping
Dec 18, 2024



In this paper, we introduce ManiVideo, a novel method for generating consistent and temporally coherent bimanual hand-object manipulation videos from given motion sequences of hands and objects. The core idea of ManiVideo is the construction of a multi-layer occlusion (MLO) representation that learns 3D occlusion relationships from occlusion-free normal maps and occlusion confidence maps. By embedding the MLO structure into the UNet in two forms, the model enhances the 3D consistency of dexterous hand-object manipulation. To further achieve the generalizable grasping of objects, we integrate Objaverse, a large-scale 3D object dataset, to address the scarcity of video data, thereby facilitating the learning of extensive object consistency. Additionally, we propose an innovative training strategy that effectively integrates multiple datasets, supporting downstream tasks such as human-centric hand-object manipulation video generation. Through extensive experiments, we demonstrate that our approach not only achieves video generation with plausible hand-object interaction and generalizable objects, but also outperforms existing SOTA methods.
Stereo-Talker: Audio-driven 3D Human Synthesis with Prior-Guided Mixture-of-Experts
Oct 31, 2024



This paper introduces Stereo-Talker, a novel one-shot audio-driven human video synthesis system that generates 3D talking videos with precise lip synchronization, expressive body gestures, temporally consistent photo-realistic quality, and continuous viewpoint control. The process follows a two-stage approach. In the first stage, the system maps audio input to high-fidelity motion sequences, encompassing upper-body gestures and facial expressions. To enrich motion diversity and authenticity, large language model (LLM) priors are integrated with text-aligned semantic audio features, leveraging LLMs' cross-modal generalization power to enhance motion quality. In the second stage, we improve diffusion-based video generation models by incorporating a prior-guided Mixture-of-Experts (MoE) mechanism: a view-guided MoE focuses on view-specific attributes, while a mask-guided MoE enhances region-based rendering stability. Additionally, a mask prediction module is devised to derive human masks from motion data, enhancing the stability and accuracy of masks and enabling mask guiding during inference. We also introduce a comprehensive human video dataset with 2,203 identities, covering diverse body gestures and detailed annotations, facilitating broad generalization. The code, data, and pre-trained models will be released for research purposes.
Human4DiT: Free-view Human Video Generation with 4D Diffusion Transformer
May 27, 2024
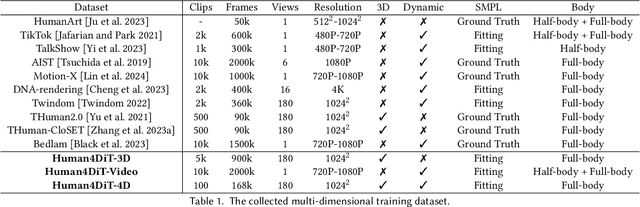
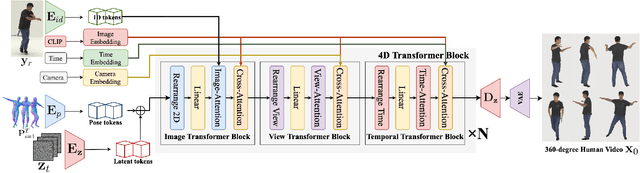
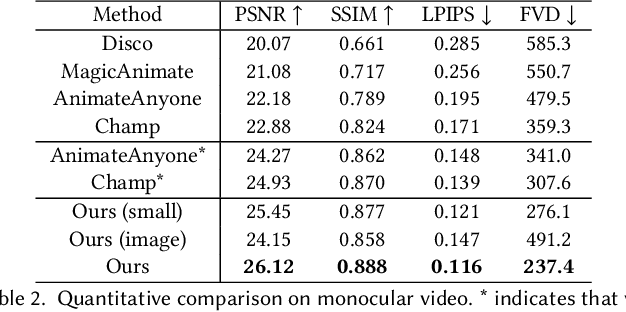
We present a novel approach for generating high-quality, spatio-temporally coherent human videos from a single image under arbitrary viewpoints. Our framework combines the strengths of U-Nets for accurate condition injection and diffusion transformers for capturing global correlations across viewpoints and time. The core is a cascaded 4D transformer architecture that factorizes attention across views, time, and spatial dimensions, enabling efficient modeling of the 4D space. Precise conditioning is achieved by injecting human identity, camera parameters, and temporal signals into the respective transformers. To train this model, we curate a multi-dimensional dataset spanning images, videos, multi-view data and 3D/4D scans, along with a multi-dimensional training strategy. Our approach overcomes the limitations of previous methods based on GAN or UNet-based diffusion models, which struggle with complex motions and viewpoint changes. Through extensive experiments, we demonstrate our method's ability to synthesize realistic, coherent and free-view human videos, paving the way for advanced multimedia applications in areas such as virtual reality and animation. Our project website is https://human4dit.github.io.
TaleCrafter: Interactive Story Visualization with Multiple Characters
May 30, 2023



Accurate Story visualization requires several necessary elements, such as identity consistency across frames, the alignment between plain text and visual content, and a reasonable layout of objects in images. Most previous works endeavor to meet these requirements by fitting a text-to-image (T2I) model on a set of videos in the same style and with the same characters, e.g., the FlintstonesSV dataset. However, the learned T2I models typically struggle to adapt to new characters, scenes, and styles, and often lack the flexibility to revise the layout of the synthesized images. This paper proposes a system for generic interactive story visualization, capable of handling multiple novel characters and supporting the editing of layout and local structure. It is developed by leveraging the prior knowledge of large language and T2I models, trained on massive corpora. The system comprises four interconnected components: story-to-prompt generation (S2P), text-to-layout generation (T2L), controllable text-to-image generation (C-T2I), and image-to-video animation (I2V). First, the S2P module converts concise story information into detailed prompts required for subsequent stages. Next, T2L generates diverse and reasonable layouts based on the prompts, offering users the ability to adjust and refine the layout to their preference. The core component, C-T2I, enables the creation of images guided by layouts, sketches, and actor-specific identifiers to maintain consistency and detail across visualizations. Finally, I2V enriches the visualization process by animating the generated images. Extensive experiments and a user study are conducted to validate the effectiveness and flexibility of interactive editing of the proposed system.
DPE: Disentanglement of Pose and Expression for General Video Portrait Editing
Jan 16, 2023One-shot video-driven talking face generation aims at producing a synthetic talking video by transferring the facial motion from a video to an arbitrary portrait image. Head pose and facial expression are always entangled in facial motion and transferred simultaneously. However, the entanglement sets up a barrier for these methods to be used in video portrait editing directly, where it may require to modify the expression only while maintaining the pose unchanged. One challenge of decoupling pose and expression is the lack of paired data, such as the same pose but different expressions. Only a few methods attempt to tackle this challenge with the feat of 3D Morphable Models (3DMMs) for explicit disentanglement. But 3DMMs are not accurate enough to capture facial details due to the limited number of Blenshapes, which has side effects on motion transfer. In this paper, we introduce a novel self-supervised disentanglement framework to decouple pose and expression without 3DMMs and paired data, which consists of a motion editing module, a pose generator, and an expression generator. The editing module projects faces into a latent space where pose motion and expression motion can be disentangled, and the pose or expression transfer can be performed in the latent space conveniently via addition. The two generators render the modified latent codes to images, respectively. Moreover, to guarantee the disentanglement, we propose a bidirectional cyclic training strategy with well-designed constraints. Evaluations demonstrate our method can control pose or expression independently and be used for general video editing.