 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefReward-SR: LR-Conditioned Reward Modeling for Preference-Aligned Super-Resolution
Mar 25, 2026Recent advances in generative super-resolution (SR) have greatly improved visual realism, yet existing evaluation and optimization frameworks remain misaligned with human perception. Full-Reference and No-Reference metrics often fail to reflect perceptual preference, either penalizing semantically plausible details due to pixel misalignment or favoring visually sharp but inconsistent artifacts. Moreover, most SR methods rely on ground-truth (GT)-dependent distribution matching, which does not necessarily correspond to human judgments. In this work, we propose RefReward-SR, a low-resolution (LR) reference-aware reward model for preference-aligned SR. Instead of relying on GT supervision or NR evaluation, RefReward-SR assesses high-resolution (HR) reconstructions conditioned on their LR inputs, treating the LR image as a semantic anchor. Leveraging the visual-linguistic priors of a Multimodal Large Language Models (MLLM), it evaluates semantic consistency and plausibility in a reasoning-aware manner. To support this paradigm, we construct RefSR-18K, the first large-scale LR-conditioned preference dataset for SR, providing pairwise rankings based on LR-HR consistency and HR naturalness. We fine-tune the MLLM with Group Relative Policy Optimization (GRPO) using LR-conditioned ranking rewards, and further integrate GRPO into SR model training with RefReward-SR as the core reward signal for preference-aligned generation. Extensive experiments show that our framework achieves substantially better alignment with human judgments, producing reconstructions that preserve semantic consistency while enhancing perceptual plausibility and visual naturalness. Code, models, and datasets will be released upon paper acceptance.
PointCFormer: a Relation-based Progressive Feature Extraction Network for Point Cloud Completion
Dec 11, 2024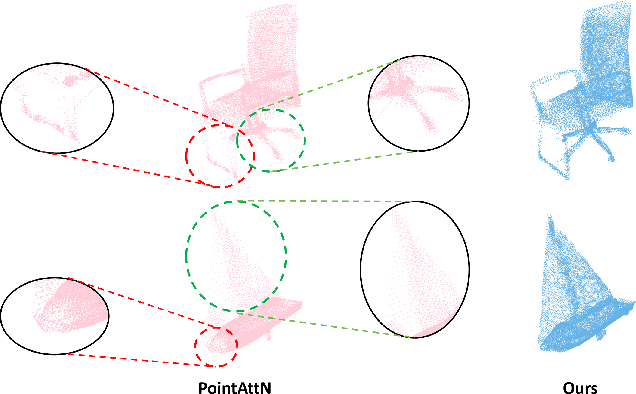
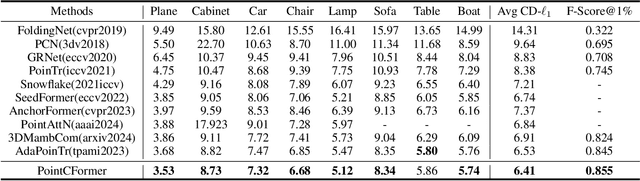
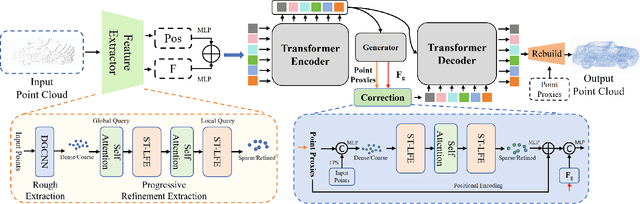
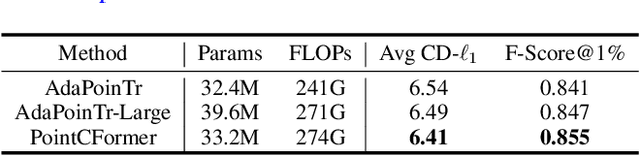
Point cloud completion aims to reconstruct the complete 3D shape from incomplete point clouds, and it is crucial for tasks such as 3D object detection and segmentation. Despite the continuous advances in point cloud analysis techniques, feature extraction methods are still confronted with apparent limitations. The sparse sampling of point clouds, used as inputs in most methods, often results in a certain loss of global structure information. Meanwhile, traditional local feature extraction methods usually struggle to capture the intricate geometric details. To overcome these drawbacks, we introduce PointCFormer, a transformer framework optimized for robust global retention and precise local detail capture in point cloud completion. This framework embraces several key advantages. First, we propose a relation-based local feature extraction method to perceive local delicate geometry characteristics. This approach establishes a fine-grained relationship metric between the target point and its k-nearest neighbors, quantifying each neighboring point's contribution to the target point's local features. Secondly, we introduce a progressive feature extractor that integrates our local feature perception method with self-attention. Starting with a denser sampling of points as input, it iteratively queries long-distance global dependencies and local neighborhood relationships. This extractor maintains enhanced global structure and refined local details, without generating substantial computational overhead. Additionally, we develop a correction module after generating point proxies in the latent space to reintroduce denser information from the input points, enhancing the representation capability of the point proxies. PointCFormer demonstrates state-of-the-art performance on several widely used benchmarks.
E$^3$-Net: Efficient E-Equivariant Normal Estimation Network
Jun 01, 2024Point cloud normal estimation is a fundamental task in 3D geometry processing. While recent learning-based methods achieve notable advancements in normal prediction, they often overlook the critical aspect of equivariance. This results in inefficient learning of symmetric patterns. To address this issue, we propose E3-Net to achieve equivariance for normal estimation. We introduce an efficient random frame method, which significantly reduces the training resources required for this task to just 1/8 of previous work and improves the accuracy. Further, we design a Gaussian-weighted loss function and a receptive-aware inference strategy that effectively utilizes the local properties of point clouds. Our method achieves superior results on both synthetic and real-world datasets, and outperforms current state-of-the-art techniques by a substantial margin. We improve RMSE by 4% on the PCPNet dataset, 2.67% on the SceneNN dataset, and 2.44% on the FamousShape dataset.
SECAD-Net: Self-Supervised CAD Reconstruction by Learning Sketch-Extrude Operations
Mar 19, 2023

Reverse engineering CAD models from raw geometry is a classic but strenuous research problem. Previous learning-based methods rely heavily on labels due to the supervised design patterns or reconstruct CAD shapes that are not easily editable. In this work, we introduce SECAD-Net, an end-to-end neural network aimed at reconstructing compact and easy-to-edit CAD models in a self-supervised manner. Drawing inspiration from the modeling language that is most commonly used in modern CAD software, we propose to learn 2D sketches and 3D extrusion parameters from raw shapes, from which a set of extrusion cylinders can be generated by extruding each sketch from a 2D plane into a 3D body. By incorporating the Boolean operation (i.e., union), these cylinders can be combined to closely approximate the target geometry. We advocate the use of implicit fields for sketch representation, which allows for creating CAD variations by interpolating latent codes in the sketch latent space. Extensive experiments on both ABC and Fusion 360 datasets demonstrate the effectiveness of our method, and show superiority over state-of-the-art alternatives including the closely related method for supervised CAD reconstruction. We further apply our approach to CAD editing and single-view CAD reconstruction. The code is released at https://github.com/BunnySoCrazy/SECAD-Net.
DPE: Disentanglement of Pose and Expression for General Video Portrait Editing
Jan 16, 2023One-shot video-driven talking face generation aims at producing a synthetic talking video by transferring the facial motion from a video to an arbitrary portrait image. Head pose and facial expression are always entangled in facial motion and transferred simultaneously. However, the entanglement sets up a barrier for these methods to be used in video portrait editing directly, where it may require to modify the expression only while maintaining the pose unchanged. One challenge of decoupling pose and expression is the lack of paired data, such as the same pose but different expressions. Only a few methods attempt to tackle this challenge with the feat of 3D Morphable Models (3DMMs) for explicit disentanglement. But 3DMMs are not accurate enough to capture facial details due to the limited number of Blenshapes, which has side effects on motion transfer. In this paper, we introduce a novel self-supervised disentanglement framework to decouple pose and expression without 3DMMs and paired data, which consists of a motion editing module, a pose generator, and an expression generator. The editing module projects faces into a latent space where pose motion and expression motion can be disentangled, and the pose or expression transfer can be performed in the latent space conveniently via addition. The two generators render the modified latent codes to images, respectively. Moreover, to guarantee the disentanglement, we propose a bidirectional cyclic training strategy with well-designed constraints. Evaluations demonstrate our method can control pose or expression independently and be used for general video editing.