 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D MedDiffusion: A 3D Medical Diffusion Model for Controllable and High-quality Medical Image Generation
Dec 17, 2024



The generation of medical images presents significant challenges due to their high-resolution and three-dimensional nature. Existing methods often yield suboptimal performance in generating high-quality 3D medical images, and there is currently no universal generative framework for medical imaging. In this paper, we introduce the 3D Medical Diffusion (3D MedDiffusion) model for controllable, high-quality 3D medical image generation. 3D MedDiffusion incorporates a novel, highly efficient Patch-Volume Autoencoder that compresses medical images into latent space through patch-wise encoding and recovers back into image space through volume-wise decoding. Additionally, we design a new noise estimator to capture both local details and global structure information during diffusion denoising process. 3D MedDiffusion can generate fine-detailed, high-resolution images (up to 512x512x512) and effectively adapt to various downstream tasks as it is trained on large-scale datasets covering CT and MRI modalities and different anatomical regions (from head to leg). Experimental results demonstrate that 3D MedDiffusion surpasses state-of-the-art methods in generative quality and exhibits strong generalizability across tasks such as sparse-view CT reconstruction, fast MRI reconstruction, and data augmentation.
End-to-end Triple-domain PET Enhancement: A Hybrid Denoising-and-reconstruction Framework for Reconstructing Standard-dose PET Images from Low-dose PET Sinograms
Dec 04, 2024


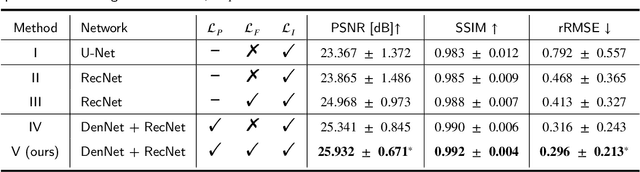
As a sensitive functional imaging technique, positron emission tomography (PET) plays a critical role in early disease diagnosis. However, obtaining a high-quality PET image requires injecting a sufficient dose (standard dose) of radionuclides into the body, which inevitably poses radiation hazards to patients. To mitigate radiation hazards, the reconstruction of standard-dose PET (SPET) from low-dose PET (LPET) is desired. According to imaging theory, PET reconstruction process involves multiple domains (e.g., projection domain and image domain), and a significant portion of the difference between SPET and LPET arises from variations in the noise levels introduced during the sampling of raw data as sinograms. In light of these two facts, we propose an end-to-end TriPle-domain LPET EnhancemenT (TriPLET) framework, by leveraging the advantages of a hybrid denoising-and-reconstruction process and a triple-domain representation (i.e., sinograms, frequency spectrum maps, and images) to reconstruct SPET images from LPET sinograms. Specifically, TriPLET consists of three sequentially coupled components including 1) a Transformer-assisted denoising network that denoises the inputted LPET sinograms in the projection domain, 2) a discrete-wavelet-transform-based reconstruction network that further reconstructs SPET from LPET in the wavelet domain, and 3) a pair-based adversarial network that evaluates the reconstructed SPET images in the image domain. Extensive experiments on the real PET dataset demonstrate that our proposed TriPLET can reconstruct SPET images with the highest similarity and signal-to-noise ratio to real data, compared with state-of-the-art methods.
DVasMesh: Deep Structured Mesh Reconstruction from Vascular Images for Dynamics Modeling of Vessels
Dec 01, 2024



Vessel dynamics simulation is vital in studying the relationship between geometry and vascular disease progression. Reliable dynamics simulation relies on high-quality vascular meshes. Most of the existing mesh generation methods highly depend on manual annotation, which is time-consuming and laborious, usually facing challenges such as branch merging and vessel disconnection. This will hinder vessel dynamics simulation, especially for the population study. To address this issue, we propose a deep learning-based method, dubbed as DVasMesh to directly generate structured hexahedral vascular meshes from vascular images. Our contributions are threefold. First, we propose to formally formulate each vertex of the vascular graph by a four-element vector, including coordinates of the centerline point and the radius. Second, a vectorized graph template is employed to guide DVasMesh to estimate the vascular graph. Specifically, we introduce a sampling operator, which samples the extracted features of the vascular image (by a segmentation network) according to the vertices in the template graph. Third, we employ a graph convolution network (GCN) and take the sampled features as nodes to estimate the deformation between vertices of the template graph and target graph, and the deformed graph template is used to build the mesh. Taking advantage of end-to-end learning and discarding direct dependency on annotated labels, our DVasMesh demonstrates outstanding performance in generating structured vascular meshes on cardiac and cerebral vascular images. It shows great potential for clinical applications by reducing mesh generation time from 2 hours (manual) to 30 seconds (automatic).
Towards General Text-guided Image Synthesis for Customized Multimodal Brain MRI Generation
Sep 25, 2024



Multimodal brain magnetic resonance (MR) imaging is indispensable in neuroscience and neurology. However, due to the accessibility of MRI scanners and their lengthy acquisition time, multimodal MR images are not commonly available. Current MR image synthesis approaches are typically trained on independent datasets for specific tasks, leading to suboptimal performance when applied to novel datasets and tasks. Here, we present TUMSyn, a Text-guided Universal MR image Synthesis generalist model, which can flexibly generate brain MR images with demanded imaging metadata from routinely acquired scans guided by text prompts. To ensure TUMSyn's image synthesis precision, versatility, and generalizability, we first construct a brain MR database comprising 31,407 3D images with 7 MRI modalities from 13 centers. We then pre-train an MRI-specific text encoder using contrastive learning to effectively control MR image synthesis based on text prompts. Extensive experiments on diverse datasets and physician assessments indicate that TUMSyn can generate clinically meaningful MR images with specified imaging metadata in supervised and zero-shot scenarios. Therefore, TUMSyn can be utilized along with acquired MR scan(s) to facilitate large-scale MRI-based screening and diagnosis of brain diseases.
A Progressive Single-Modality to Multi-Modality Classification Framework for Alzheimer's Disease Sub-type Diagnosis
Jul 26, 2024
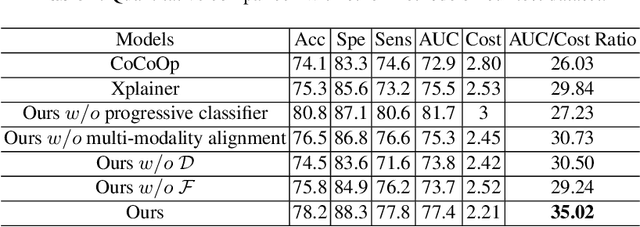

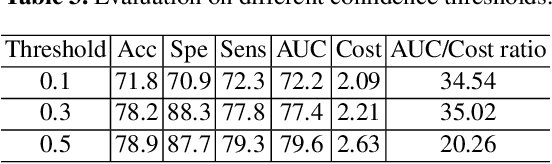
The current clinical diagnosis framework of Alzheimer's disease (AD) involves multiple modalities acquired from multiple diagnosis stages, each with distinct usage and cost. Previous AD diagnosis research has predominantly focused on how to directly fuse multiple modalities for an end-to-end one-stage diagnosis, which practically requires a high cost in data acquisition. Moreover, a significant part of these methods diagnose AD without considering clinical guideline and cannot offer accurate sub-type diagnosis. In this paper, by exploring inter-correlation among multiple modalities, we propose a novel progressive AD sub-type diagnosis framework, aiming to give diagnosis results based on easier-to-access modalities in earlier low-cost stages, instead of modalities from all stages. Specifically, first, we design 1) a text disentanglement network for better processing tabular data collected in the initial stage, and 2) a modality fusion module for fusing multi-modality features separately. Second, we align features from modalities acquired in earlier low-cost stage(s) with later high-cost stage(s) to give accurate diagnosis without actual modality acquisition in later-stage(s) for saving cost. Furthermore, we follow the clinical guideline to align features at each stage for achieving sub-type diagnosis. Third, we leverage a progressive classifier that can progressively include additional acquired modalities (if needed) for diagnosis, to achieve the balance between diagnosis cost and diagnosis performance. We evaluate our proposed framework on large diverse public and in-home datasets (8280 in total) and achieve superior performance over state-of-the-art methods. Our codes will be released after the acceptance.
A GPU-Accelerated Light-field Super-resolution Framework Based on Mixed Noise Model and Weighted Regularization
Jun 09, 2022
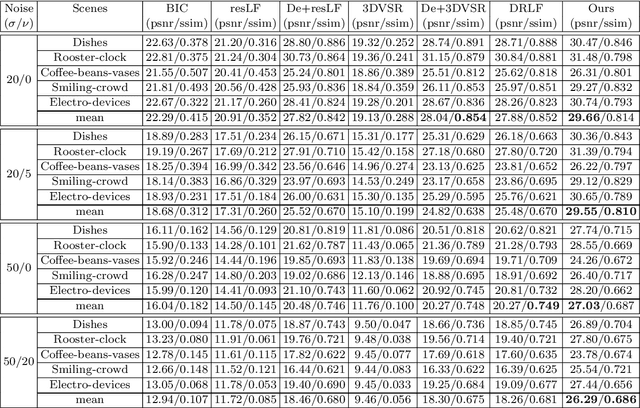

This paper presents a GPU-accelerated computational framework for reconstructing high resolution (HR) LF images under a mixed Gaussian-Impulse noise condition. The main focus is on developing a high-performance approach considering processing speed and reconstruction quality. From a statistical perspective, we derive a joint $\ell^1$-$\ell^2$ data fidelity term for penalizing the HR reconstruction error taking into account the mixed noise situation. For regularization, we employ the weighted non-local total variation approach, which allows us to effectively realize LF image prior through a proper weighting scheme. We show that the alternating direction method of multipliers algorithm (ADMM) can be used to simplify the computation complexity and results in a high-performance parallel computation on the GPU Platform. An extensive experiment is conducted on both synthetic 4D LF dataset and natural image dataset to validate the proposed SR model's robustness and evaluate the accelerated optimizer's performance. The experimental results show that our approach achieves better reconstruction quality under severe mixed-noise conditions as compared to the state-of-the-art approaches. In addition, the proposed approach overcomes the limitation of the previous work in handling large-scale SR tasks. While fitting within a single off-the-shelf GPU, the proposed accelerator provides an average speedup of 2.46$\times$ and 1.57$\times$ for $\times 2$ and $\times 3$ SR tasks, respectively. In addition, a speedup of $77\times$ is achieved as compared to CPU execution.
Multi-Material Blind Beam Hardening Correction Based on Non-Linearity Adjustment of Projections
Mar 09, 2022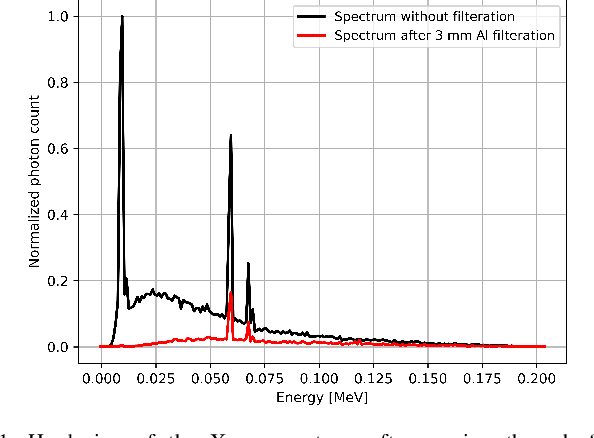
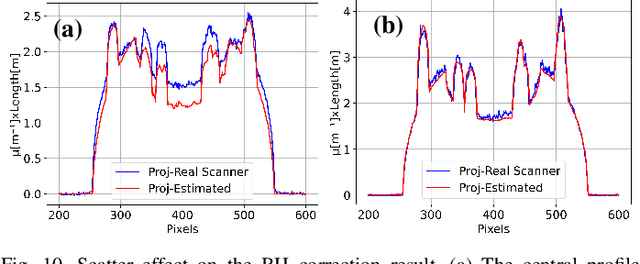
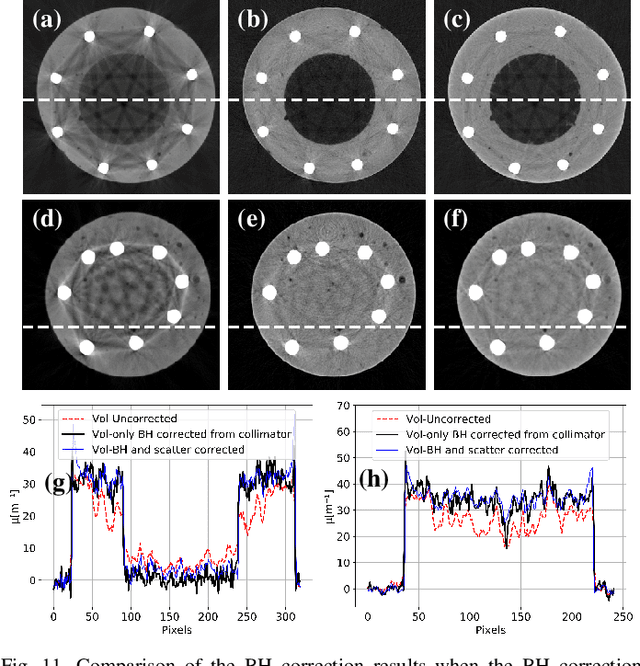
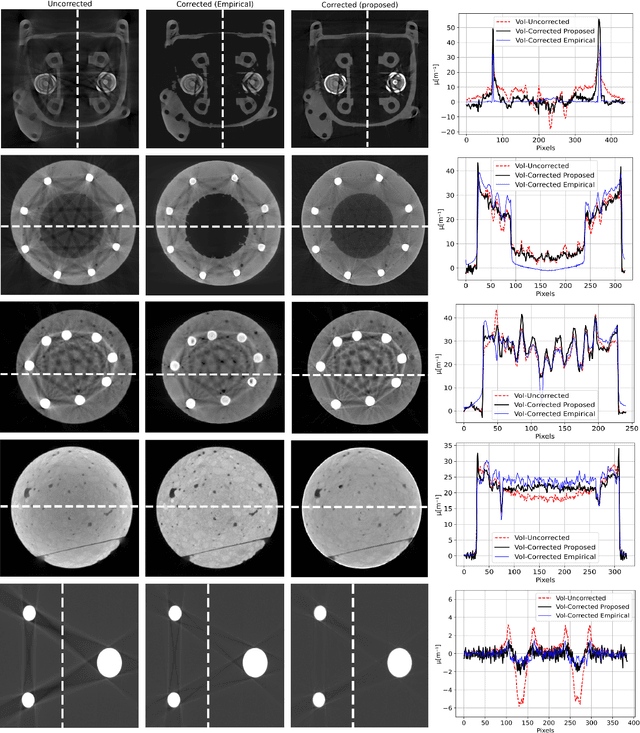
Beam hardening (BH) is one of the major artifacts that severely reduces the quality of Computed Tomography (CT) imaging. In a polychromatic X-ray beam, since low-energy photons are more preferentially absorbed, the attenuation of the beam is no longer a linear function of the absorber thickness. The existing BH correction methods either require a given material, which might be unfeasible in reality, or they require a long computation time. This work aims to propose a fast and accurate BH correction method that requires no prior knowledge of the materials and corrects first and higher-order BH artifacts. In the first step, a wide sweep of the material is performed based on an experimentally measured look-up table to obtain the closest estimate of the material. Then the non-linearity effect of the BH is corrected by adding the difference between the estimated monochromatic and the polychromatic simulated projections of the segmented image. The estimated monochromatic projection is simulated by selecting the energy from the polychromatic spectrum which produces the lowest mean square error (MSE) with the acquired projection from the scanner. The polychromatic projection is estimated by minimizing the difference between the acquired projection and the weighted sum of the simulated polychromatic projections using different spectra of different filtration. To evaluate the proposed BH correction method, we have conducted extensive experiments on the real-world CT data. Compared to the state-of-the-art empirical BH correction method, the experiments show that the proposed method can highly reduce the BH artifacts without prior knowledge of the materials.
Computational Scatter Correction for High-Resolution Flat-Panel CT Based on a Fast Monte Carlo Photon Transport Model
Jan 31, 2022In computed tomography (CT) reconstruction, scattering causes server quality degradation of the reconstructed CT images by introducing streaks and cupping artifacts which reduce the detectability of low contrast objects. Monte Carlo (MC) simulation is considered as the most accurate approach for scatter estimation. However, the existing MC estimators are computationally expensive especially for the considered high-resolution flat-panel CT. In this paper, we propose a fast and accurate photon transport model which describes the physics within the 1 keV to 1 MeV range using multiple controllable key parameters. Based on this model, scatter computation for a single projection can be completed within a range of few seconds under well-defined model parameters. Smoothing and interpolation are performed on the estimated scatter to accelerate the scatter calculation without compromising accuracy too much compared to measured near scatter-free projection images. Combining the scatter estimation with the filtered backprojection (FBP), scatter correction is performed effectively in an iterative manner. In order to evaluate the proposed MC model, we have conducted extensive experiments on the simulated data and real-world high-resolution flat-panel CT. Comparing to the state-of-the-art MC simulators, our photon transport model achieved a 202$\times$ speed-up on a four GPU system comparing to the multi-threaded state-of-the-art EGSnrc MC simulator. Besides, it is shown that for real-world high-resolution flat-panel CT, scatter correction with sufficient accuracy is accomplished within one to three iterations using a FBP and a forward projection computed with the proposed fast MC photon transport model.
A Resolution Enhancement Plug-in for Deformable Registration of Medical Images
Dec 30, 2021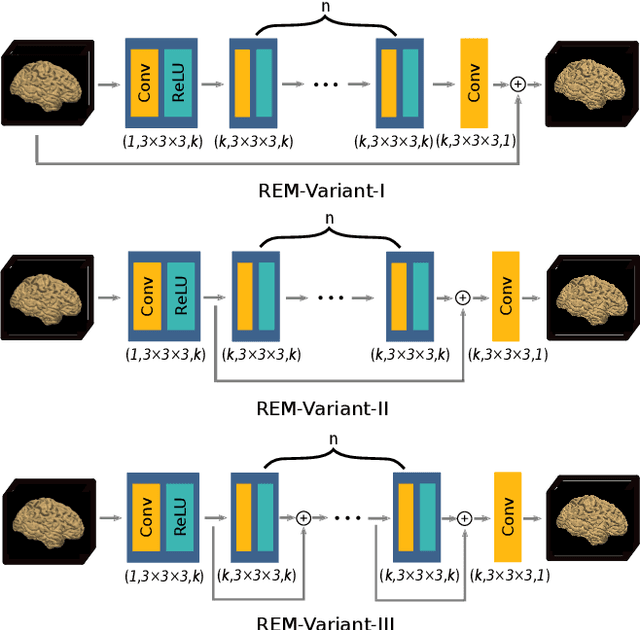
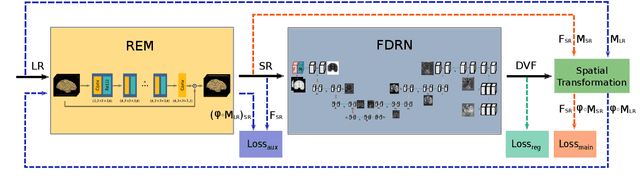
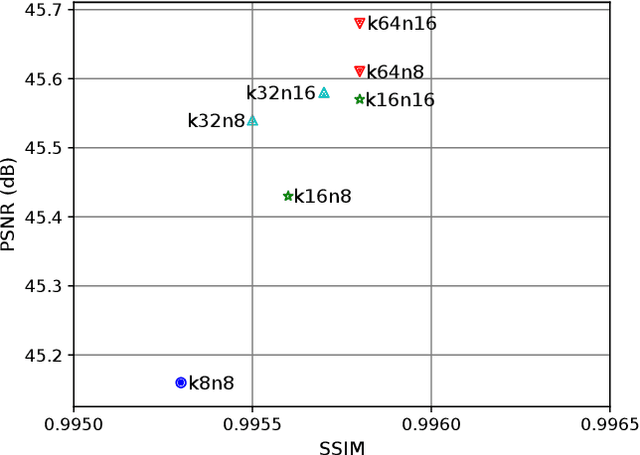
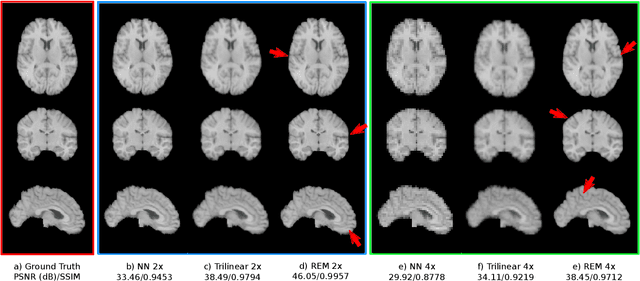
Image registration is a fundamental task for medical imaging. Resampling of the intensity values is required during registration and better spatial resolution with finer and sharper structures can improve the resampling performance and hence the registration accuracy. Super-resolution (SR) is an algorithmic technique targeting at spatial resolution enhancement which can achieve an image resolution beyond the hardware limitation. In this work, we consider SR as a preprocessing technique and present a CNN-based resolution enhancement module (REM) which can be easily plugged into the registration network in a cascaded manner. Different residual schemes and network configurations of REM are investigated to obtain an effective architecture design of REM. In fact, REM is not confined to image registration, it can also be straightforwardly integrated into other vision tasks for enhanced resolution. The proposed REM is thoroughly evaluated for deformable registration on medical images quantitatively and qualitatively at different upscaling factors. Experiments on LPBA40 brain MRI dataset demonstrate that REM not only improves the registration accuracy, especially when the input images suffer from degraded spatial resolution, but also generates resolution enhanced images which can be exploited for successive diagnosis.
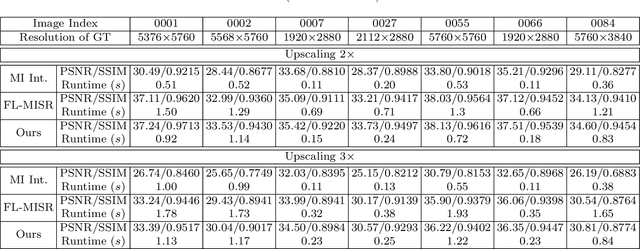
FL-MISR: Fast Large-Scale Multi-Image Super-Resolution for Computed Tomography Based on Multi-GPU Acceleration
Aug 09, 2021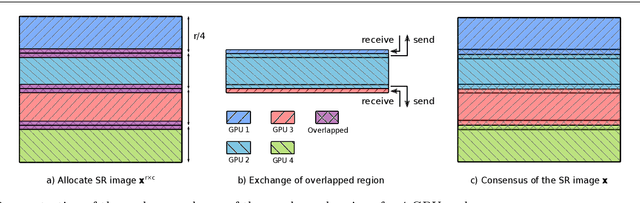

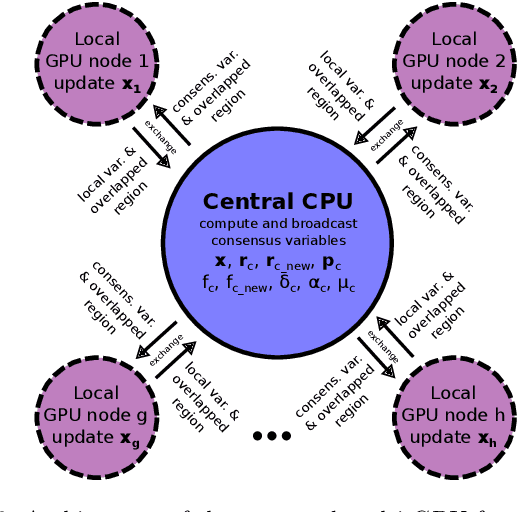

Multi-image super-resolution (MISR) usually outperforms single-image super-resolution (SISR) under a proper inter-image alignment by explicitly exploiting the inter-image correlation. However, the large computational demand encumbers the deployment of MISR methods in practice. In this work, we propose a distributed optimization framework based on data parallelism for fast large-scale MISR which supports multi- GPU acceleration, named FL-MISR. Inter-GPU communication for the exchange of local variables and over-lapped regions is enabled to impose a consensus convergence of the distributed task allocated to each GPU node. We have seamlessly integrated FL-MISR into the computed tomography (CT) imaging system by super-resolving multiple projections of the same view acquired by subpixel detector shift. The SR reconstruction is performed on the fly during the CT acquisition such that no additional computation time is introduced. We evaluated FL-MISR quantitatively and qualitatively on multiple objects including aluminium cylindrical phantoms, QRM bar pattern phantoms, and concrete joints. Experiments show that FL-MISR can effectively improve the spatial resolution of CT systems in modulation transfer function (MTF) and visual perception. Besides, comparing to a multi-core CPU implementation, FL-MISR achieves a more than 50x speedup on an off-the-shelf 4-GPU system.