 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnockoffs-based False Discovery Rate Control and Simplification for Deep Neural Networks
Jun 03, 2026The deep neural network is a widely used framework in machine learning that has been widely applied in various fields. However, deep neural networks often involve a large number of parameters and inputs, many of which may be irrelevant to the goal or true output. These parameters and \textcolor{black}{input variables} not only increase computational complexity, but also contribute to additional computational cost. One solution to this problem is knockoff methods, which have proven successful in controlling false discovery rates in high-dimensional regression. Building on the knockoff methods and using the regularised neural network, this paper proposes three variable screening methods under the condition of controlling false discovery rates: \textit{one layer filter}, \textit{multiple layers filter}, \textit{variable weight aggregation filter}. In comparison with existing algorithms, we find that our algorithms show satisfactory performance.
When Do Fewer Coordinates Suffice in DP-SGD?
Jun 03, 2026Differentially private stochastic gradient descent (DP-SGD) injects noise into every updated coordinate, making the injected noise energy scale with the ambient parameter dimension \(d\). We ask when private training can update fewer coordinates without losing the signal needed for optimization. We propose \textsc{TP-TopK} (Two-Phase TopK DP-SGD), a two-phase method for coordinate-sparse private training without public data, in which a private warm-up phase identifies a coordinate support used to guide the main training phase. We give a criterion characterizing when coordinate restriction can be beneficial, show via a nonconvex stationarity bound that under this condition the relevant noise term scales with the active dimension \(k\) rather than the full parameter dimension \(d\), and provide a lower bound on the reliability of warm-up-based coordinate ranking. Experiments on MNIST, FMNIST, and CIFAR-10 show that learned coordinate supports can retain more gradient energy than size-matched random supports, with the largest gains when the active dimension is small and warm-up scores are informative.
Revisiting Privacy Amplification by Subsampling in Selective Release DPSGD
Jun 03, 2026Machine learning's reliance on sensitive data necessitates privacy-preserving techniques like Differentially Private Stochastic Gradient Descent (DPSGD). However, DPSGD suffers from substantial utility degradation and slow convergence due to gradient clipping and noise injection. Prior works have attempted to improve DPSGD from various perspectives; notably, the Differentially Private Selective Update and Release (DPSUR) algorithm has achieved remarkable model utility. However, the privacy accounting in DPSUR overlooks the variation in sampling probability introduced by the selective release mechanism, which compromises the rigor of its privacy guarantees. To address these limitations, we re-evaluate the privacy analysis of the selective release mechanism and propose a novel algorithm: Differentially Private Selective Release based on Clipped Gradients (DPSR-CG). Through a rigorous, newly derived privacy analysis and extensive experiments on multiple datasets (MNIST, CIFAR-10, IMDB, and FMNIST), we demonstrate that our DPSR-CG mechanism maintains strict privacy guarantees while achieving exceptional model performance.
Steps Adaptive Decay DPSGD: Enhancing Performance on Imbalanced Datasets with Differential Privacy with HAM10000
Jul 09, 2025



When applying machine learning to medical image classification, data leakage is a critical issue. Previous methods, such as adding noise to gradients for differential privacy, work well on large datasets like MNIST and CIFAR-100, but fail on small, imbalanced medical datasets like HAM10000. This is because the imbalanced distribution causes gradients from minority classes to be clipped and lose crucial information, while majority classes dominate. This leads the model to fall into suboptimal solutions early. To address this, we propose SAD-DPSGD, which uses a linear decaying mechanism for noise and clipping thresholds. By allocating more privacy budget and using higher clipping thresholds in the initial training phases, the model avoids suboptimal solutions and enhances performance. Experiments show that SAD-DPSGD outperforms Auto-DPSGD on HAM10000, improving accuracy by 2.15% under $\epsilon = 3.0$ , $\delta = 10^{-3}$.
AdaDPIGU: Differentially Private SGD with Adaptive Clipping and Importance-Based Gradient Updates for Deep Neural Networks
Jul 09, 2025



Differential privacy has been proven effective for stochastic gradient descent; however, existing methods often suffer from performance degradation in high-dimensional settings, as the scale of injected noise increases with dimensionality. To tackle this challenge, we propose AdaDPIGU--a new differentially private SGD framework with importance-based gradient updates tailored for deep neural networks. In the pretraining stage, we apply a differentially private Gaussian mechanism to estimate the importance of each parameter while preserving privacy. During the gradient update phase, we prune low-importance coordinates and introduce a coordinate-wise adaptive clipping mechanism, enabling sparse and noise-efficient gradient updates. Theoretically, we prove that AdaDPIGU satisfies $(\varepsilon, \delta)$-differential privacy and retains convergence guarantees. Extensive experiments on standard benchmarks validate the effectiveness of AdaDPIGU. All results are reported under a fixed retention ratio of 60%. On MNIST, our method achieves a test accuracy of 99.12% under a privacy budget of $\epsilon = 8$, nearly matching the non-private model. Remarkably, on CIFAR-10, it attains 73.21% accuracy at $\epsilon = 4$, outperforming the non-private baseline of 71.12%, demonstrating that adaptive sparsification can enhance both privacy and utility.
Deep learning reveals the common spectrum underlying multiple brain disorders in youth and elders from brain functional networks
Feb 23, 2023



Brain disorders in the early and late life of humans potentially share pathological alterations in brain functions. However, the key evidence from neuroimaging data for pathological commonness remains unrevealed. To explore this hypothesis, we build a deep learning model, using multi-site functional magnetic resonance imaging data (N=4,410, 6 sites), for classifying 5 different brain disorders from healthy controls, with a set of common features. Our model achieves 62.6(1.9)% overall classification accuracy on data from the 6 investigated sites and detects a set of commonly affected functional subnetworks at different spatial scales, including default mode, executive control, visual, and limbic networks. In the deep-layer feature representation for individual data, we observe young and aging patients with disorders are continuously distributed, which is in line with the clinical concept of the "spectrum of disorders". The revealed spectrum underlying early- and late-life brain disorders promotes the understanding of disorder comorbidities in the lifespan.
Distribution Estimation of Contaminated Data via DNN-based MoM-GANs
Dec 28, 2022This paper studies the distribution estimation of contaminated data by the MoM-GAN method, which combines generative adversarial net (GAN) and median-of-mean (MoM) estimation. We use a deep neural network (DNN) with a ReLU activation function to model the generator and discriminator of the GAN. Theoretically, we derive a non-asymptotic error bound for the DNN-based MoM-GAN estimator measured by integral probability metrics with the $b$-smoothness H\"{o}lder class. The error bound decreases essentially as $n^{-b/p}\vee n^{-1/2}$, where $n$ and $p$ are the sample size and the dimension of input data. We give an algorithm for the MoM-GAN method and implement it through two real applications. The numerical results show that the MoM-GAN outperforms other competitive methods when dealing with contaminated data.
Statistical Guarantees for Approximate Stationary Points of Simple Neural Networks
May 09, 2022

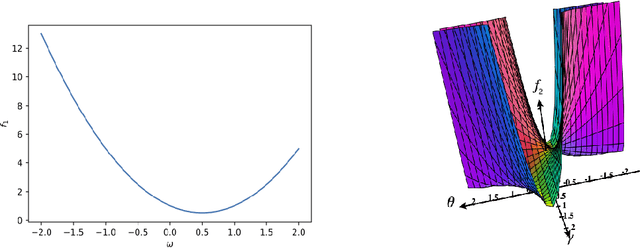
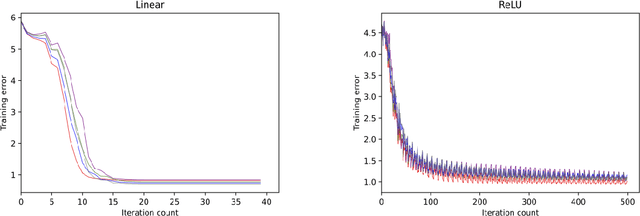
Since statistical guarantees for neural networks are usually restricted to global optima of intricate objective functions, it is not clear whether these theories really explain the performances of actual outputs of neural-network pipelines. The goal of this paper is, therefore, to bring statistical theory closer to practice. We develop statistical guarantees for simple neural networks that coincide up to logarithmic factors with the global optima but apply to stationary points and the points nearby. These results support the common notion that neural networks do not necessarily need to be optimized globally from a mathematical perspective. More generally, despite being limited to simple neural networks for now, our theories make a step forward in describing the practical properties of neural networks in mathematical terms.
Statistical Guarantees for Regularized Neural Networks
May 30, 2020Neural networks have become standard tools in the analysis of data, but they lack comprehensive mathematical theories. For example, there are very few statistical guarantees for learning neural networks from data, especially for classes of estimators that are used in practice or at least similar to such. In this paper, we develop a general statistical guarantee for estimators that consist of a least-squares term and a regularizer. We then exemplify this guarantee with $\ell_1$-regularization, showing that the corresponding prediction error increases at most sub-linearly in the number of layers and at most logarithmically in the total number of parameters. Our results establish a mathematical basis for regularized estimation of neural networks, and they deepen our mathematical understanding of neural networks and deep learning more generally.
Tuning-free ridge estimators for high-dimensional generalized linear models
Feb 27, 2020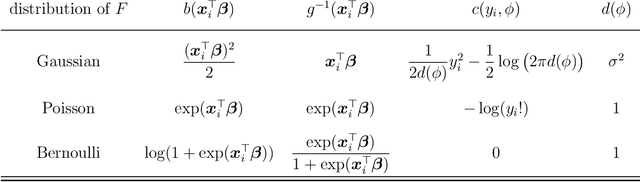
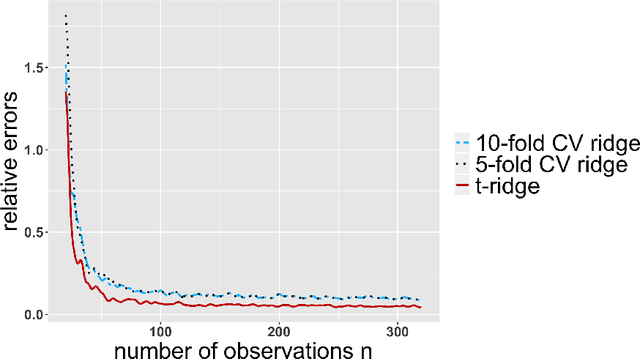
Ridge estimators regularize the squared Euclidean lengths of parameters. Such estimators are mathematically and computationally attractive but involve tuning parameters that can be difficult to calibrate. In this paper, we show that ridge estimators can be modified such that tuning parameters can be avoided altogether. We also show that these modified versions can improve on the empirical prediction accuracies of standard ridge estimators combined with cross-validation, and we provide first theoretical guarantees.