 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM$^3$Searcher: Modular Multimodal Information Seeking Agency with Retrieval-Oriented Reasoning
Jan 14, 2026Recent advances in DeepResearch-style agents have demonstrated strong capabilities in autonomous information acquisition and synthesize from real-world web environments. However, existing approaches remain fundamentally limited to text modality. Extending autonomous information-seeking agents to multimodal settings introduces critical challenges: the specialization-generalization trade-off that emerges when training models for multimodal tool-use at scale, and the severe scarcity of training data capturing complex, multi-step multimodal search trajectories. To address these challenges, we propose M$^3$Searcher, a modular multimodal information-seeking agent that explicitly decouples information acquisition from answer derivation. M$^3$Searcher is optimized with a retrieval-oriented multi-objective reward that jointly encourages factual accuracy, reasoning soundness, and retrieval fidelity. In addition, we develop MMSearchVQA, a multimodal multi-hop dataset to support retrieval centric RL training. Experimental results demonstrate that M$^3$Searcher outperforms existing approaches, exhibits strong transfer adaptability and effective reasoning in complex multimodal tasks.
Addressing Personalized Bias for Unbiased Learning to Rank
Aug 28, 2025Unbiased learning to rank (ULTR), which aims to learn unbiased ranking models from biased user behavior logs, plays an important role in Web search. Previous research on ULTR has studied a variety of biases in users' clicks, such as position bias, presentation bias, and outlier bias. However, existing work often assumes that the behavior logs are collected from an ``average'' user, neglecting the differences between different users in their search and browsing behaviors. In this paper, we introduce personalized factors into the ULTR framework, which we term the user-aware ULTR problem. Through a formal causal analysis of this problem, we demonstrate that existing user-oblivious methods are biased when different users have different preferences over queries and personalized propensities of examining documents. To address such a personalized bias, we propose a novel user-aware inverse-propensity-score estimator for learning-to-rank objectives. Specifically, our approach models the distribution of user browsing behaviors for each query and aggregates user-weighted examination probabilities to determine propensities. We theoretically prove that the user-aware estimator is unbiased under some mild assumptions and shows lower variance compared to the straightforward way of calculating a user-dependent propensity for each impression. Finally, we empirically verify the effectiveness of our user-aware estimator by conducting extensive experiments on two semi-synthetic datasets and a real-world dataset.
PanguIR Technical Report for NTCIR-18 AEOLLM Task
Mar 04, 2025

As large language models (LLMs) gain widespread attention in both academia and industry, it becomes increasingly critical and challenging to effectively evaluate their capabilities. Existing evaluation methods can be broadly categorized into two types: manual evaluation and automatic evaluation. Manual evaluation, while comprehensive, is often costly and resource-intensive. Conversely, automatic evaluation offers greater scalability but is constrained by the limitations of its evaluation criteria (dominated by reference-based answers). To address these challenges, NTCIR-18 introduced the AEOLLM (Automatic Evaluation of LLMs) task, aiming to encourage reference-free evaluation methods that can overcome the limitations of existing approaches. In this paper, to enhance the evaluation performance of the AEOLLM task, we propose three key methods to improve the reference-free evaluation: 1) Multi-model Collaboration: Leveraging multiple LLMs to approximate human ratings across various subtasks; 2) Prompt Auto-optimization: Utilizing LLMs to iteratively refine the initial task prompts based on evaluation feedback from training samples; and 3) In-context Learning (ICL) Optimization: Based on the multi-task evaluation feedback, we train a specialized in-context example retrieval model, combined with a semantic relevance retrieval model, to jointly identify the most effective in-context learning examples. Experiments conducted on the final dataset demonstrate that our approach achieves superior performance on the AEOLLM task.
Mamba Retriever: Utilizing Mamba for Effective and Efficient Dense Retrieval
Aug 15, 2024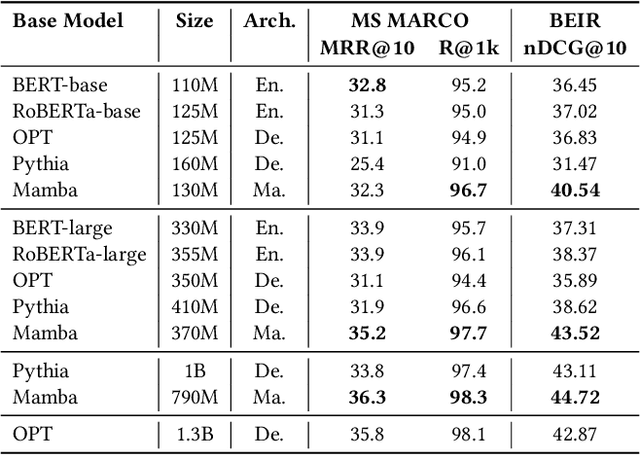
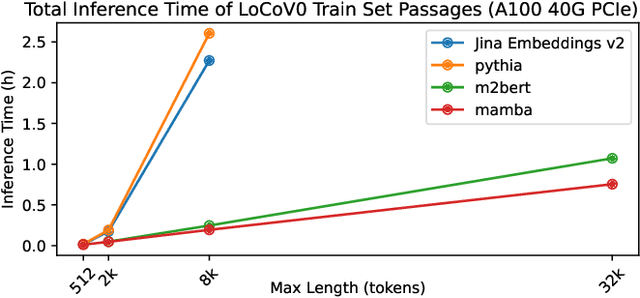

In the information retrieval (IR) area, dense retrieval (DR) models use deep learning techniques to encode queries and passages into embedding space to compute their semantic relations. It is important for DR models to balance both efficiency and effectiveness. Pre-trained language models (PLMs), especially Transformer-based PLMs, have been proven to be effective encoders of DR models. However, the self-attention component in Transformer-based PLM results in a computational complexity that grows quadratically with sequence length, and thus exhibits a slow inference speed for long-text retrieval. Some recently proposed non-Transformer PLMs, especially the Mamba architecture PLMs, have demonstrated not only comparable effectiveness to Transformer-based PLMs on generative language tasks but also better efficiency due to linear time scaling in sequence length. This paper implements the Mamba Retriever to explore whether Mamba can serve as an effective and efficient encoder of DR model for IR tasks. We fine-tune the Mamba Retriever on the classic short-text MS MARCO passage ranking dataset and the long-text LoCoV0 dataset. Experimental results show that (1) on the MS MARCO passage ranking dataset and BEIR, the Mamba Retriever achieves comparable or better effectiveness compared to Transformer-based retrieval models, and the effectiveness grows with the size of the Mamba model; (2) on the long-text LoCoV0 dataset, the Mamba Retriever can extend to longer text length than its pre-trained length after fine-tuning on retrieval task, and it has comparable or better effectiveness compared to other long-text retrieval models; (3) the Mamba Retriever has superior inference speed for long-text retrieval. In conclusion, Mamba Retriever is both effective and efficient, making it a practical model, especially for long-text retrieval.
Mining fMRI Dynamics with Parcellation Prior for Brain Disease Diagnosis
May 04, 2023



To characterize atypical brain dynamics under diseases, prevalent studies investigate functional magnetic resonance imaging (fMRI). However, most of the existing analyses compress rich spatial-temporal information as the brain functional networks (BFNs) and directly investigate the whole-brain network without neurological priors about functional subnetworks. We thus propose a novel graph learning framework to mine fMRI signals with topological priors from brain parcellation for disease diagnosis. Specifically, we 1) detect diagnosis-related temporal features using a "Transformer" for a higher-level BFN construction, and process it with a following graph convolutional network, and 2) apply an attention-based multiple instance learning strategy to emphasize the disease-affected subnetworks to further enhance the diagnosis performance and interpretability. Experiments demonstrate higher effectiveness of our method than compared methods in the diagnosis of early mild cognitive impairment. More importantly, our method is capable of localizing crucial brain subnetworks during the diagnosis, providing insights into the pathogenic source of mild cognitive impairment.