 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccurate 3D Prediction of Missing Teeth in Diverse Patterns for Precise Dental Implant Planning
Jul 16, 2023



In recent years, the demand for dental implants has surged, driven by their high success rates and esthetic advantages. However, accurate prediction of missing teeth for precise digital implant planning remains a challenge due to the intricate nature of dental structures and the variability in tooth loss patterns. This study presents a novel framework for accurate prediction of missing teeth in different patterns, facilitating digital implant planning. The proposed framework begins by estimating point-to-point correspondence among a dataset of dental mesh models reconstructed from CBCT images of healthy subjects. Subsequently, tooth dictionaries are constructed for each tooth type, encoding their position and shape information based on the established point-to-point correspondence. To predict missing teeth in a given dental mesh model, sparse coefficients are learned by sparsely representing adjacent teeth of the missing teeth using the corresponding tooth dictionaries. These coefficients are then applied to the dictionaries of the missing teeth to generate accurate predictions of their positions and shapes. The evaluation results on real subjects shows that our proposed framework achieves an average prediction error of 1.04mm for predictions of single missing tooth and an average prediction error of 1.33mm for the prediction of 14 missing teeth, which demonstrates its capability of accurately predicting missing teeth in various patterns. By accurately predicting missing teeth, dental professionals can improve the planning and placement of dental implants, leading to better esthetic and functional outcomes for patients undergoing dental implant procedures.
Structure-aware registration network for liver DCE-CT images
Mar 08, 2023



Image registration of liver dynamic contrast-enhanced computed tomography (DCE-CT) is crucial for diagnosis and image-guided surgical planning of liver cancer. However, intensity variations due to the flow of contrast agents combined with complex spatial motion induced by respiration brings great challenge to existing intensity-based registration methods. To address these problems, we propose a novel structure-aware registration method by incorporating structural information of related organs with segmentation-guided deep registration network. Existing segmentation-guided registration methods only focus on volumetric registration inside the paired organ segmentations, ignoring the inherent attributes of their anatomical structures. In addition, such paired organ segmentations are not always available in DCE-CT images due to the flow of contrast agents. Different from existing segmentation-guided registration methods, our proposed method extracts structural information in hierarchical geometric perspectives of line and surface. Then, according to the extracted structural information, structure-aware constraints are constructed and imposed on the forward and backward deformation field simultaneously. In this way, all available organ segmentations, including unpaired ones, can be fully utilized to avoid the side effect of contrast agent and preserve the topology of organs during registration. Extensive experiments on an in-house liver DCE-CT dataset and a public LiTS dataset show that our proposed method can achieve higher registration accuracy and preserve anatomical structure more effectively than state-of-the-art methods.
A Novel Unified Conditional Score-based Generative Framework for Multi-modal Medical Image Completion
Jul 07, 2022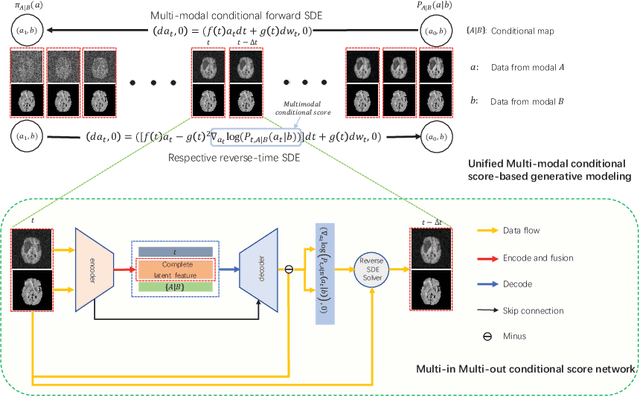
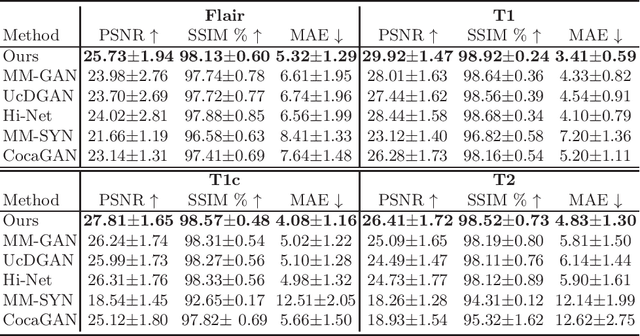
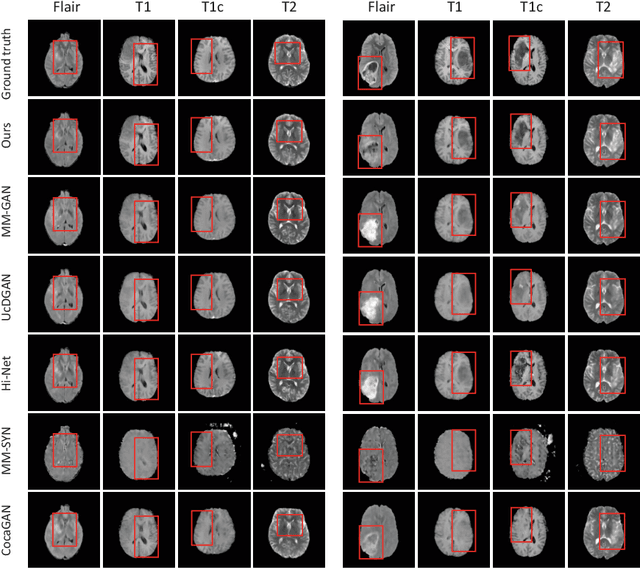
Multi-modal medical image completion has been extensively applied to alleviate the missing modality issue in a wealth of multi-modal diagnostic tasks. However, for most existing synthesis methods, their inferences of missing modalities can collapse into a deterministic mapping from the available ones, ignoring the uncertainties inherent in the cross-modal relationships. Here, we propose the Unified Multi-Modal Conditional Score-based Generative Model (UMM-CSGM) to take advantage of Score-based Generative Model (SGM) in modeling and stochastically sampling a target probability distribution, and further extend SGM to cross-modal conditional synthesis for various missing-modality configurations in a unified framework. Specifically, UMM-CSGM employs a novel multi-in multi-out Conditional Score Network (mm-CSN) to learn a comprehensive set of cross-modal conditional distributions via conditional diffusion and reverse generation in the complete modality space. In this way, the generation process can be accurately conditioned by all available information, and can fit all possible configurations of missing modalities in a single network. Experiments on BraTS19 dataset show that the UMM-CSGM can more reliably synthesize the heterogeneous enhancement and irregular area in tumor-induced lesions for any missing modalities.
Learning towards Synchronous Network Memorizability and Generalizability for Continual Segmentation across Multiple Sites
Jun 14, 2022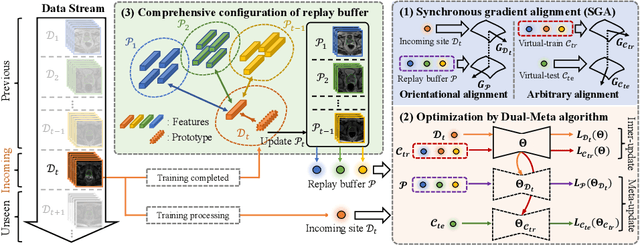
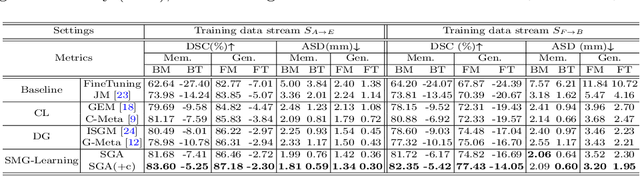
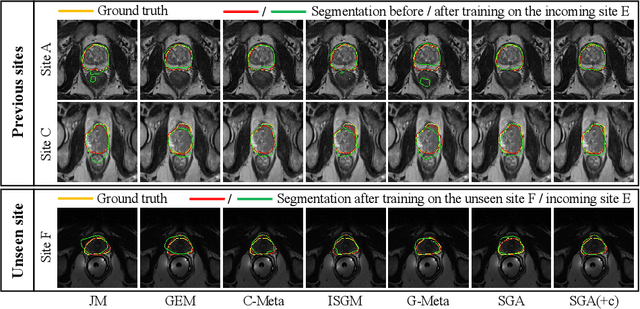
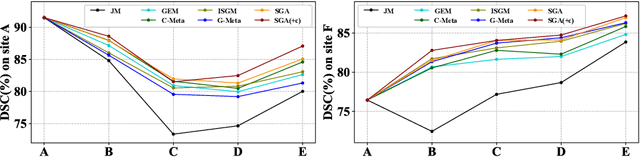
In clinical practice, a segmentation network is often required to continually learn on a sequential data stream from multiple sites rather than a consolidated set, due to the storage cost and privacy restriction. However, during the continual learning process, existing methods are usually restricted in either network memorizability on previous sites or generalizability on unseen sites. This paper aims to tackle the challenging problem of Synchronous Memorizability and Generalizability (SMG) and to simultaneously improve performance on both previous and unseen sites, with a novel proposed SMG-learning framework. First, we propose a Synchronous Gradient Alignment (SGA) objective, which \emph{not only} promotes the network memorizability by enforcing coordinated optimization for a small exemplar set from previous sites (called replay buffer), \emph{but also} enhances the generalizability by facilitating site-invariance under simulated domain shift. Second, to simplify the optimization of SGA objective, we design a Dual-Meta algorithm that approximates the SGA objective as dual meta-objectives for optimization without expensive computation overhead. Third, for efficient rehearsal, we configure the replay buffer comprehensively considering additional inter-site diversity to reduce redundancy. Experiments on prostate MRI data sequentially acquired from six institutes demonstrate that our method can simultaneously achieve higher memorizability and generalizability over state-of-the-art methods. Code is available at https://github.com/jingyzhang/SMG-Learning.