 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiPC: Bidirectional Probability Calibration for Unsupervised Domain Adaption
Sep 29, 2024Unsupervised Domain Adaptation (UDA) leverages a labeled source domain to solve tasks in an unlabeled target domain. While Transformer-based methods have shown promise in UDA, their application is limited to plain Transformers, excluding Convolutional Neural Networks (CNNs) and hierarchical Transformers. To address this issues, we propose Bidirectional Probability Calibration (BiPC) from a probability space perspective. We demonstrate that the probability outputs from a pre-trained head, after extensive pre-training, are robust against domain gaps and can adjust the probability distribution of the task head. Moreover, the task head can enhance the pre-trained head during adaptation training, improving model performance through bidirectional complementation. Technically, we introduce Calibrated Probability Alignment (CPA) to adjust the pre-trained head's probabilities, such as those from an ImageNet-1k pre-trained classifier. Additionally, we design a Calibrated Gini Impurity (CGI) loss to refine the task head, with calibrated coefficients learned from the pre-trained classifier. BiPC is a simple yet effective method applicable to various networks, including CNNs and Transformers. Experimental results demonstrate its remarkable performance across multiple UDA tasks. Our code will be available at: https://github.com/Wenlve-Zhou/BiPC.
Improve Cross-domain Mixed Sampling with Guidance Training for Adaptive Segmentation
Mar 22, 2024Unsupervised Domain Adaptation (UDA) endeavors to adjust models trained on a source domain to perform well on a target domain without requiring additional annotations. In the context of domain adaptive semantic segmentation, which tackles UDA for dense prediction, the goal is to circumvent the need for costly pixel-level annotations. Typically, various prevailing methods baseline rely on constructing intermediate domains via cross-domain mixed sampling techniques to mitigate the performance decline caused by domain gaps. However, such approaches generate synthetic data that diverge from real-world distributions, potentially leading the model astray from the true target distribution. To address this challenge, we propose a novel auxiliary task called Guidance Training. This task facilitates the effective utilization of cross-domain mixed sampling techniques while mitigating distribution shifts from the real world. Specifically, Guidance Training guides the model to extract and reconstruct the target-domain feature distribution from mixed data, followed by decoding the reconstructed target-domain features to make pseudo-label predictions. Importantly, integrating Guidance Training incurs minimal training overhead and imposes no additional inference burden. We demonstrate the efficacy of our approach by integrating it with existing methods, consistently improving performance. The implementation will be available at https://github.com/Wenlve-Zhou/Guidance-Training.
LBL: Logarithmic Barrier Loss Function for One-class Classification
Jul 20, 2023



One-class classification (OCC) aims to train a classifier only with the target class data and attracts great attention for its strong applicability in real-world application. Despite a lot of advances have been made in OCC, it still lacks the effective OCC loss functions for deep learning. In this paper, a novel logarithmic barrier function based OCC loss (LBL) that assigns large gradients to the margin samples and thus derives more compact hypersphere, is first proposed by approximating the OCC objective smoothly. But the optimization of LBL may be instability especially when samples lie on the boundary leading to the infinity loss. To address this issue, then, a unilateral relaxation Sigmoid function is introduced into LBL and a novel OCC loss named LBLSig is proposed. The LBLSig can be seen as the fusion of the mean square error (MSE) and the cross entropy (CE) and the optimization of LBLSig is smoother owing to the unilateral relaxation Sigmoid function. The effectiveness of the proposed LBL and LBLSig is experimentally demonstrated in comparisons with several state-of-the-art OCC algorithms on different network structures. The source code can be found at https://github.com/ML-HDU/LBL_LBLSig.
Self-Annotated Training for Controllable Image Captioning
Oct 16, 2021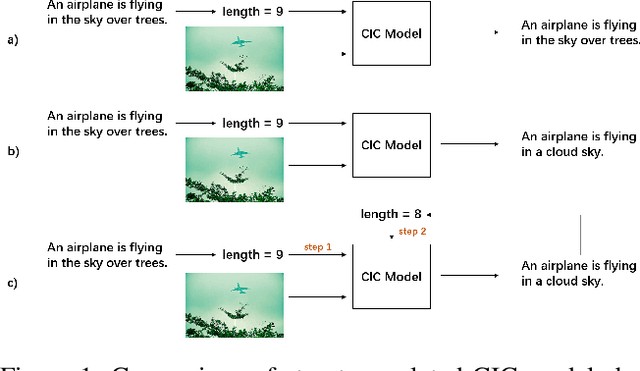
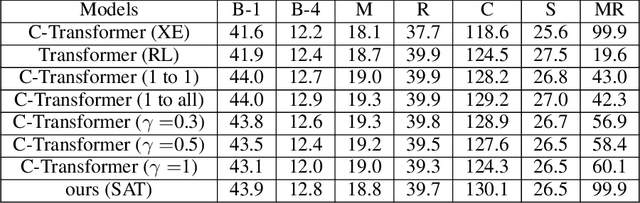
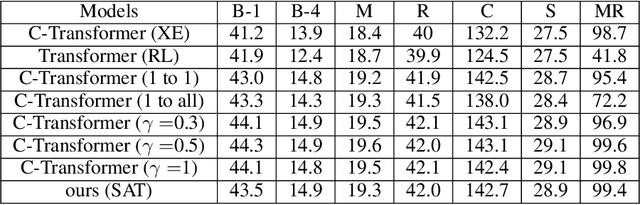
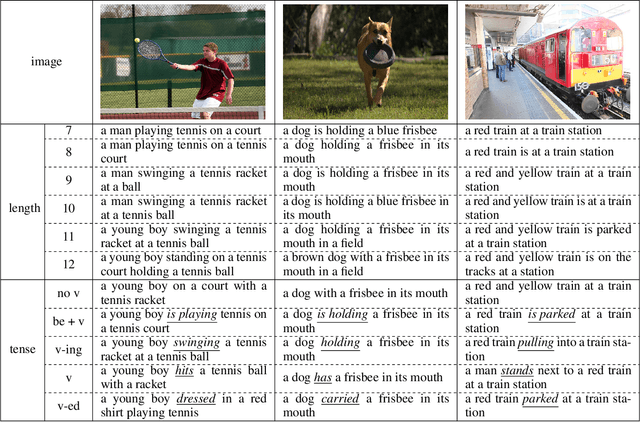
The Controllable Image Captioning (CIC) task aims to generate captions conditioned on designated control signals. In this paper, we improve CIC from two aspects: 1) Existing reinforcement training methods are not applicable to structure-related CIC models due to the fact that the accuracy-based reward focuses mainly on contents rather than semantic structures. The lack of reinforcement training prevents the model from generating more accurate and controllable sentences. To solve the problem above, we propose a novel reinforcement training method for structure-related CIC models: Self-Annotated Training (SAT), where a recursive sampling mechanism (RSM) is designed to force the input control signal to match the actual output sentence. Extensive experiments conducted on MSCOCO show that our SAT method improves C-Transformer (XE) on CIDEr-D score from 118.6 to 130.1 in the length-control task and from 132.2 to 142.7 in the tense-control task, while maintaining more than 99$\%$ matching accuracy with the control signal. 2) We introduce a new control signal: sentence quality. Equipped with it, CIC models are able to generate captions of different quality levels as needed. Experiments show that without additional information of ground truth captions, models controlled by the highest level of sentence quality perform much better in accuracy than baseline models.
Macroscopic Control of Text Generation for Image Captioning
Jan 20, 2021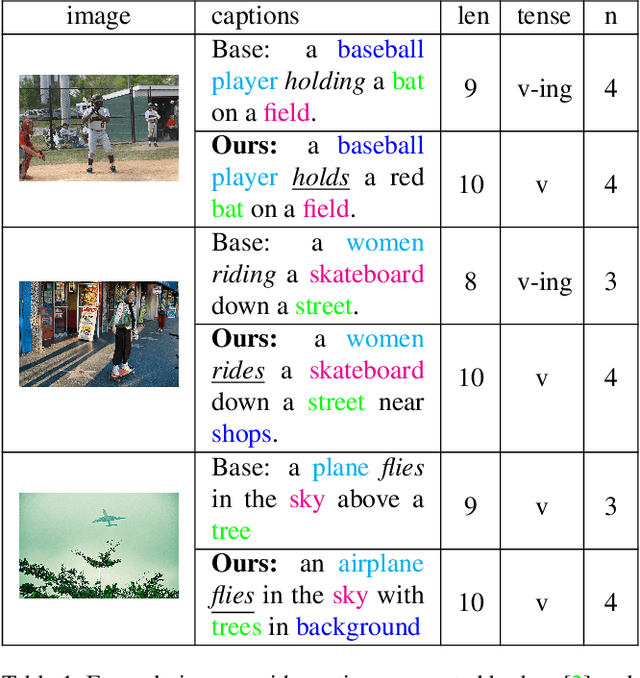
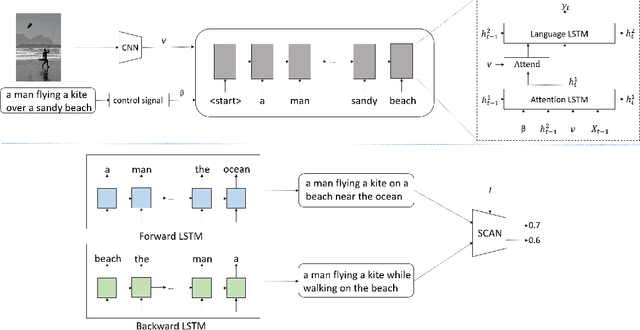

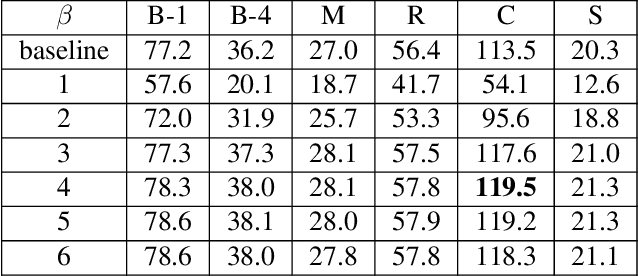
Despite the fact that image captioning models have been able to generate impressive descriptions for a given image, challenges remain: (1) the controllability and diversity of existing models are still far from satisfactory; (2) models sometimes may produce extremely poor-quality captions. In this paper, two novel methods are introduced to solve the problems respectively. Specifically, for the former problem, we introduce a control signal which can control the macroscopic sentence attributes, such as sentence quality, sentence length, sentence tense and number of nouns etc. With such a control signal, the controllability and diversity of existing captioning models are enhanced. For the latter problem, we innovatively propose a strategy that an image-text matching model is trained to measure the quality of sentences generated in both forward and backward directions and finally choose the better one. As a result, this strategy can effectively reduce the proportion of poorquality sentences. Our proposed methods can be easily applie on most image captioning models to improve their overall performance. Based on the Up-Down model, the experimental results show that our methods achieve BLEU- 4/CIDEr/SPICE scores of 37.5/120.3/21.5 on MSCOCO Karpathy test split with cross-entropy training, which surpass the results of other state-of-the-art methods trained by cross-entropy loss.