 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge1st Place Solution to ECCV 2022 Challenge on Out of Vocabulary Scene Text Understanding: Cropped Word Recognition
Aug 04, 2022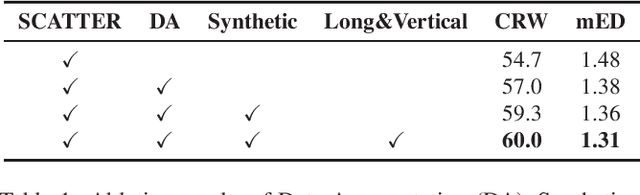

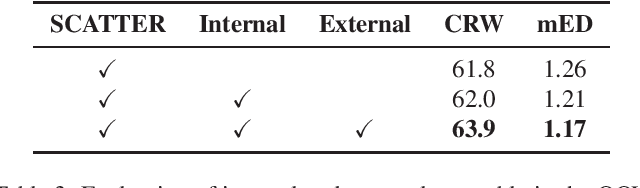

This report presents our winner solution to ECCV 2022 challenge on Out-of-Vocabulary Scene Text Understanding (OOV-ST) : Cropped Word Recognition. This challenge is held in the context of ECCV 2022 workshop on Text in Everything (TiE), which aims to extract out-of-vocabulary words from natural scene images. In the competition, we first pre-train SCATTER on the synthetic datasets, then fine-tune the model on the training set with data augmentations. Meanwhile, two additional models are trained specifically for long and vertical texts. Finally, we combine the output from different models with different layers, different backbones, and different seeds as the final results. Our solution achieves an overall word accuracy of 69.73% when considering both in-vocabulary and out-of-vocabulary words.
Improving Image Captioning with Control Signal of Sentence Quality
Jun 07, 2022

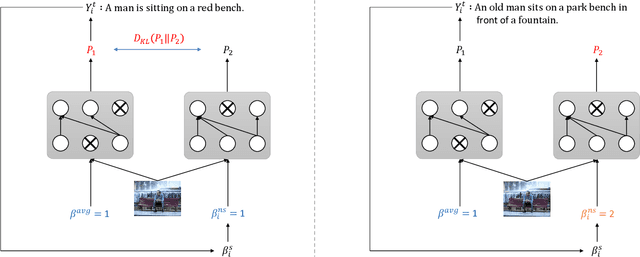
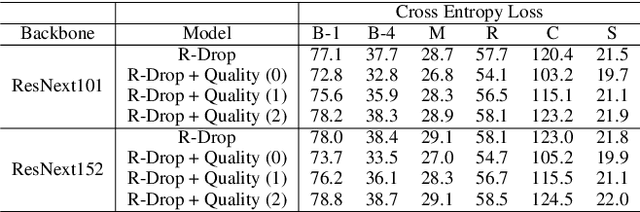
In the dataset of image captioning, each image is aligned with several captions. Despite the fact that the quality of these descriptions varies, existing captioning models treat them equally in the training process. In this paper, we propose a new control signal of sentence quality, which is taken as an additional input to the captioning model. By integrating the control signal information, captioning models are aware of the quality level of the target sentences and handle them differently. Moreover, we propose a novel reinforcement training method specially designed for the control signal of sentence quality: Quality-oriented Self-Annotated Training (Q-SAT). Equipped with R-Drop strategy, models controlled by the highest quality level surpass baseline models a lot on accuracy-based evaluation metrics, which validates the effectiveness of our proposed methods.
Self-Annotated Training for Controllable Image Captioning
Oct 16, 2021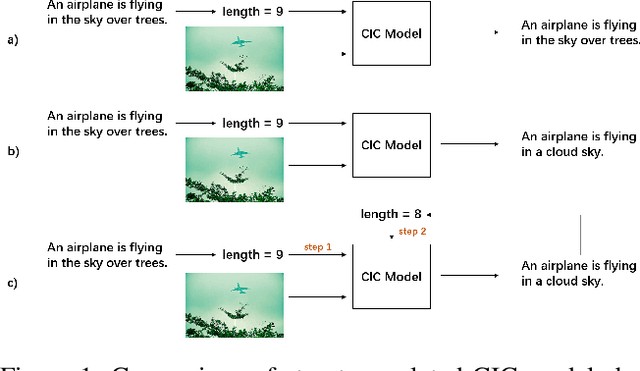
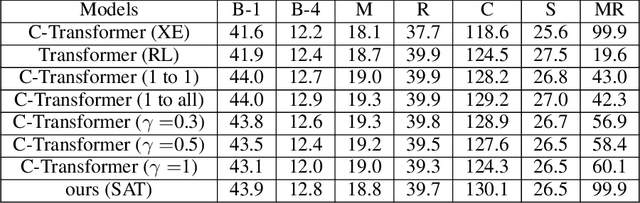
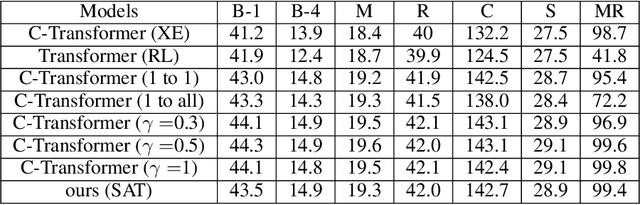
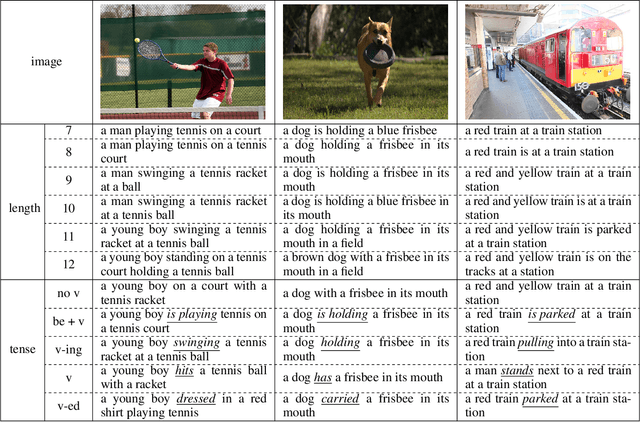
The Controllable Image Captioning (CIC) task aims to generate captions conditioned on designated control signals. In this paper, we improve CIC from two aspects: 1) Existing reinforcement training methods are not applicable to structure-related CIC models due to the fact that the accuracy-based reward focuses mainly on contents rather than semantic structures. The lack of reinforcement training prevents the model from generating more accurate and controllable sentences. To solve the problem above, we propose a novel reinforcement training method for structure-related CIC models: Self-Annotated Training (SAT), where a recursive sampling mechanism (RSM) is designed to force the input control signal to match the actual output sentence. Extensive experiments conducted on MSCOCO show that our SAT method improves C-Transformer (XE) on CIDEr-D score from 118.6 to 130.1 in the length-control task and from 132.2 to 142.7 in the tense-control task, while maintaining more than 99$\%$ matching accuracy with the control signal. 2) We introduce a new control signal: sentence quality. Equipped with it, CIC models are able to generate captions of different quality levels as needed. Experiments show that without additional information of ground truth captions, models controlled by the highest level of sentence quality perform much better in accuracy than baseline models.
Macroscopic Control of Text Generation for Image Captioning
Jan 20, 2021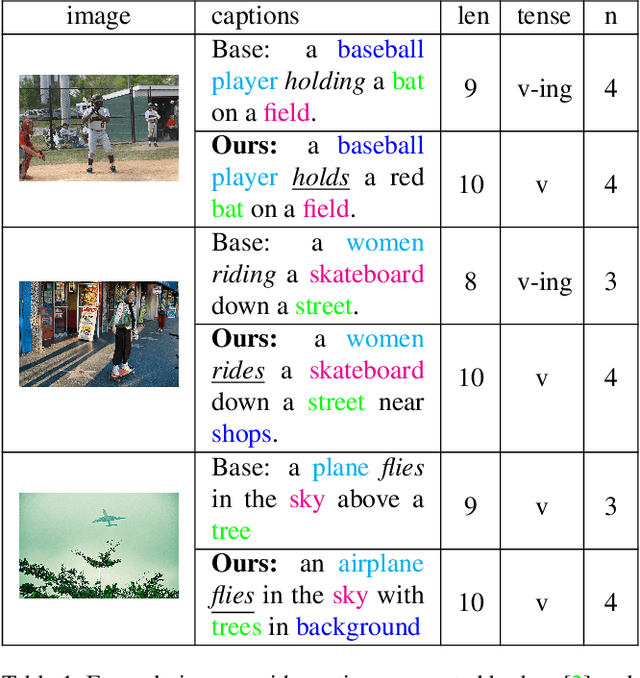
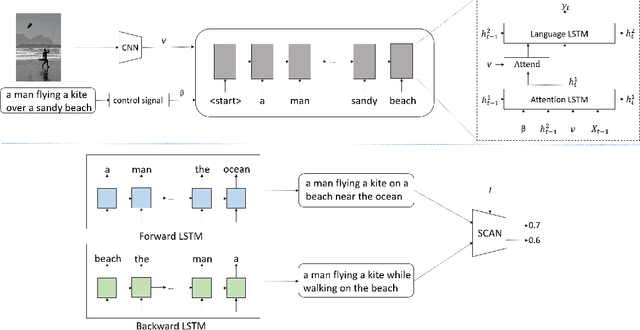

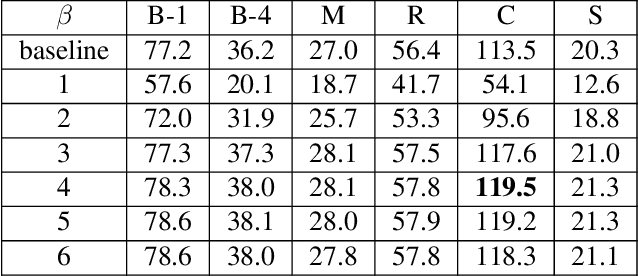
Despite the fact that image captioning models have been able to generate impressive descriptions for a given image, challenges remain: (1) the controllability and diversity of existing models are still far from satisfactory; (2) models sometimes may produce extremely poor-quality captions. In this paper, two novel methods are introduced to solve the problems respectively. Specifically, for the former problem, we introduce a control signal which can control the macroscopic sentence attributes, such as sentence quality, sentence length, sentence tense and number of nouns etc. With such a control signal, the controllability and diversity of existing captioning models are enhanced. For the latter problem, we innovatively propose a strategy that an image-text matching model is trained to measure the quality of sentences generated in both forward and backward directions and finally choose the better one. As a result, this strategy can effectively reduce the proportion of poorquality sentences. Our proposed methods can be easily applie on most image captioning models to improve their overall performance. Based on the Up-Down model, the experimental results show that our methods achieve BLEU- 4/CIDEr/SPICE scores of 37.5/120.3/21.5 on MSCOCO Karpathy test split with cross-entropy training, which surpass the results of other state-of-the-art methods trained by cross-entropy loss.