 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Annotated Training for Controllable Image Captioning
Paper and Code
Oct 16, 2021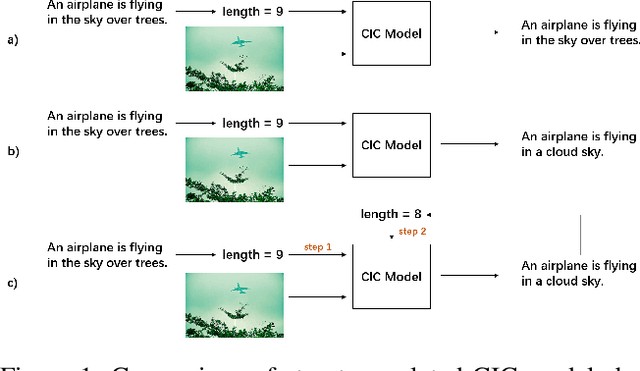
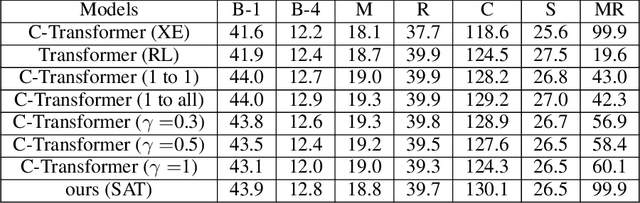
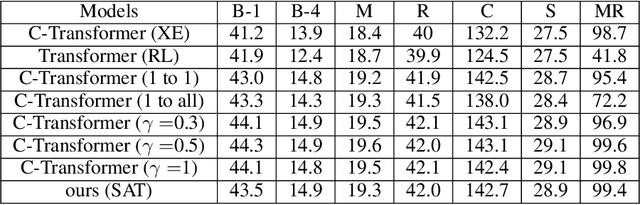
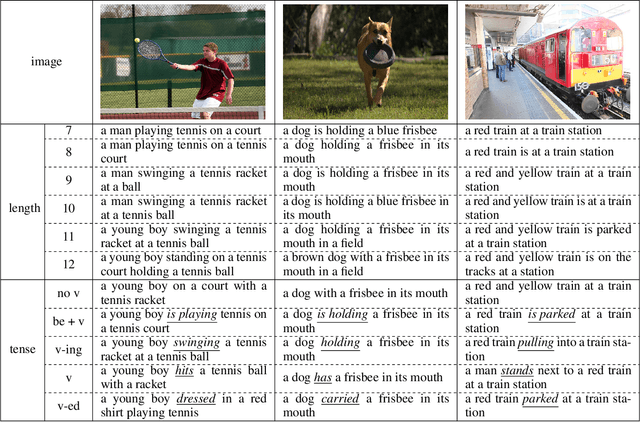
The Controllable Image Captioning (CIC) task aims to generate captions conditioned on designated control signals. In this paper, we improve CIC from two aspects: 1) Existing reinforcement training methods are not applicable to structure-related CIC models due to the fact that the accuracy-based reward focuses mainly on contents rather than semantic structures. The lack of reinforcement training prevents the model from generating more accurate and controllable sentences. To solve the problem above, we propose a novel reinforcement training method for structure-related CIC models: Self-Annotated Training (SAT), where a recursive sampling mechanism (RSM) is designed to force the input control signal to match the actual output sentence. Extensive experiments conducted on MSCOCO show that our SAT method improves C-Transformer (XE) on CIDEr-D score from 118.6 to 130.1 in the length-control task and from 132.2 to 142.7 in the tense-control task, while maintaining more than 99$\%$ matching accuracy with the control signal. 2) We introduce a new control signal: sentence quality. Equipped with it, CIC models are able to generate captions of different quality levels as needed. Experiments show that without additional information of ground truth captions, models controlled by the highest level of sentence quality perform much better in accuracy than baseline models.