 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial-information Guided Adaptive Context-aware Network for Efficient RGB-D Semantic Segmentation
Aug 11, 2023



Efficient RGB-D semantic segmentation has received considerable attention in mobile robots, which plays a vital role in analyzing and recognizing environmental information. According to previous studies, depth information can provide corresponding geometric relationships for objects and scenes, but actual depth data usually exist as noise. To avoid unfavorable effects on segmentation accuracy and computation, it is necessary to design an efficient framework to leverage cross-modal correlations and complementary cues. In this paper, we propose an efficient lightweight encoder-decoder network that reduces the computational parameters and guarantees the robustness of the algorithm. Working with channel and spatial fusion attention modules, our network effectively captures multi-level RGB-D features. A globally guided local affinity context module is proposed to obtain sufficient high-level context information. The decoder utilizes a lightweight residual unit that combines short- and long-distance information with a few redundant computations. Experimental results on NYUv2, SUN RGB-D, and Cityscapes datasets show that our method achieves a better trade-off among segmentation accuracy, inference time, and parameters than the state-of-the-art methods. The source code will be at https://github.com/MVME-HBUT/SGACNet
Attention-based Dual Supervised Decoder for RGBD Semantic Segmentation
Jan 05, 2022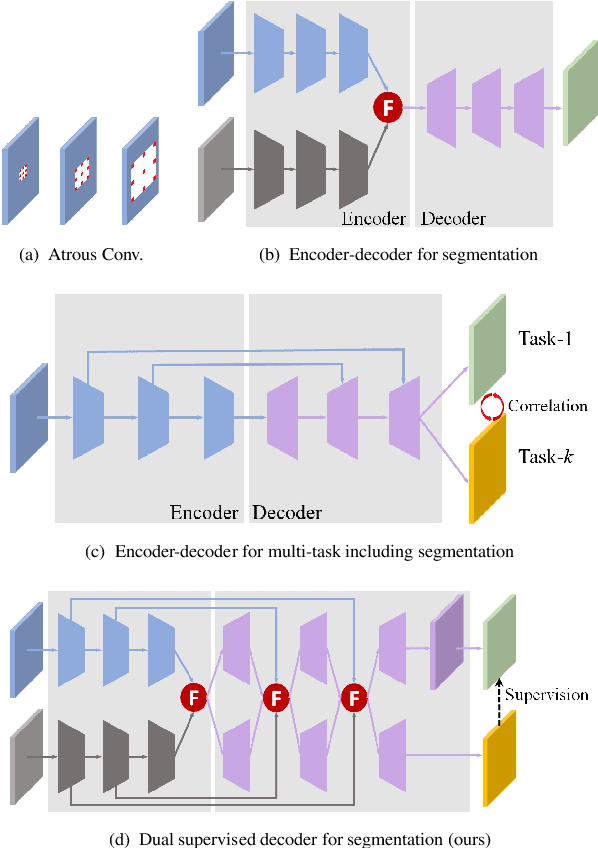
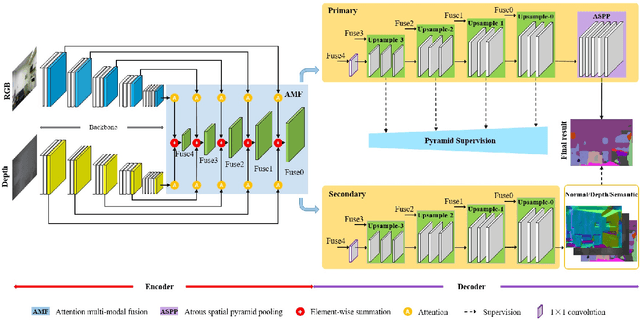

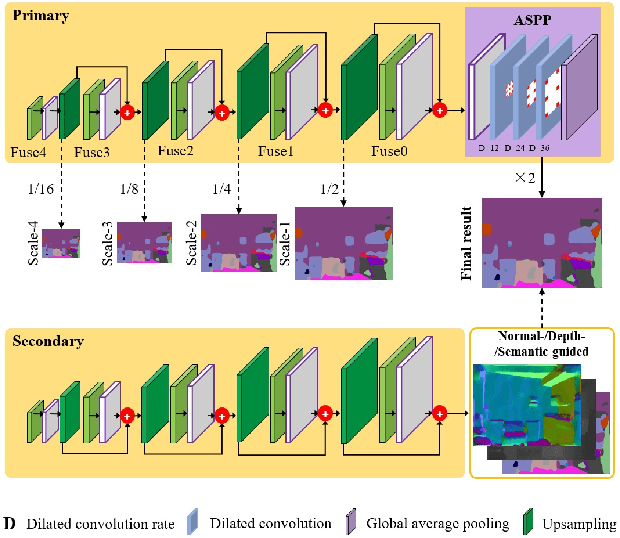
Encoder-decoder models have been widely used in RGBD semantic segmentation, and most of them are designed via a two-stream network. In general, jointly reasoning the color and geometric information from RGBD is beneficial for semantic segmentation. However, most existing approaches fail to comprehensively utilize multimodal information in both the encoder and decoder. In this paper, we propose a novel attention-based dual supervised decoder for RGBD semantic segmentation. In the encoder, we design a simple yet effective attention-based multimodal fusion module to extract and fuse deeply multi-level paired complementary information. To learn more robust deep representations and rich multi-modal information, we introduce a dual-branch decoder to effectively leverage the correlations and complementary cues of different tasks. Extensive experiments on NYUDv2 and SUN-RGBD datasets demonstrate that our method achieves superior performance against the state-of-the-art methods.