 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention-based Dual Supervised Decoder for RGBD Semantic Segmentation
Paper and Code
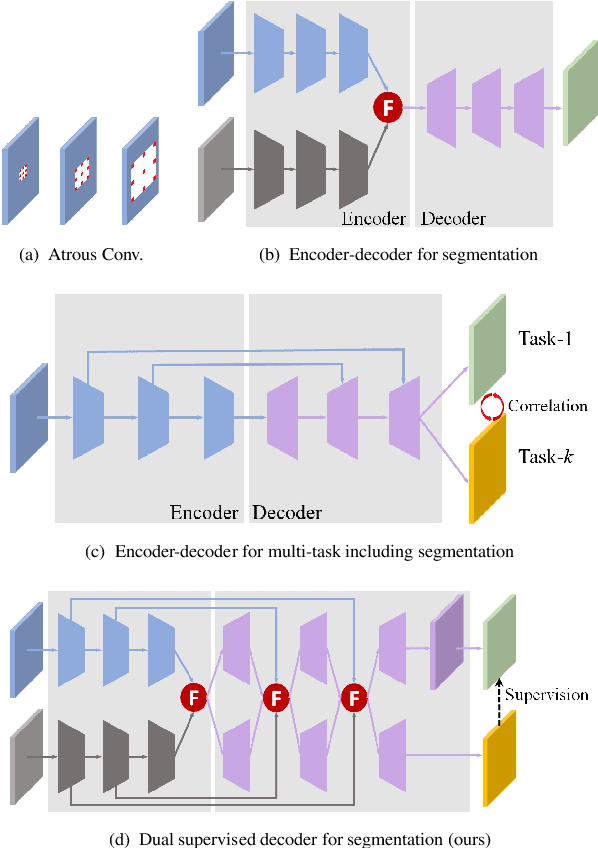
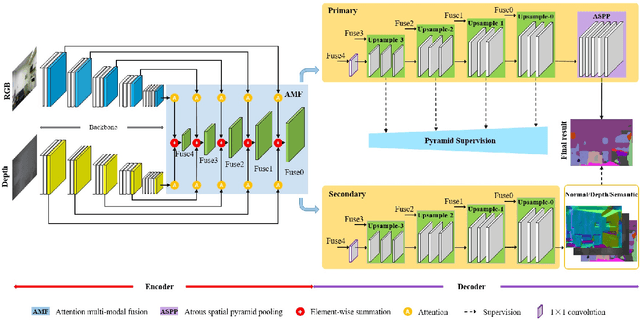

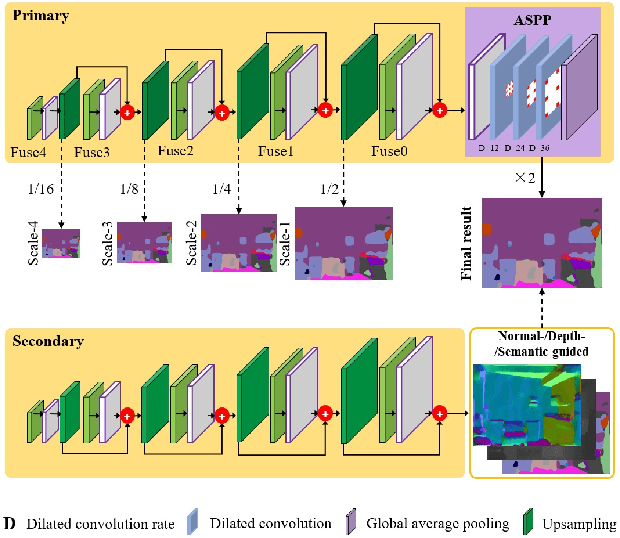
Encoder-decoder models have been widely used in RGBD semantic segmentation, and most of them are designed via a two-stream network. In general, jointly reasoning the color and geometric information from RGBD is beneficial for semantic segmentation. However, most existing approaches fail to comprehensively utilize multimodal information in both the encoder and decoder. In this paper, we propose a novel attention-based dual supervised decoder for RGBD semantic segmentation. In the encoder, we design a simple yet effective attention-based multimodal fusion module to extract and fuse deeply multi-level paired complementary information. To learn more robust deep representations and rich multi-modal information, we introduce a dual-branch decoder to effectively leverage the correlations and complementary cues of different tasks. Extensive experiments on NYUDv2 and SUN-RGBD datasets demonstrate that our method achieves superior performance against the state-of-the-art methods.