 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Crack Detection on Road Pavements Using Encoder Decoder Architecture
Paper and Code
Jul 01, 2020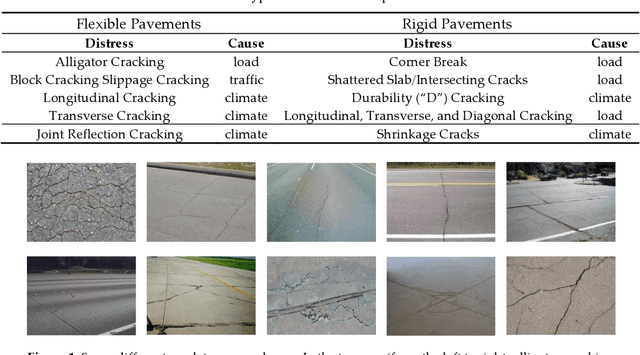
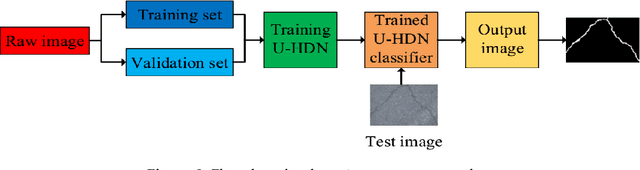
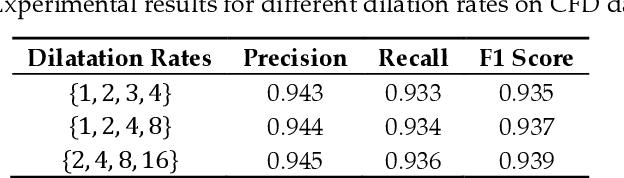
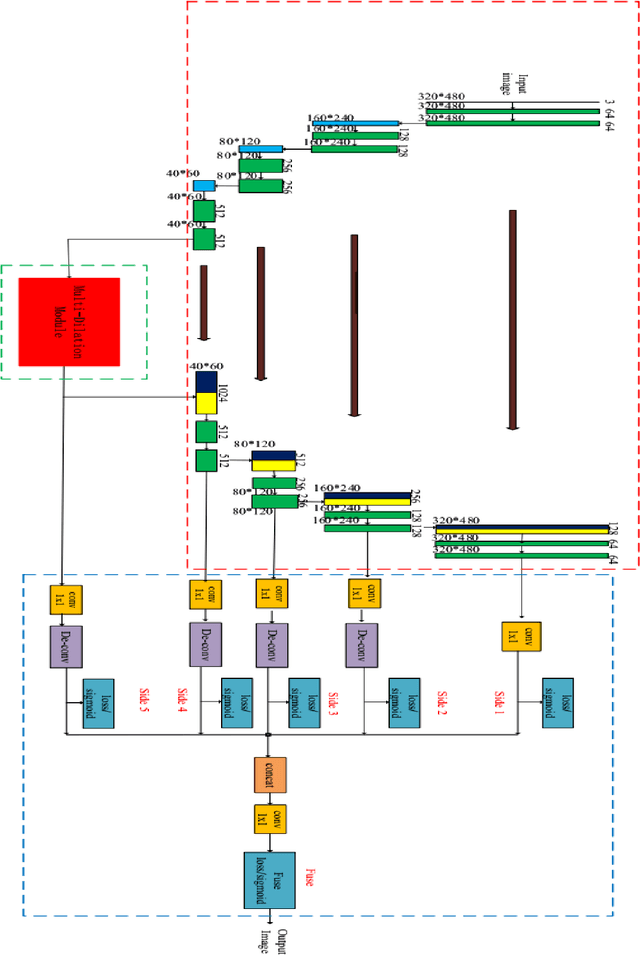
Inspired by the development of deep learning in computer vision and object detection, the proposed algorithm considers an encoder-decoder architecture with hierarchical feature learning and dilated convolution, named U-Hierarchical Dilated Network (U-HDN), to perform crack detection in an end-to-end method. Crack characteristics with multiple context information are automatically able to learn and perform end-to-end crack detection. Then, a multi-dilation module embedded in an encoder-decoder architecture is proposed. The crack features of multiple context sizes can be integrated into the multi-dilation module by dilation convolution with different dilatation rates, which can obtain much more cracks information. Finally, the hierarchical feature learning module is designed to obtain a multi-scale features from the high to low-level convolutional layers, which are integrated to predict pixel-wise crack detection. Some experiments on public crack databases using 118 images were performed and the results were compared with those obtained with other methods on the same images. The results show that the proposed U-HDN method achieves high performance because it can extract and fuse different context sizes and different levels of feature maps than other algorithms.