 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollision Avoidance for Multiple UAVs in Unknown Scenarios with Causal Representation Disentanglement
Jul 04, 2024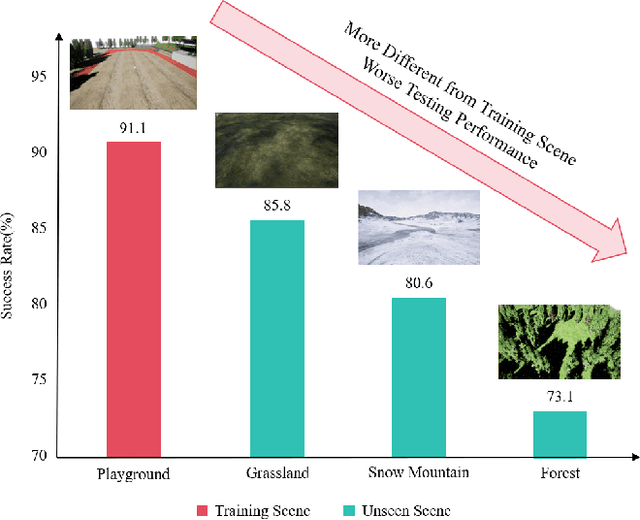



Deep reinforcement learning (DRL) has achieved remarkable progress in online path planning tasks for multi-UAV systems. However, existing DRL-based methods often suffer from performance degradation when tackling unseen scenarios, since the non-causal factors in visual representations adversely affect policy learning. To address this issue, we propose a novel representation learning approach, \ie, causal representation disentanglement, which can identify the causal and non-causal factors in representations. After that, we only pass causal factors for subsequent policy learning and thus explicitly eliminate the influence of non-causal factors, which effectively improves the generalization ability of DRL models. Experimental results show that our proposed method can achieve robust navigation performance and effective collision avoidance especially in unseen scenarios, which significantly outperforms existing SOTA algorithms.
Robust Policy Learning for Multi-UAV Collision Avoidance with Causal Feature Selection
Jul 04, 2024In unseen and complex outdoor environments, collision avoidance navigation for unmanned aerial vehicle (UAV) swarms presents a challenging problem. It requires UAVs to navigate through various obstacles and complex backgrounds. Existing collision avoidance navigation methods based on deep reinforcement learning show promising performance but suffer from poor generalization abilities, resulting in performance degradation in unseen environments. To address this issue, we investigate the cause of weak generalization ability in DRL and propose a novel causal feature selection module. This module can be integrated into the policy network and effectively filters out non-causal factors in representations, thereby reducing the influence of spurious correlations between non-causal factors and action predictions. Experimental results demonstrate that our proposed method can achieve robust navigation performance and effective collision avoidance especially in scenarios with unseen backgrounds and obstacles, which significantly outperforms existing state-of-the-art algorithms.
Why does Stereo Triangulation Not Work in UAV Distance Estimation
Jun 15, 2023



UAV distance estimation plays an important role for path planning of swarm UAVs and collision avoidance. However, the lack of annotated data seriously hinder the related studies. In this paper, we build and present a UAVDE dataset for UAV distance estimation, in which distance between two UAVs is obtained by UWB sensors. During experiments, we surprisingly observe that the commonly used stereo triangulation can not stand for UAV scenes. The core reason is the position deviation issue of UAVs due to long shooting distance and camera vibration, which is common in UAV scenes. To tackle this issue, we propose a novel position correction module (PCM), which can directly predict the offset between the image positions and the actual ones of UAVs and perform calculation compensation in stereo triangulation. Besides, to further boost performance on hard samples, we propose a dynamic iterative correction mechanism, which is composed of multiple stacked PCMs and a gating mechanism to adaptively determine whether further correction is required according to the difficulty of data samples. Consequently, the position deviation issue can be effectively alleviated. We conduct extensive experiments on UAVDE, and our proposed method can achieve a 38.84% performance improvement, which demonstrates its effectiveness and superiority. The code and dataset would be released.
Video Semantic Segmentation with Inter-Frame Feature Fusion and Inner-Frame Feature Refinement
Jan 10, 2023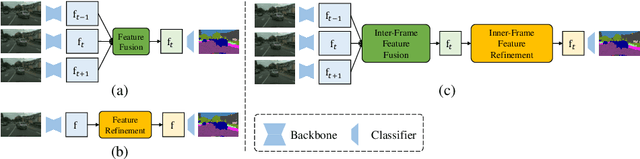



Video semantic segmentation aims to generate accurate semantic maps for each video frame. To this end, many works dedicate to integrate diverse information from consecutive frames to enhance the features for prediction, where a feature alignment procedure via estimated optical flow is usually required. However, the optical flow would inevitably suffer from inaccuracy, and then introduce noises in feature fusion and further result in unsatisfactory segmentation results. In this paper, to tackle the misalignment issue, we propose a spatial-temporal fusion (STF) module to model dense pairwise relationships among multi-frame features. Different from previous methods, STF uniformly and adaptively fuses features at different spatial and temporal positions, and avoids error-prone optical flow estimation. Besides, we further exploit feature refinement within a single frame and propose a novel memory-augmented refinement (MAR) module to tackle difficult predictions among semantic boundaries. Specifically, MAR can store the boundary features and prototypes extracted from the training samples, which together form the task-specific memory, and then use them to refine the features during inference. Essentially, MAR can move the hard features closer to the most likely category and thus make them more discriminative. We conduct extensive experiments on Cityscapes and CamVid, and the results show that our proposed methods significantly outperform previous methods and achieves the state-of-the-art performance. Code and pretrained models are available at https://github.com/jfzhuang/ST_Memory.
5th Place Solution for VSPW 2021 Challenge
Dec 13, 2021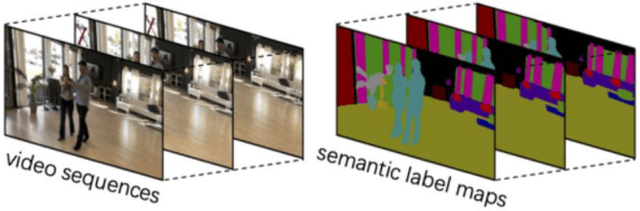
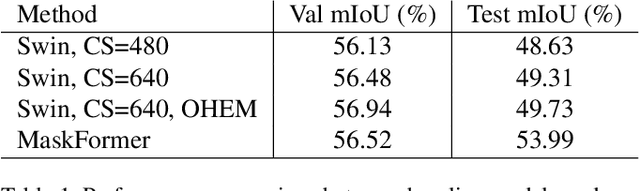

In this article, we introduce the solution we used in the VSPW 2021 Challenge. Our experiments are based on two baseline models, Swin Transformer and MaskFormer. To further boost performance, we adopt stochastic weight averaging technique and design hierarchical ensemble strategy. Without using any external semantic segmentation dataset, our solution ranked the 5th place in the private leaderboard. Besides, we have some interesting attempts to tackle long-tail recognition and overfitting issues, which achieves improvement on val subset. Maybe due to distribution difference, these attempts don't work on test subset. We will also introduce these attempts and hope to inspire other researchers.
Video Semantic Segmentation with Distortion-Aware Feature Correction
Jun 18, 2020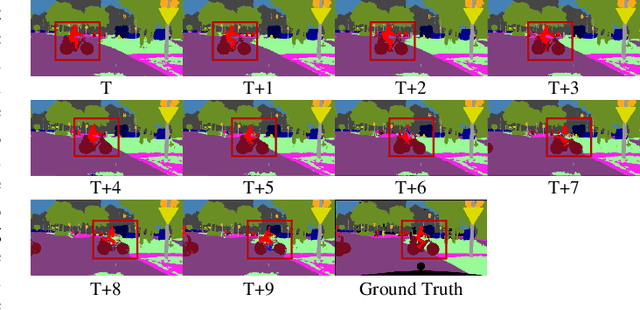
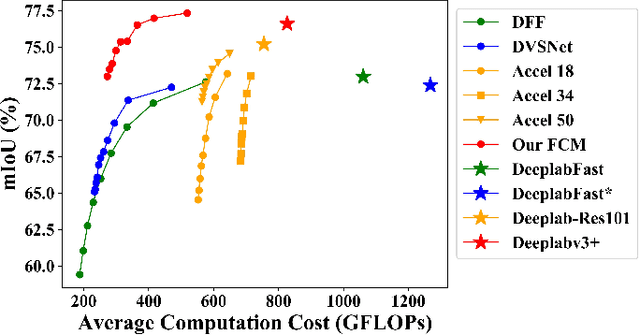
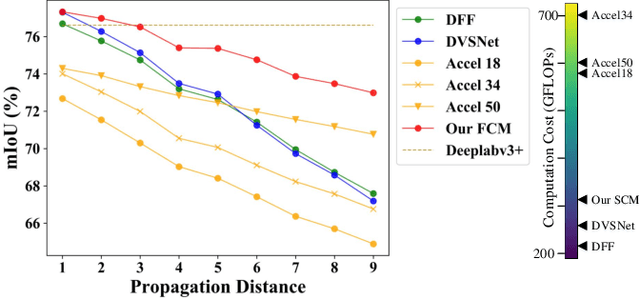
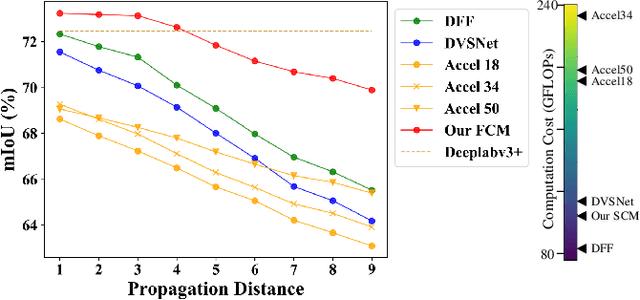
Video semantic segmentation is active in recent years benefited from the great progress of image semantic segmentation. For such a task, the per-frame image segmentation is generally unacceptable in practice due to high computation cost. To tackle this issue, many works use the flow-based feature propagation to reuse the features of previous frames. However, the optical flow estimation inevitably suffers inaccuracy and then causes the propagated features distorted. In this paper, we propose distortion-aware feature correction to alleviate the issue, which improves video segmentation performance by correcting distorted propagated features. To be specific, we firstly propose to transfer distortion patterns from feature into image space and conduct effective distortion map prediction. Benefited from the guidance of distortion maps, we proposed Feature Correction Module (FCM) to rectify propagated features in the distorted areas. Our proposed method can significantly boost the accuracy of video semantic segmentation at a low price. The extensive experimental results on Cityscapes and CamVid show that our method outperforms the recent state-of-the-art methods.