Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge5th Place Solution for VSPW 2021 Challenge
Paper and Code
Dec 13, 2021
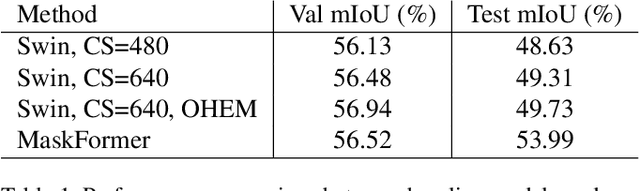

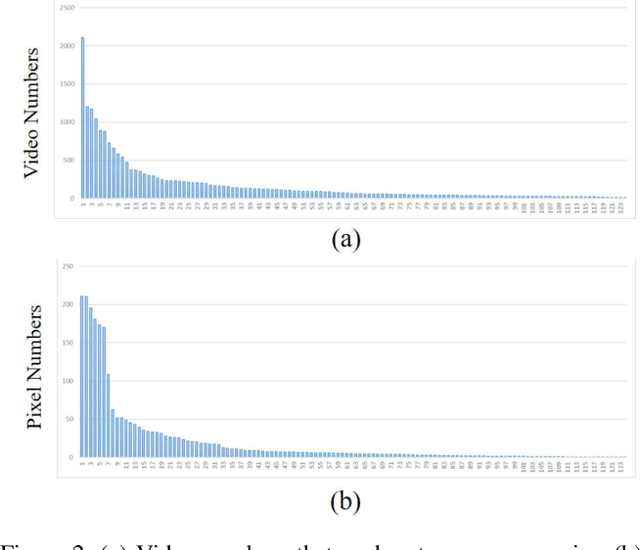
In this article, we introduce the solution we used in the VSPW 2021 Challenge. Our experiments are based on two baseline models, Swin Transformer and MaskFormer. To further boost performance, we adopt stochastic weight averaging technique and design hierarchical ensemble strategy. Without using any external semantic segmentation dataset, our solution ranked the 5th place in the private leaderboard. Besides, we have some interesting attempts to tackle long-tail recognition and overfitting issues, which achieves improvement on val subset. Maybe due to distribution difference, these attempts don't work on test subset. We will also introduce these attempts and hope to inspire other researchers.
* Presented in ICCV'21 Workshop
View paper on