 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Semantic Segmentation with Inter-Frame Feature Fusion and Inner-Frame Feature Refinement
Paper and Code
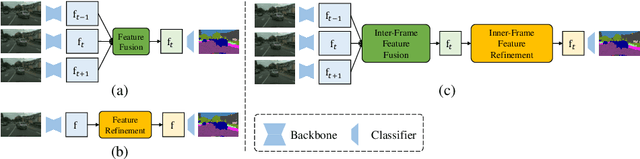



Video semantic segmentation aims to generate accurate semantic maps for each video frame. To this end, many works dedicate to integrate diverse information from consecutive frames to enhance the features for prediction, where a feature alignment procedure via estimated optical flow is usually required. However, the optical flow would inevitably suffer from inaccuracy, and then introduce noises in feature fusion and further result in unsatisfactory segmentation results. In this paper, to tackle the misalignment issue, we propose a spatial-temporal fusion (STF) module to model dense pairwise relationships among multi-frame features. Different from previous methods, STF uniformly and adaptively fuses features at different spatial and temporal positions, and avoids error-prone optical flow estimation. Besides, we further exploit feature refinement within a single frame and propose a novel memory-augmented refinement (MAR) module to tackle difficult predictions among semantic boundaries. Specifically, MAR can store the boundary features and prototypes extracted from the training samples, which together form the task-specific memory, and then use them to refine the features during inference. Essentially, MAR can move the hard features closer to the most likely category and thus make them more discriminative. We conduct extensive experiments on Cityscapes and CamVid, and the results show that our proposed methods significantly outperform previous methods and achieves the state-of-the-art performance. Code and pretrained models are available at https://github.com/jfzhuang/ST_Memory.