 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying Language-Action Understanding and Generation for Autonomous Driving
Mar 02, 2026Vision-Language-Action (VLA) models are emerging as a promising paradigm for end-to-end autonomous driving, valued for their potential to leverage world knowledge and reason about complex driving scenes. However, existing methods suffer from two critical limitations: a persistent misalignment between language instructions and action outputs, and the inherent inefficiency of typical auto-regressive action generation. In this paper, we introduce LinkVLA, a novel architecture that directly addresses these challenges to enhance both alignment and efficiency. First, we establish a structural link by unifying language and action tokens into a shared discrete codebook, processed within a single multi-modal model. This structurally enforces cross-modal consistency from the ground up. Second, to create a deep semantic link, we introduce an auxiliary action understanding objective that trains the model to generate descriptive captions from trajectories, fostering a bidirectional language-action mapping. Finally, we replace the slow, step-by-step generation with a two-step coarse-to-fine generation method C2F that efficiently decodes the action sequence, saving 86% inference time. Experiments on closed-loop driving benchmarks show consistent gains in instruction following accuracy and driving performance, alongside reduced inference latency.
MTDrive: Multi-turn Interactive Reinforcement Learning for Autonomous Driving
Jan 30, 2026Trajectory planning is a core task in autonomous driving, requiring the prediction of safe and comfortable paths across diverse scenarios. Integrating Multi-modal Large Language Models (MLLMs) with Reinforcement Learning (RL) has shown promise in addressing "long-tail" scenarios. However, existing methods are constrained to single-turn reasoning, limiting their ability to handle complex tasks requiring iterative refinement. To overcome this limitation, we present MTDrive, a multi-turn framework that enables MLLMs to iteratively refine trajectories based on environmental feedback. MTDrive introduces Multi-Turn Group Relative Policy Optimization (mtGRPO), which mitigates reward sparsity by computing relative advantages across turns. We further construct an interactive trajectory understanding dataset from closed-loop simulation to support multi-turn training. Experiments on the NAVSIM benchmark demonstrate superior performance compared to existing methods, validating the effectiveness of our multi-turn reasoning paradigm. Additionally, we implement system-level optimizations to reduce data transfer overhead caused by high-resolution images and multi-turn sequences, achieving 2.5x training throughput. Our data, models, and code will be made available soon.
The Better You Learn, The Smarter You Prune: Towards Efficient Vision-language-action Models via Differentiable Token Pruning
Sep 16, 2025We present LightVLA, a simple yet effective differentiable token pruning framework for vision-language-action (VLA) models. While VLA models have shown impressive capability in executing real-world robotic tasks, their deployment on resource-constrained platforms is often bottlenecked by the heavy attention-based computation over large sets of visual tokens. LightVLA addresses this challenge through adaptive, performance-driven pruning of visual tokens: It generates dynamic queries to evaluate visual token importance, and adopts Gumbel softmax to enable differentiable token selection. Through fine-tuning, LightVLA learns to preserve the most informative visual tokens while pruning tokens which do not contribute to task execution, thereby improving efficiency and performance simultaneously. Notably, LightVLA requires no heuristic magic numbers and introduces no additional trainable parameters, making it compatible with modern inference frameworks. Experimental results demonstrate that LightVLA outperforms different VLA models and existing token pruning methods across diverse tasks on the LIBERO benchmark, achieving higher success rates with substantially reduced computational overhead. Specifically, LightVLA reduces FLOPs and latency by 59.1% and 38.2% respectively, with a 2.9% improvement in task success rate. Meanwhile, we also investigate the learnable query-based token pruning method LightVLA* with additional trainable parameters, which also achieves satisfactory performance. Our work reveals that as VLA pursues optimal performance, LightVLA spontaneously learns to prune tokens from a performance-driven perspective. To the best of our knowledge, LightVLA is the first work to apply adaptive visual token pruning to VLA tasks with the collateral goals of efficiency and performance, marking a significant step toward more efficient, powerful and practical real-time robotic systems.
DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models
Feb 25, 2024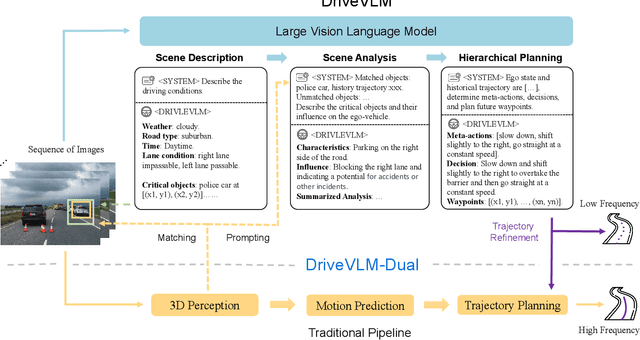
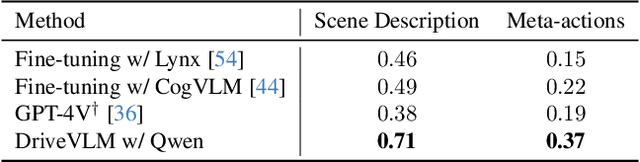
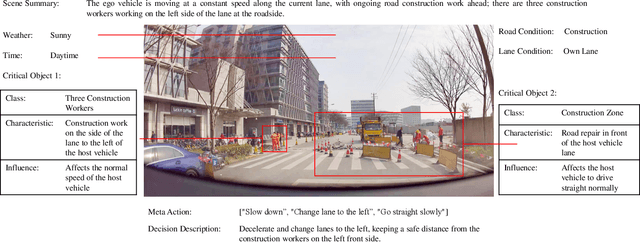
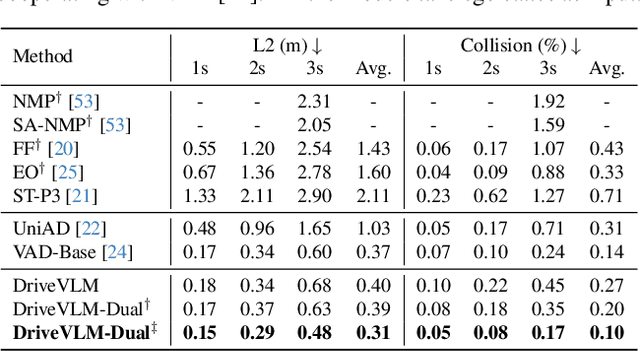
A primary hurdle of autonomous driving in urban environments is understanding complex and long-tail scenarios, such as challenging road conditions and delicate human behaviors. We introduce DriveVLM, an autonomous driving system leveraging Vision-Language Models (VLMs) for enhanced scene understanding and planning capabilities. DriveVLM integrates a unique combination of chain-of-thought (CoT) modules for scene description, scene analysis, and hierarchical planning. Furthermore, recognizing the limitations of VLMs in spatial reasoning and heavy computational requirements, we propose DriveVLM-Dual, a hybrid system that synergizes the strengths of DriveVLM with the traditional autonomous driving pipeline. DriveVLM-Dual achieves robust spatial understanding and real-time inference speed. Extensive experiments on both the nuScenes dataset and our SUP-AD dataset demonstrate the effectiveness of DriveVLM and the enhanced performance of DriveVLM-Dual, surpassing existing methods in complex and unpredictable driving conditions.
Knowledge-Routed Visual Question Reasoning: Challenges for Deep Representation Embedding
Dec 14, 2020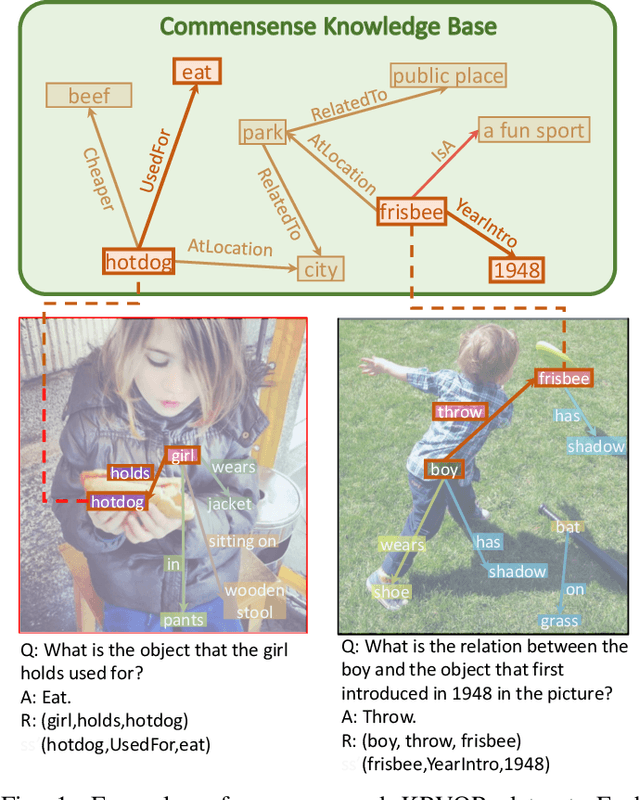
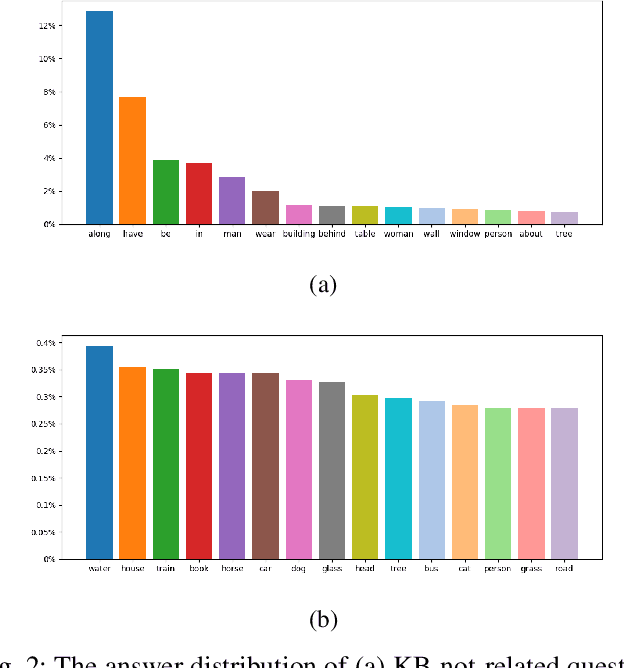
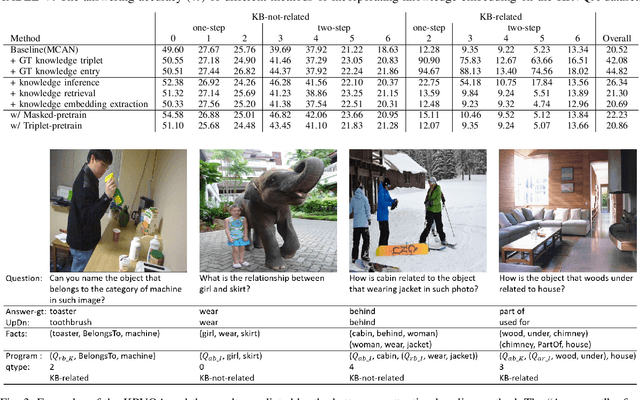
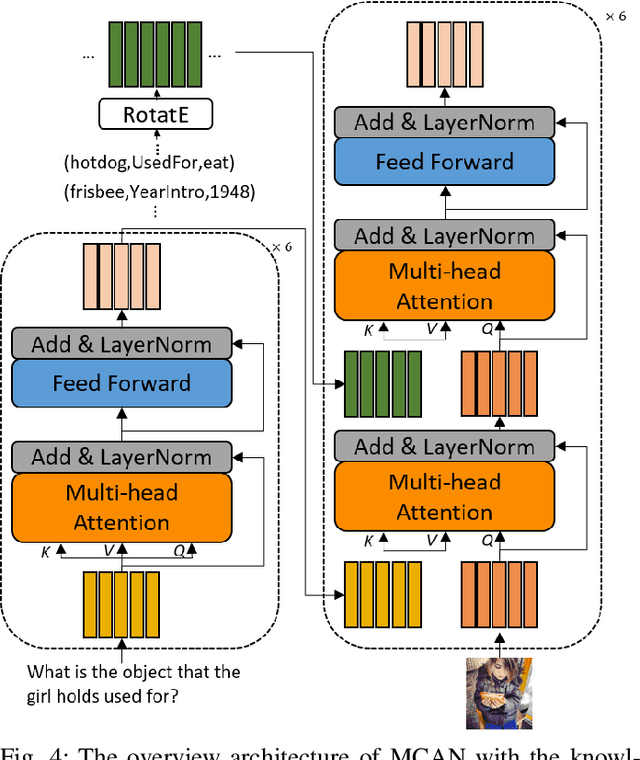
Though beneficial for encouraging the Visual Question Answering (VQA) models to discover the underlying knowledge by exploiting the input-output correlation beyond image and text contexts, the existing knowledge VQA datasets are mostly annotated in a crowdsource way, e.g., collecting questions and external reasons from different users via the internet. In addition to the challenge of knowledge reasoning, how to deal with the annotator bias also remains unsolved, which often leads to superficial over-fitted correlations between questions and answers. To address this issue, we propose a novel dataset named Knowledge-Routed Visual Question Reasoning for VQA model evaluation. Considering that a desirable VQA model should correctly perceive the image context, understand the question, and incorporate its learned knowledge, our proposed dataset aims to cutoff the shortcut learning exploited by the current deep embedding models and push the research boundary of the knowledge-based visual question reasoning. Specifically, we generate the question-answer pair based on both the Visual Genome scene graph and an external knowledge base with controlled programs to disentangle the knowledge from other biases. The programs can select one or two triplets from the scene graph or knowledge base to push multi-step reasoning, avoid answer ambiguity, and balanced the answer distribution. In contrast to the existing VQA datasets, we further imply the following two major constraints on the programs to incorporate knowledge reasoning: i) multiple knowledge triplets can be related to the question, but only one knowledge relates to the image object. This can enforce the VQA model to correctly perceive the image instead of guessing the knowledge based on the given question solely; ii) all questions are based on different knowledge, but the candidate answers are the same for both the training and test sets.
EagleEye: Fast Sub-net Evaluation for Efficient Neural Network Pruning
Jul 06, 2020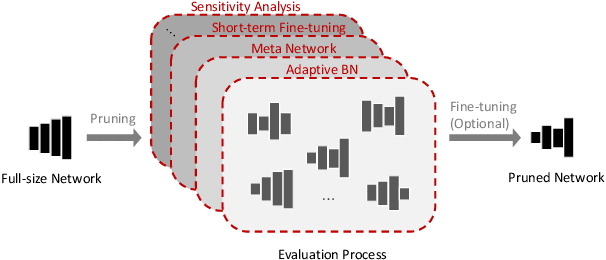
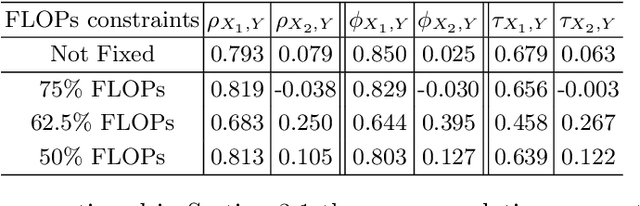
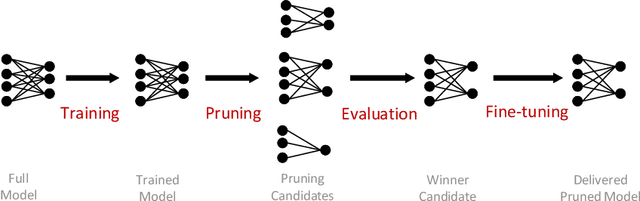
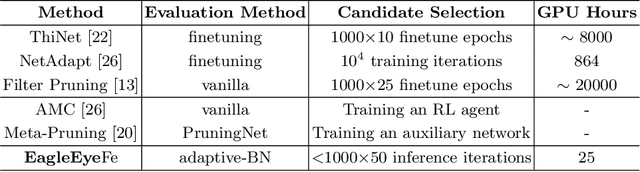
Finding out the computational redundant part of a trained Deep Neural Network (DNN) is the key question that pruning algorithms target on. Many algorithms try to predict model performance of the pruned sub-nets by introducing various evaluation methods. But they are either inaccurate or very complicated for general application. In this work, we present a pruning method called EagleEye, in which a simple yet efficient evaluation component based on adaptive batch normalization is applied to unveil a strong correlation between different pruned DNN structures and their final settled accuracy. This strong correlation allows us to fast spot the pruned candidates with highest potential accuracy without actually fine-tuning them. This module is also general to plug-in and improve some existing pruning algorithms. EagleEye achieves better pruning performance than all of the studied pruning algorithms in our experiments. Concretely, to prune MobileNet V1 and ResNet-50, EagleEye outperforms all compared methods by up to 3.8%. Even in the more challenging experiments of pruning the compact model of MobileNet V1, EagleEye achieves the highest accuracy of 70.9% with an overall 50% operations (FLOPs) pruned. All accuracy results are Top-1 ImageNet classification accuracy. Source code and models are accessible to open-source community https://github.com/anonymous47823493/EagleEye .
Explainable High-order Visual Question Reasoning: A New Benchmark and Knowledge-routed Network
Sep 23, 2019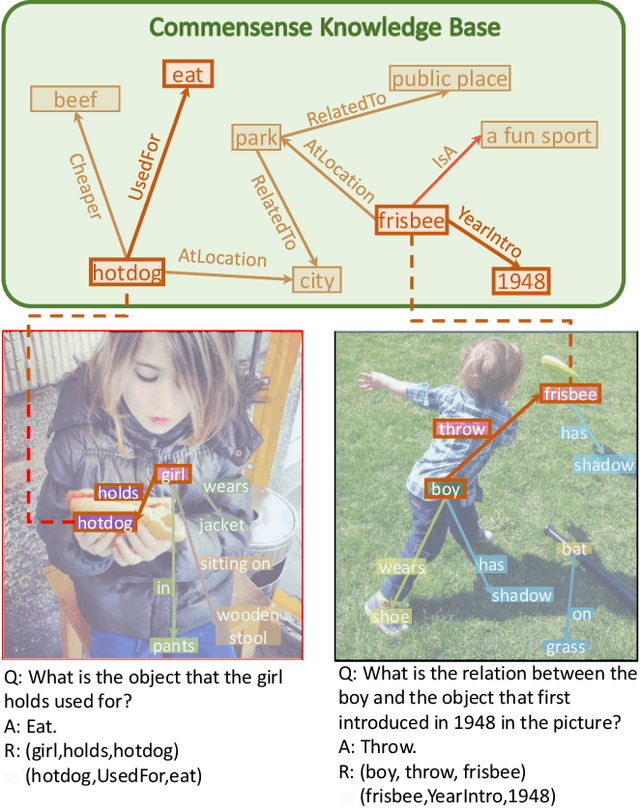
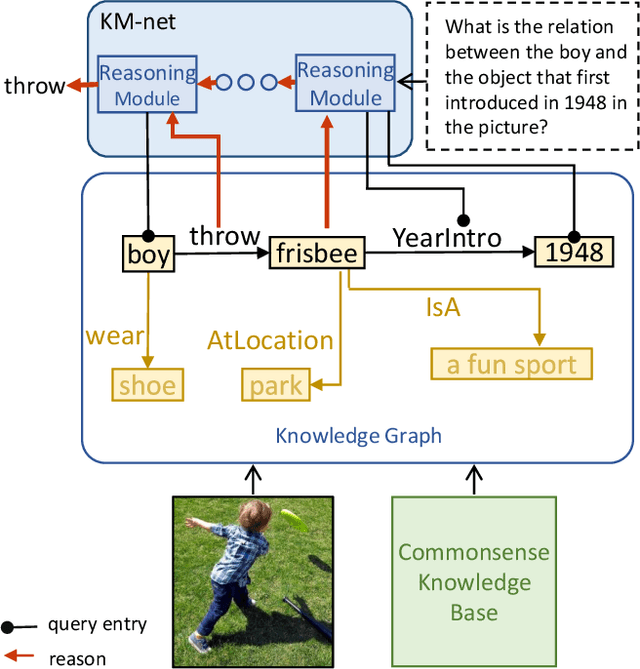
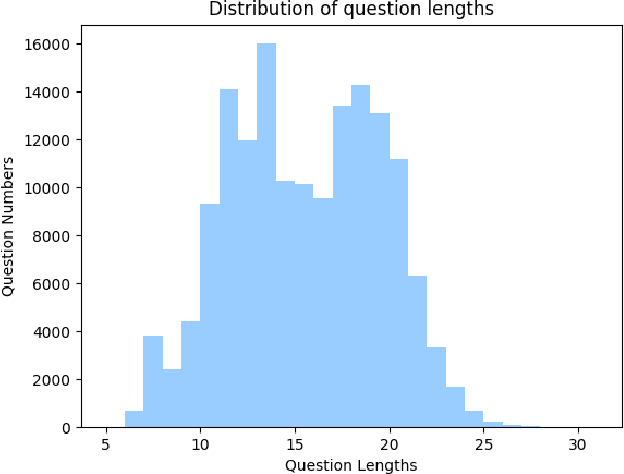
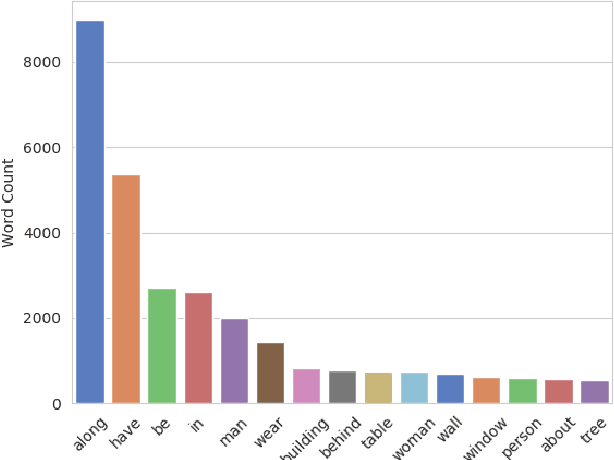
Explanation and high-order reasoning capabilities are crucial for real-world visual question answering with diverse levels of inference complexity (e.g., what is the dog that is near the girl playing with?) and important for users to understand and diagnose the trustworthiness of the system. Current VQA benchmarks on natural images with only an accuracy metric end up pushing the models to exploit the dataset biases and cannot provide any interpretable justification, which severally hinders advances in high-level question answering. In this work, we propose a new HVQR benchmark for evaluating explainable and high-order visual question reasoning ability with three distinguishable merits: 1) the questions often contain one or two relationship triplets, which requires the model to have the ability of multistep reasoning to predict plausible answers; 2) we provide an explicit evaluation on a multistep reasoning process that is constructed with image scene graphs and commonsense knowledge bases; and 3) each relationship triplet in a large-scale knowledge base only appears once among all questions, which poses challenges for existing networks that often attempt to overfit the knowledge base that already appears in the training set and enforces the models to handle unseen questions and knowledge fact usage. We also propose a new knowledge-routed modular network (KM-net) that incorporates the multistep reasoning process over a large knowledge base into visual question reasoning. An extensive dataset analysis and comparisons with existing models on the HVQR benchmark show that our benchmark provides explainable evaluations, comprehensive reasoning requirements and realistic challenges of VQA systems, as well as our KM-net's superiority in terms of accuracy and explanation ability.
Interpretable Visual Question Answering by Reasoning on Dependency Trees
Sep 06, 2018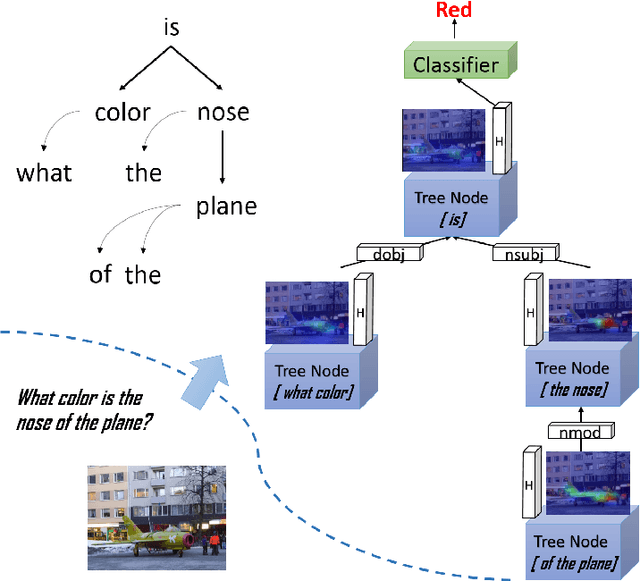
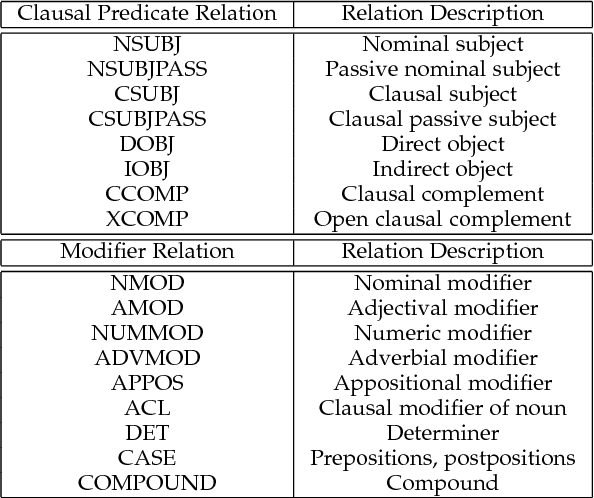
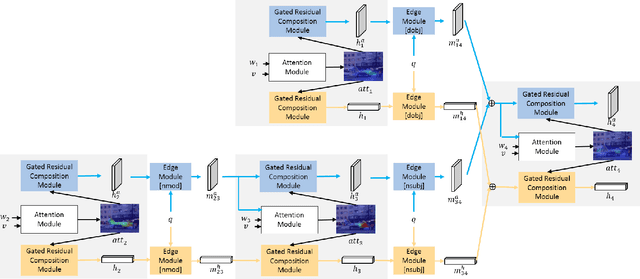

Collaborative reasoning for understanding each image-question pair is very critical but underexplored for an interpretable visual question answering system. Although very recent works also attempted to use explicit compositional processes to assemble multiple subtasks embedded in the questions, their models heavily rely on annotations or handcrafted rules to obtain valid reasoning processes, leading to either heavy workloads or poor performance on composition reasoning. In this paper, to better align image and language domains in diverse and unrestricted cases, we propose a novel neural network model that performs global reasoning on a dependency tree parsed from the question, and we thus phrase our model as parse-tree-guided reasoning network (PTGRN). This network consists of three collaborative modules: i) an attention module to exploit the local visual evidence for each word parsed from the question, ii) a gated residual composition module to compose the previously mined evidence, and iii) a parse-tree-guided propagation module to pass the mined evidence along the parse tree. Our PTGRN is thus capable of building an interpretable VQA system that gradually derives the image cues following a question-driven parse-tree reasoning route. Experiments on relational datasets demonstrate the superiority of our PTGRN over current state-of-the-art VQA methods, and the visualization results highlight the explainable capability of our reasoning system.