 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Visual Question Answering by Reasoning on Dependency Trees
Paper and Code
Sep 06, 2018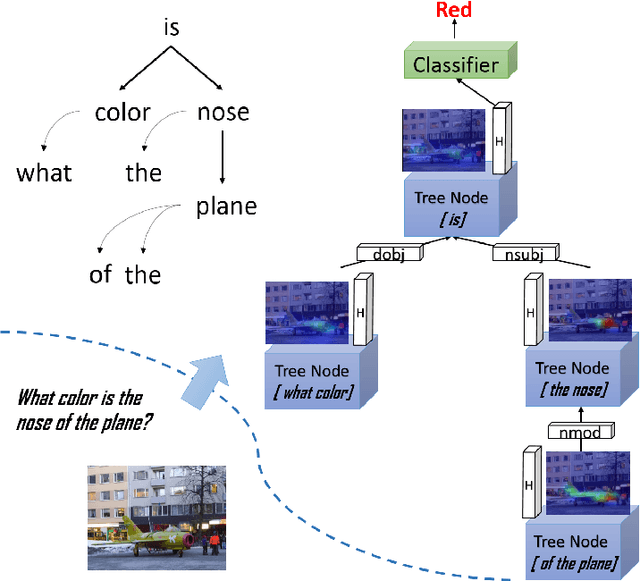
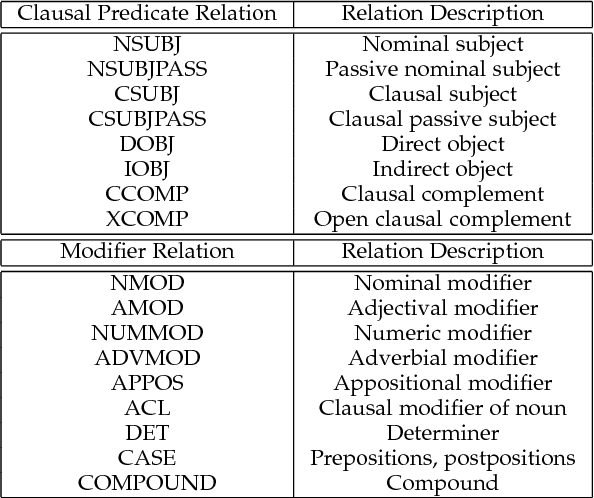
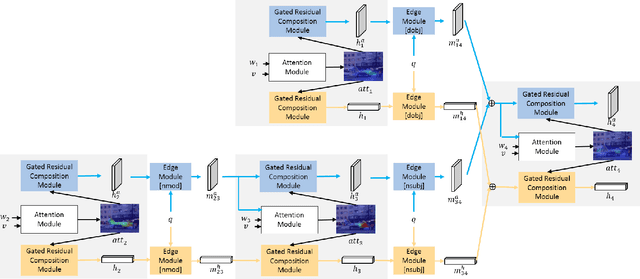

Collaborative reasoning for understanding each image-question pair is very critical but underexplored for an interpretable visual question answering system. Although very recent works also attempted to use explicit compositional processes to assemble multiple subtasks embedded in the questions, their models heavily rely on annotations or handcrafted rules to obtain valid reasoning processes, leading to either heavy workloads or poor performance on composition reasoning. In this paper, to better align image and language domains in diverse and unrestricted cases, we propose a novel neural network model that performs global reasoning on a dependency tree parsed from the question, and we thus phrase our model as parse-tree-guided reasoning network (PTGRN). This network consists of three collaborative modules: i) an attention module to exploit the local visual evidence for each word parsed from the question, ii) a gated residual composition module to compose the previously mined evidence, and iii) a parse-tree-guided propagation module to pass the mined evidence along the parse tree. Our PTGRN is thus capable of building an interpretable VQA system that gradually derives the image cues following a question-driven parse-tree reasoning route. Experiments on relational datasets demonstrate the superiority of our PTGRN over current state-of-the-art VQA methods, and the visualization results highlight the explainable capability of our reasoning system.