 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProCeedRL: Process Critic with Exploratory Demonstration Reinforcement Learning for LLM Agentic Reasoning
Apr 02, 2026Reinforcement Learning (RL) significantly enhances the reasoning abilities of large language models (LLMs), yet applying it to multi-turn agentic tasks remains challenging due to the long-horizon nature of interactions and the stochasticity of environmental feedback. We identify a structural failure mode in agentic exploration: suboptimal actions elicit noisy observations into misleading contexts, which further weaken subsequent decision-making, making recovery increasingly difficult. This cumulative feedback loop of errors renders standard exploration strategies ineffective and susceptible to the model's reasoning and the environment's randomness. To mitigate this issue, we propose ProCeedRL: Process Critic with Explorative Demonstration RL, shifting exploration from passive selection to active intervention. ProCeedRL employs a process-level critic to monitor interactions in real time, incorporating reflection-based demonstrations to guide agents in stopping the accumulation of errors. We find that this approach significantly exceeds the model's saturated exploration performance, demonstrating substantial exploratory benefits. By learning from exploratory demonstrations and on-policy samples, ProCeedRL significantly improves exploration efficiency and achieves superior performance on complex deep search and embodied tasks.
LEMUR: Large scale End-to-end MUltimodal Recommendation
Nov 17, 2025Traditional ID-based recommender systems often struggle with cold-start and generalization challenges. Multimodal recommendation systems, which leverage textual and visual data, offer a promising solution to mitigate these issues. However, existing industrial approaches typically adopt a two-stage training paradigm: first pretraining a multimodal model, then applying its frozen representations to train the recommendation model. This decoupled framework suffers from misalignment between multimodal learning and recommendation objectives, as well as an inability to adapt dynamically to new data. To address these limitations, we propose LEMUR, the first large-scale multimodal recommender system trained end-to-end from raw data. By jointly optimizing both the multimodal and recommendation components, LEMUR ensures tighter alignment with downstream objectives while enabling real-time parameter updates. Constructing multimodal sequential representations from user history often entails prohibitively high computational costs. To alleviate this bottleneck, we propose a novel memory bank mechanism that incrementally accumulates historical multimodal representations throughout the training process. After one month of deployment in Douyin Search, LEMUR has led to a 0.843% reduction in query change rate decay and a 0.81% improvement in QAUC. Additionally, LEMUR has shown significant gains across key offline metrics for Douyin Advertisement. Our results validate the superiority of end-to-end multimodal recommendation in real-world industrial scenarios.
MARGE: Improving Math Reasoning for LLMs with Guided Exploration
May 18, 2025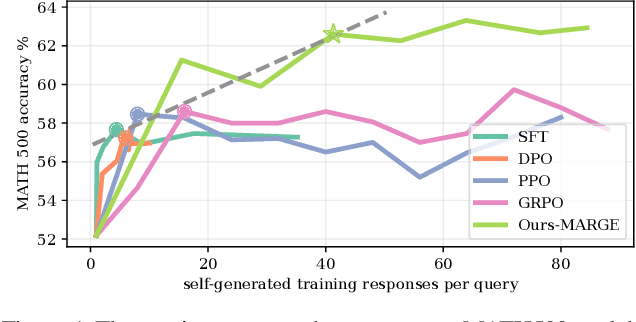
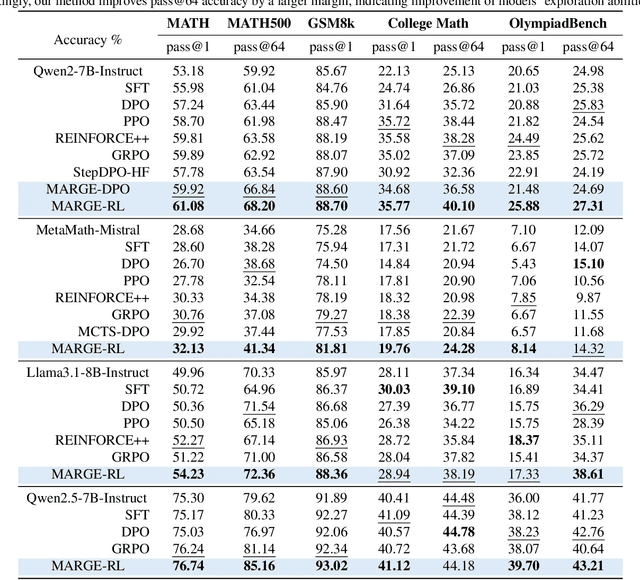
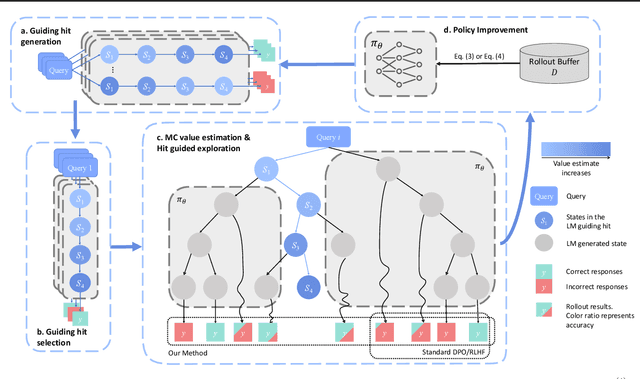
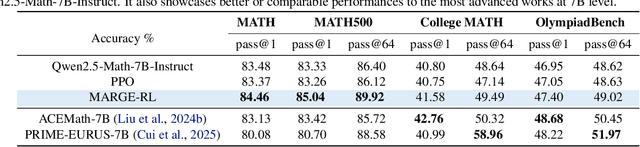
Large Language Models (LLMs) exhibit strong potential in mathematical reasoning, yet their effectiveness is often limited by a shortage of high-quality queries. This limitation necessitates scaling up computational responses through self-generated data, yet current methods struggle due to spurious correlated data caused by ineffective exploration across all reasoning stages. To address such challenge, we introduce \textbf{MARGE}: Improving \textbf{Ma}th \textbf{R}easoning with \textbf{G}uided \textbf{E}xploration, a novel method to address this issue and enhance mathematical reasoning through hit-guided exploration. MARGE systematically explores intermediate reasoning states derived from self-generated solutions, enabling adequate exploration and improved credit assignment throughout the reasoning process. Through extensive experiments across multiple backbone models and benchmarks, we demonstrate that MARGE significantly improves reasoning capabilities without requiring external annotations or training additional value models. Notably, MARGE improves both single-shot accuracy and exploration diversity, mitigating a common trade-off in alignment methods. These results demonstrate MARGE's effectiveness in enhancing mathematical reasoning capabilities and unlocking the potential of scaling self-generated training data. Our code and models are available at \href{https://github.com/georgao35/MARGE}{this link}.
Decentralized Motor Skill Learning for Complex Robotic Systems
Jun 30, 2023Reinforcement learning (RL) has achieved remarkable success in complex robotic systems (eg. quadruped locomotion). In previous works, the RL-based controller was typically implemented as a single neural network with concatenated observation input. However, the corresponding learned policy is highly task-specific. Since all motors are controlled in a centralized way, out-of-distribution local observations can impact global motors through the single coupled neural network policy. In contrast, animals and humans can control their limbs separately. Inspired by this biological phenomenon, we propose a Decentralized motor skill (DEMOS) learning algorithm to automatically discover motor groups that can be decoupled from each other while preserving essential connections and then learn a decentralized motor control policy. Our method improves the robustness and generalization of the policy without sacrificing performance. Experiments on quadruped and humanoid robots demonstrate that the learned policy is robust against local motor malfunctions and can be transferred to new tasks.
COPR: Consistency-Oriented Pre-Ranking for Online Advertising
Jun 06, 2023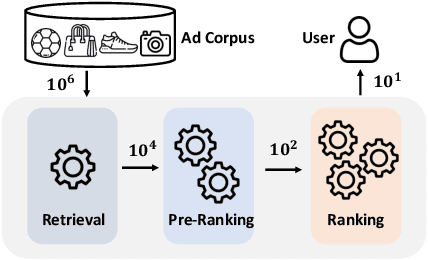

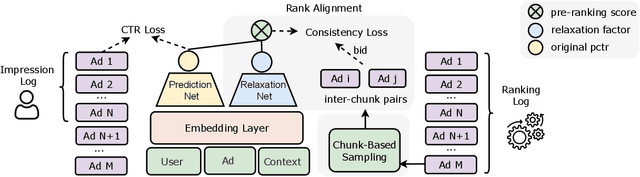
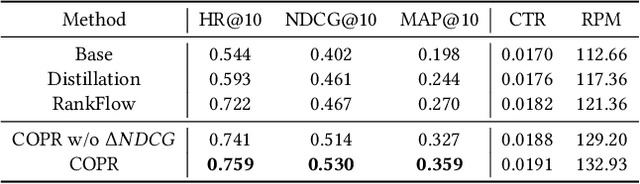
Cascading architecture has been widely adopted in large-scale advertising systems to balance efficiency and effectiveness. In this architecture, the pre-ranking model is expected to be a lightweight approximation of the ranking model, which handles more candidates with strict latency requirements. Due to the gap in model capacity, the pre-ranking and ranking models usually generate inconsistent ranked results, thus hurting the overall system effectiveness. The paradigm of score alignment is proposed to regularize their raw scores to be consistent. However, it suffers from inevitable alignment errors and error amplification by bids when applied in online advertising. To this end, we introduce a consistency-oriented pre-ranking framework for online advertising, which employs a chunk-based sampling module and a plug-and-play rank alignment module to explicitly optimize consistency of ECPM-ranked results. A $\Delta NDCG$-based weighting mechanism is adopted to better distinguish the importance of inter-chunk samples in optimization. Both online and offline experiments have validated the superiority of our framework. When deployed in Taobao display advertising system, it achieves an improvement of up to +12.3\% CTR and +5.6\% RPM.
Rec4Ad: A Free Lunch to Mitigate Sample Selection Bias for Ads CTR Prediction in Taobao
Jun 06, 2023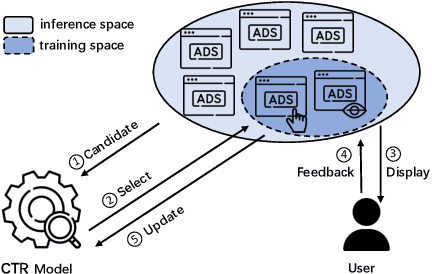
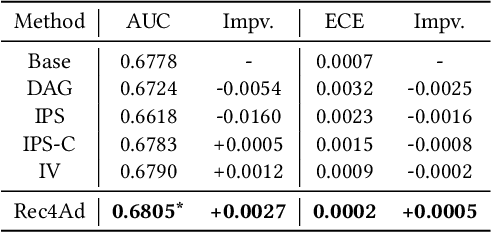
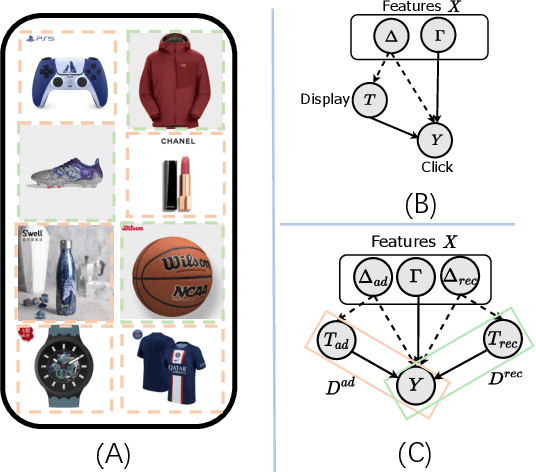
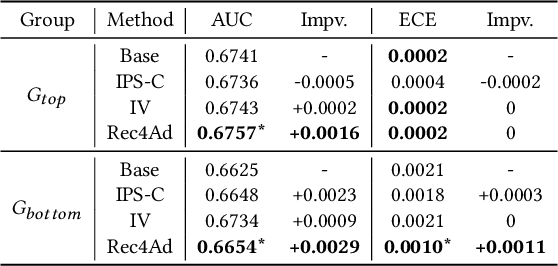
Click-Through Rate (CTR) prediction serves as a fundamental component in online advertising. A common practice is to train a CTR model on advertisement (ad) impressions with user feedback. Since ad impressions are purposely selected by the model itself, their distribution differs from the inference distribution and thus exhibits sample selection bias (SSB) that affects model performance. Existing studies on SSB mainly employ sample re-weighting techniques which suffer from high variance and poor model calibration. Another line of work relies on costly uniform data that is inadequate to train industrial models. Thus mitigating SSB in industrial models with a uniform-data-free framework is worth exploring. Fortunately, many platforms display mixed results of organic items (i.e., recommendations) and sponsored items (i.e., ads) to users, where impressions of ads and recommendations are selected by different systems but share the same user decision rationales. Based on the above characteristics, we propose to leverage recommendations samples as a free lunch to mitigate SSB for ads CTR model (Rec4Ad). After elaborating data augmentation, Rec4Ad learns disentangled representations with alignment and decorrelation modules for enhancement. When deployed in Taobao display advertising system, Rec4Ad achieves substantial gains in key business metrics, with a lift of up to +6.6\% CTR and +2.9\% RPM.
Reinforcement learning with Demonstrations from Mismatched Task under Sparse Reward
Dec 03, 2022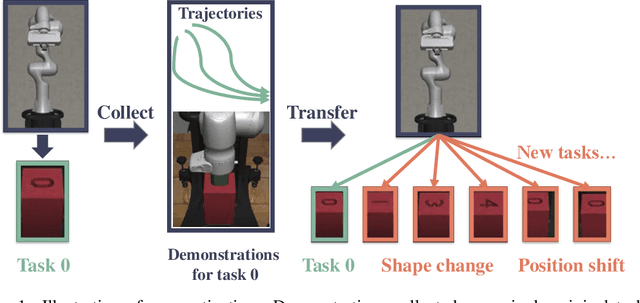
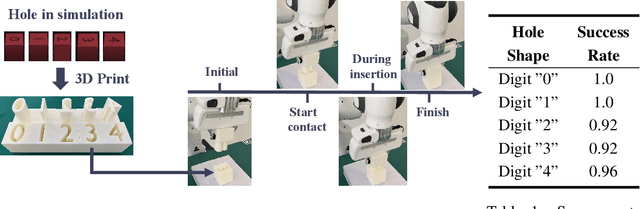
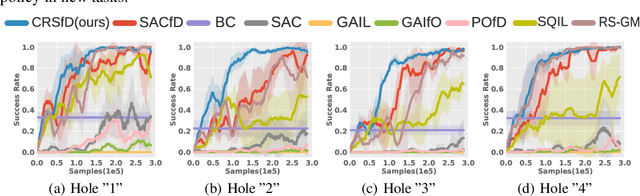
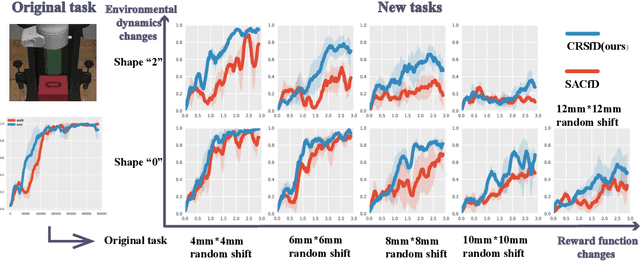
Reinforcement learning often suffer from the sparse reward issue in real-world robotics problems. Learning from demonstration (LfD) is an effective way to eliminate this problem, which leverages collected expert data to aid online learning. Prior works often assume that the learning agent and the expert aim to accomplish the same task, which requires collecting new data for every new task. In this paper, we consider the case where the target task is mismatched from but similar with that of the expert. Such setting can be challenging and we found existing LfD methods can not effectively guide learning in mismatched new tasks with sparse rewards. We propose conservative reward shaping from demonstration (CRSfD), which shapes the sparse rewards using estimated expert value function. To accelerate learning processes, CRSfD guides the agent to conservatively explore around demonstrations. Experimental results of robot manipulation tasks show that our approach outperforms baseline LfD methods when transferring demonstrations collected in a single task to other different but similar tasks.
Joint Optimization of Ranking and Calibration with Contextualized Hybrid Model
Aug 12, 2022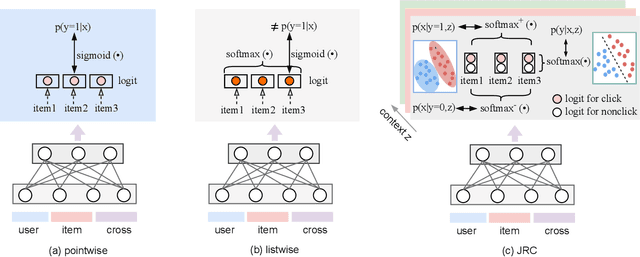
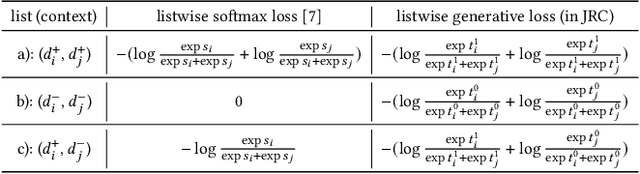

Despite the development of ranking optimization techniques, the pointwise model remains the dominating approach for click-through rate (CTR) prediction. It can be attributed to the calibration ability of the pointwise model since the prediction can be viewed as the click probability. In practice, a CTR prediction model is also commonly assessed with the ranking ability, for which prediction models based on ranking losses (e.g., pairwise or listwise loss) usually achieve better performances than the pointwise loss. Previous studies have experimented with a direct combination of the two losses to obtain the benefit from both losses and observed an improved performance. However, previous studies break the meaning of output logit as the click-through rate, which may lead to sub-optimal solutions. To address this issue, we propose an approach that can Jointly optimize the Ranking and Calibration abilities (JRC for short). JRC improves the ranking ability by contrasting the logit value for the sample with different labels and constrains the predicted probability to be a function of the logit subtraction. We further show that JRC consolidates the interpretation of logits, where the logits model the joint distribution. With such an interpretation, we prove that JRC approximately optimizes the contextualized hybrid discriminative-generative objective. Experiments on public and industrial datasets and online A/B testing show that our approach improves both ranking and calibration abilities. Since May 2022, JRC has been deployed on the display advertising platform of Alibaba and has obtained significant performance improvements.
Multi-Label Robust Factorization Autoencoder and its Application in Predicting Drug-Drug Interactions
Nov 01, 2018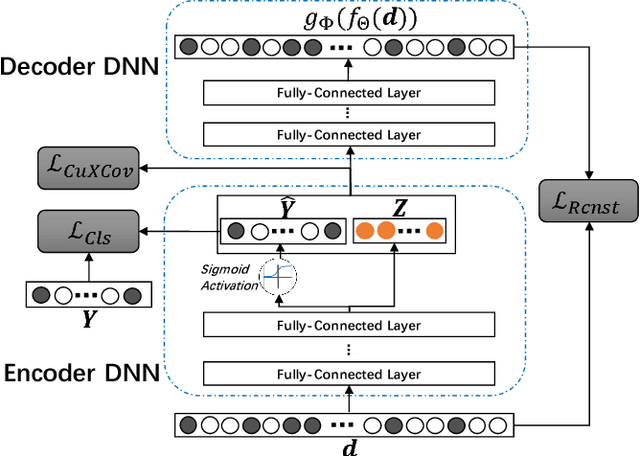
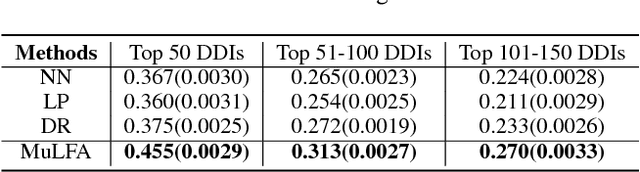
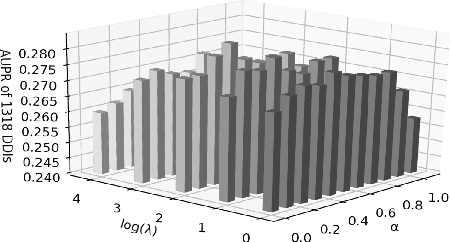
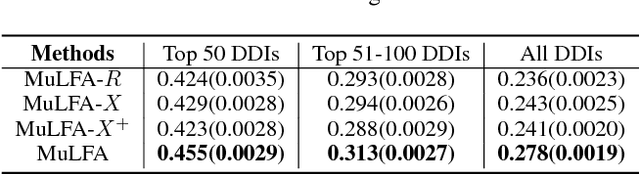
Drug-drug interactions (DDIs) are a major cause of preventable hospitalizations and deaths. Predicting the occurrence of DDIs helps drug safety professionals allocate investigative resources and take appropriate regulatory action promptly. Traditional DDI prediction methods predict DDIs based on the similarity between drugs. Recently, researchers revealed that predictive performance can be improved by better modeling the interactions between drug pairs with bilinear forms. However, the shallow models leveraging bilinear forms suffer from limitations on capturing complicated nonlinear interactions between drug pairs. To this end, we propose Multi-Label Robust Factorization Autoencoder (abbreviated to MuLFA) for DDI prediction, which learns a representation of interactions between drug pairs and has the capability of characterizing complicated nonlinear interactions more precisely. Moreover, a novel loss called CuXCov is designed to effectively learn the parameters of MuLFA. Furthermore, the decoder is able to generate high-risk chemical structures of drug pairs for specific DDIs, assisting pharmacists to better understand the relationship between drug chemistry and DDI. Experimental results on real-world datasets demonstrate that MuLFA consistently outperforms state-of-the-art methods; particularly, it increases 21:3% predictive performance compared to the best baseline for top 50 frequent DDIs.We also illustrate various case studies to demonstrate the efficacy of the chemical structures generated by MuLFA in DDI diagnosis.
Motif-based Rule Discovery for Predicting Real-valued Time Series
Dec 02, 2017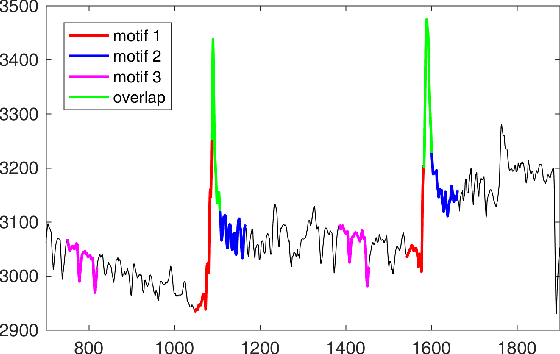

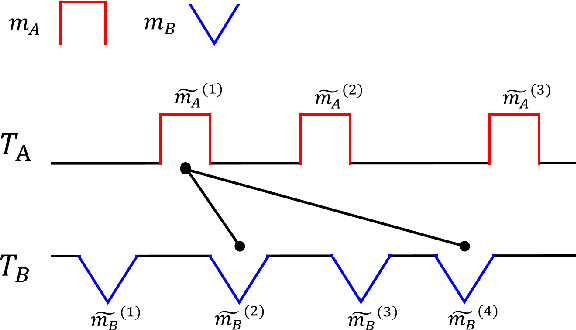
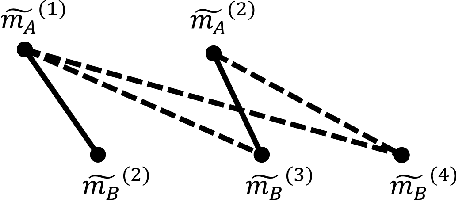
Time series prediction is of great significance in many applications and has attracted extensive attention from the data mining community. Existing work suggests that for many problems, the shape in the current time series may correlate an upcoming shape in the same or another series. Therefore, it is a promising strategy to associate two recurring patterns as a rule's antecedent and consequent: the occurrence of the antecedent can foretell the occurrence of the consequent, and the learned shape of consequent will give accurate predictions. Earlier work employs symbolization methods, but the symbolized representation maintains too little information of the original series to mine valid rules. The state-of-the-art work, though directly manipulating the series, fails to segment the series precisely for seeking antecedents/consequents, resulting in inaccurate rules in common scenarios. In this paper, we propose a novel motif-based rule discovery method, which utilizes motif discovery to accurately extract frequently occurring consecutive subsequences, i.e. motifs, as antecedents/consequents. It then investigates the underlying relationships between motifs by matching motifs as rule candidates and ranking them based on the similarities. Experimental results on real open datasets show that the proposed approach outperforms the baseline method by 23.9%. Furthermore, it extends the applicability from single time series to multiple ones.