 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiniMax-01: Scaling Foundation Models with Lightning Attention
Jan 14, 2025We introduce MiniMax-01 series, including MiniMax-Text-01 and MiniMax-VL-01, which are comparable to top-tier models while offering superior capabilities in processing longer contexts. The core lies in lightning attention and its efficient scaling. To maximize computational capacity, we integrate it with Mixture of Experts (MoE), creating a model with 32 experts and 456 billion total parameters, of which 45.9 billion are activated for each token. We develop an optimized parallel strategy and highly efficient computation-communication overlap techniques for MoE and lightning attention. This approach enables us to conduct efficient training and inference on models with hundreds of billions of parameters across contexts spanning millions of tokens. The context window of MiniMax-Text-01 can reach up to 1 million tokens during training and extrapolate to 4 million tokens during inference at an affordable cost. Our vision-language model, MiniMax-VL-01 is built through continued training with 512 billion vision-language tokens. Experiments on both standard and in-house benchmarks show that our models match the performance of state-of-the-art models like GPT-4o and Claude-3.5-Sonnet while offering 20-32 times longer context window. We publicly release MiniMax-01 at https://github.com/MiniMax-AI.
GMS-VINS:Multi-category Dynamic Objects Semantic Segmentation for Enhanced Visual-Inertial Odometry Using a Promptable Foundation Model
Nov 28, 2024

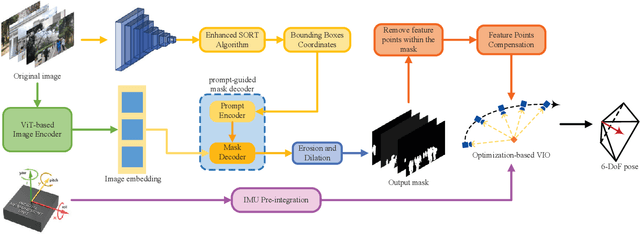
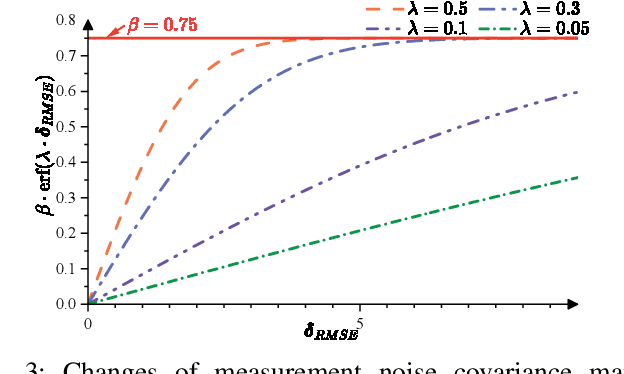
Visual-inertial odometry (VIO) is widely used in various fields, such as robots, drones, and autonomous vehicles, due to its low cost and complementary sensors. Most VIO methods presuppose that observed objects are static and time-invariant. However, real-world scenes often feature dynamic objects, compromising the accuracy of pose estimation. These moving entities include cars, trucks, buses, motorcycles, and pedestrians. The diversity and partial occlusion of these objects present a tough challenge for existing dynamic object removal techniques. To tackle this challenge, we introduce GMS-VINS, which integrates an enhanced SORT algorithm along with a robust multi-category segmentation framework into VIO, thereby improving pose estimation accuracy in environments with diverse dynamic objects and frequent occlusions. Leveraging the promptable foundation model, our solution efficiently tracks and segments a wide range of object categories. The enhanced SORT algorithm significantly improves the reliability of tracking multiple dynamic objects, especially in urban settings with partial occlusions or swift movements. We evaluated our proposed method using multiple public datasets representing various scenes, as well as in a real-world scenario involving diverse dynamic objects. The experimental results demonstrate that our proposed method performs impressively in multiple scenarios, outperforming other state-of-the-art methods. This highlights its remarkable generalization and adaptability in diverse dynamic environments, showcasing its potential to handle various dynamic objects in practical applications.