 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudit-LLM: Multi-Agent Collaboration for Log-based Insider Threat Detection
Aug 12, 2024



Log-based insider threat detection (ITD) detects malicious user activities by auditing log entries. Recently, large language models (LLMs) with strong common sense knowledge have emerged in the domain of ITD. Nevertheless, diverse activity types and overlong log files pose a significant challenge for LLMs in directly discerning malicious ones within myriads of normal activities. Furthermore, the faithfulness hallucination issue from LLMs aggravates its application difficulty in ITD, as the generated conclusion may not align with user commands and activity context. In response to these challenges, we introduce Audit-LLM, a multi-agent log-based insider threat detection framework comprising three collaborative agents: (i) the Decomposer agent, breaking down the complex ITD task into manageable sub-tasks using Chain-of-Thought (COT) reasoning;(ii) the Tool Builder agent, creating reusable tools for sub-tasks to overcome context length limitations in LLMs; and (iii) the Executor agent, generating the final detection conclusion by invoking constructed tools. To enhance conclusion accuracy, we propose a pair-wise Evidence-based Multi-agent Debate (EMAD) mechanism, where two independent Executors iteratively refine their conclusions through reasoning exchange to reach a consensus. Comprehensive experiments conducted on three publicly available ITD datasets-CERT r4.2, CERT r5.2, and PicoDomain-demonstrate the superiority of our method over existing baselines and show that the proposed EMAD significantly improves the faithfulness of explanations generated by LLMs.
MsPrompt: Multi-step Prompt Learning for Debiasing Few-shot Event Detection
May 16, 2023



Event detection (ED) is aimed to identify the key trigger words in unstructured text and predict the event types accordingly. Traditional ED models are too data-hungry to accommodate real applications with scarce labeled data. Besides, typical ED models are facing the context-bypassing and disabled generalization issues caused by the trigger bias stemming from ED datasets. Therefore, we focus on the true few-shot paradigm to satisfy the low-resource scenarios. In particular, we propose a multi-step prompt learning model (MsPrompt) for debiasing few-shot event detection, that consists of the following three components: an under-sampling module targeting to construct a novel training set that accommodates the true few-shot setting, a multi-step prompt module equipped with a knowledge-enhanced ontology to leverage the event semantics and latent prior knowledge in the PLMs sufficiently for tackling the context-bypassing problem, and a prototypical module compensating for the weakness of classifying events with sparse data and boost the generalization performance. Experiments on two public datasets ACE-2005 and FewEvent show that MsPrompt can outperform the state-of-the-art models, especially in the strict low-resource scenarios reporting 11.43% improvement in terms of weighted F1-score against the best-performing baseline and achieving an outstanding debiasing performance.
Retrieving and Reading: A Comprehensive Survey on Open-domain Question Answering
Jan 04, 2021

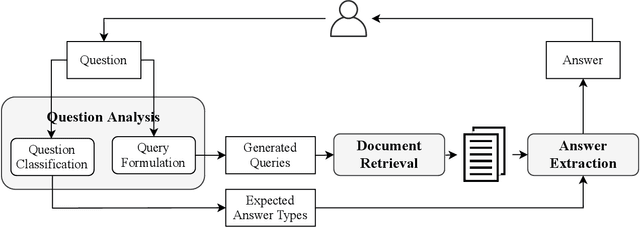

Open-domain Question Answering (OpenQA) is an important task in Natural Language Processing (NLP), which aims to answer a question in the form of natural language based on large-scale unstructured documents. Recently, there has been a surge in the amount of research literature on OpenQA, particularly on techniques that integrate with neural Machine Reading Comprehension (MRC). While these research works have advanced performance to new heights on benchmark datasets, they have been rarely covered in existing surveys on QA systems. In this work, we review the latest research trends in OpenQA, with particular attention to systems that incorporate neural MRC techniques. Specifically, we begin with revisiting the origin and development of OpenQA systems. We then introduce modern OpenQA architecture named ``Retriever-Reader'' and analyze the various systems that follow this architecture as well as the specific techniques adopted in each of the components. We then discuss key challenges to developing OpenQA systems and offer an analysis of benchmarks that are commonly used. We hope our work would enable researchers to be informed of the recent advancement and also the open challenges in OpenQA research, so as to stimulate further progress in this field.
GeoConv: Geodesic Guided Convolution for Facial Action Unit Recognition
Mar 06, 2020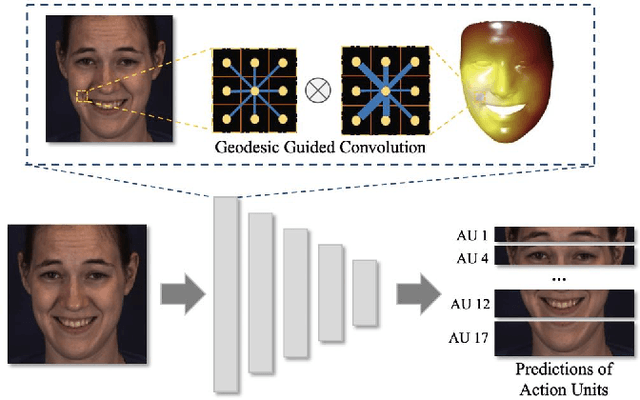
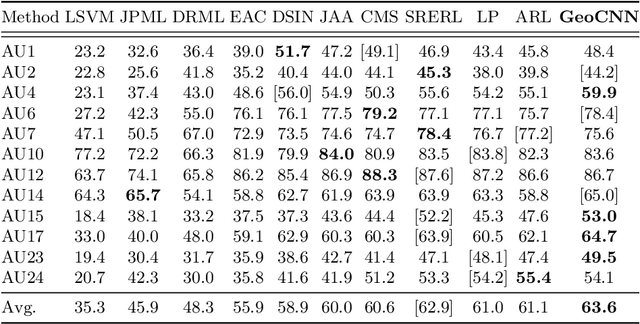
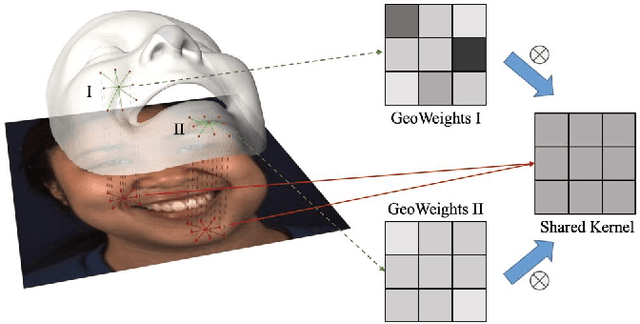
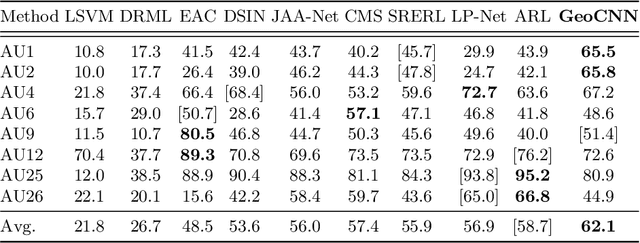
Automatic facial action unit (AU) recognition has attracted great attention but still remains a challenging task, as subtle changes of local facial muscles are difficult to thoroughly capture. Most existing AU recognition approaches leverage geometry information in a straightforward 2D or 3D manner, which either ignore 3D manifold information or suffer from high computational costs. In this paper, we propose a novel geodesic guided convolution (GeoConv) for AU recognition by embedding 3D manifold information into 2D convolutions. Specifically, the kernel of GeoConv is weighted by our introduced geodesic weights, which are negatively correlated to geodesic distances on a coarsely reconstructed 3D face model. Moreover, based on GeoConv, we further develop an end-to-end trainable framework named GeoCNN for AU recognition. Extensive experiments on BP4D and DISFA benchmarks show that our approach significantly outperforms the state-of-the-art AU recognition methods.
Pre-train, Interact, Fine-tune: A Novel Interaction Representation for Text Classification
Sep 26, 2019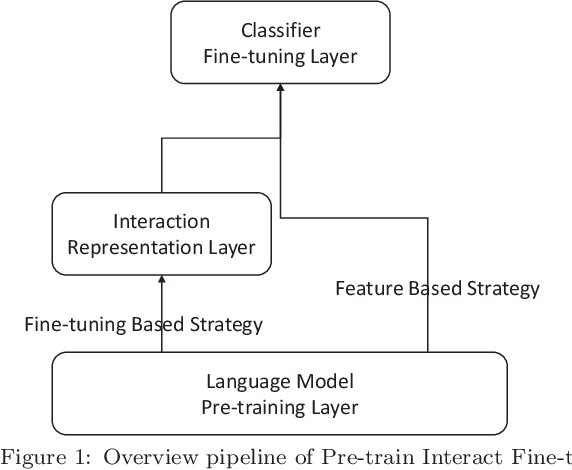
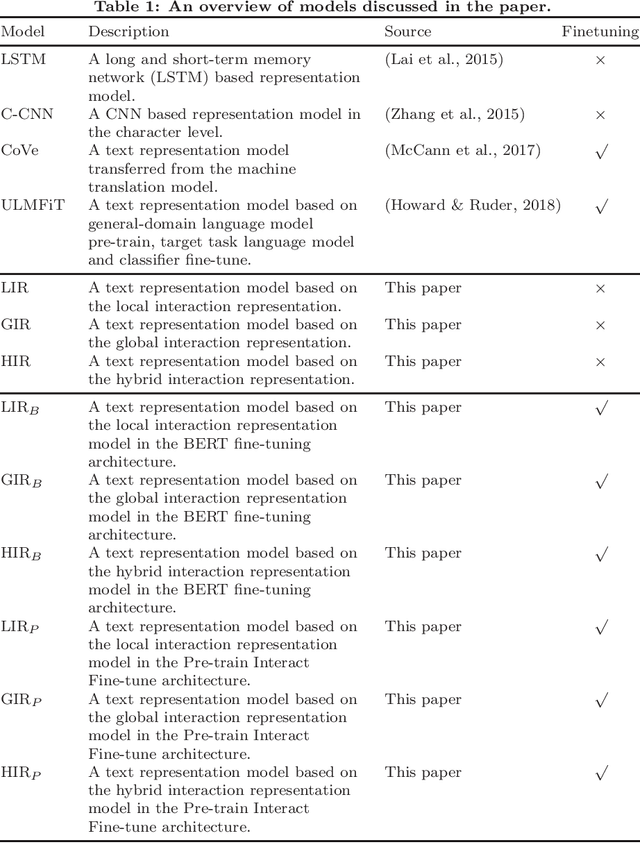
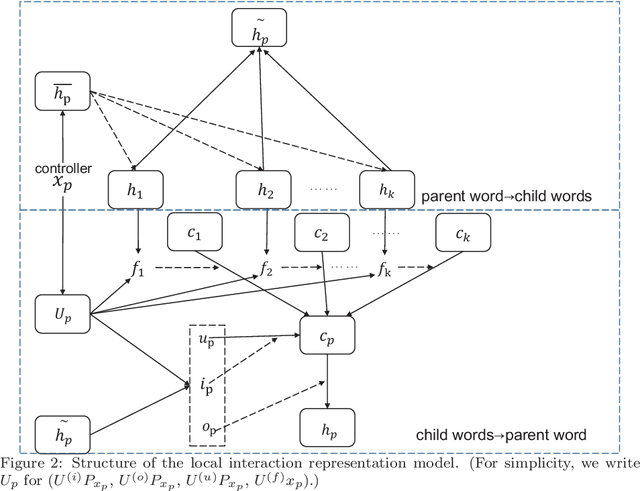
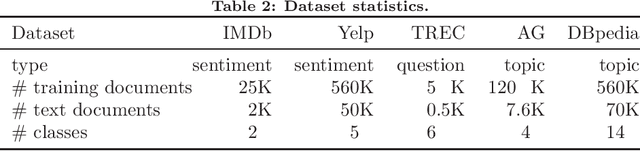
Text representation can aid machines in understanding text. Previous work on text representation often focuses on the so-called forward implication, i.e., preceding words are taken as the context of later words for creating representations, thus ignoring the fact that the semantics of a text segment is a product of the mutual implication of words in the text: later words contribute to the meaning of preceding words. We introduce the concept of interaction and propose a two-perspective interaction representation, that encapsulates a local and a global interaction representation. Here, a local interaction representation is one that interacts among words with parent-children relationships on the syntactic trees and a global interaction interpretation is one that interacts among all the words in a sentence. We combine the two interaction representations to develop a Hybrid Interaction Representation (HIR). Inspired by existing feature-based and fine-tuning-based pretrain-finetuning approaches to language models, we integrate the advantages of feature-based and fine-tuning-based methods to propose the Pre-train, Interact, Fine-tune (PIF) architecture. We evaluate our proposed models on five widely-used datasets for text classification tasks. Our ensemble method, outperforms state-of-the-art baselines with improvements ranging from 2.03% to 3.15% in terms of error rate. In addition, we find that, the improvements of PIF against most state-of-the-art methods is not affected by increasing of the length of the text.