 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDebiasing Sequential Recommenders through Distributionally Robust Optimization over System Exposure
Dec 12, 2023



Sequential recommendation (SR) models are typically trained on user-item interactions which are affected by the system exposure bias, leading to the user preference learned from the biased SR model not being fully consistent with the true user preference. Exposure bias refers to the fact that user interactions are dependent upon the partial items exposed to the user. Existing debiasing methods do not make full use of the system exposure data and suffer from sub-optimal recommendation performance and high variance. In this paper, we propose to debias sequential recommenders through Distributionally Robust Optimization (DRO) over system exposure data. The key idea is to utilize DRO to optimize the worst-case error over an uncertainty set to safeguard the model against distributional discrepancy caused by the exposure bias. The main challenge to apply DRO for exposure debiasing in SR lies in how to construct the uncertainty set and avoid the overestimation of user preference on biased samples. Moreover, how to evaluate the debiasing effect on biased test set is also an open question. To this end, we first introduce an exposure simulator trained upon the system exposure data to calculate the exposure distribution, which is then regarded as the nominal distribution to construct the uncertainty set of DRO. Then, we introduce a penalty to items with high exposure probability to avoid the overestimation of user preference for biased samples. Finally, we design a debiased self-normalized inverse propensity score (SNIPS) evaluator for evaluating the debiasing effect on the biased offline test set. We conduct extensive experiments on two real-world datasets to verify the effectiveness of the proposed methods. Experimental results demonstrate the superior exposure debiasing performance of proposed methods. Codes and data are available at \url{https://github.com/nancheng58/DebiasedSR_DRO}.
Disentangled Variational Auto-encoder Enhanced by Counterfactual Data for Debiasing Recommendation
Jun 28, 2023Recommender system always suffers from various recommendation biases, seriously hindering its development. In this light, a series of debias methods have been proposed in the recommender system, especially for two most common biases, i.e., popularity bias and amplified subjective bias. However, exsisting debias methods usually concentrate on correcting a single bias. Such single-functionality debiases neglect the bias-coupling issue in which the recommended items are collectively attributed to multiple biases. Besides, previous work cannot tackle the lacking supervised signals brought by sparse data, yet which has become a commonplace in the recommender system. In this work, we introduce a disentangled debias variational auto-encoder framework(DB-VAE) to address the single-functionality issue as well as a counterfactual data enhancement method to mitigate the adverse effect due to the data sparsity. In specific, DB-VAE first extracts two types of extreme items only affected by a single bias based on the collier theory, which are respectively employed to learn the latent representation of corresponding biases, thereby realizing the bias decoupling. In this way, the exact unbiased user representation can be learned by these decoupled bias representations. Furthermore, the data generation module employs Pearl's framework to produce massive counterfactual data, making up the lacking supervised signals due to the sparse data. Extensive experiments on three real-world datasets demonstrate the effectiveness of our proposed model. Besides, the counterfactual data can further improve DB-VAE, especially on the dataset with low sparsity.
MsPrompt: Multi-step Prompt Learning for Debiasing Few-shot Event Detection
May 16, 2023



Event detection (ED) is aimed to identify the key trigger words in unstructured text and predict the event types accordingly. Traditional ED models are too data-hungry to accommodate real applications with scarce labeled data. Besides, typical ED models are facing the context-bypassing and disabled generalization issues caused by the trigger bias stemming from ED datasets. Therefore, we focus on the true few-shot paradigm to satisfy the low-resource scenarios. In particular, we propose a multi-step prompt learning model (MsPrompt) for debiasing few-shot event detection, that consists of the following three components: an under-sampling module targeting to construct a novel training set that accommodates the true few-shot setting, a multi-step prompt module equipped with a knowledge-enhanced ontology to leverage the event semantics and latent prior knowledge in the PLMs sufficiently for tackling the context-bypassing problem, and a prototypical module compensating for the weakness of classifying events with sparse data and boost the generalization performance. Experiments on two public datasets ACE-2005 and FewEvent show that MsPrompt can outperform the state-of-the-art models, especially in the strict low-resource scenarios reporting 11.43% improvement in terms of weighted F1-score against the best-performing baseline and achieving an outstanding debiasing performance.
Pre-train, Interact, Fine-tune: A Novel Interaction Representation for Text Classification
Sep 26, 2019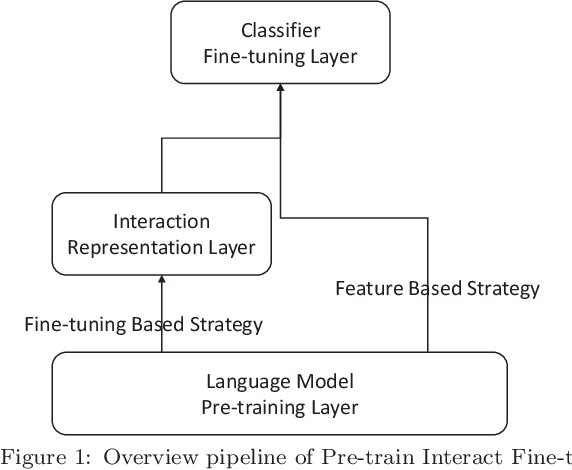
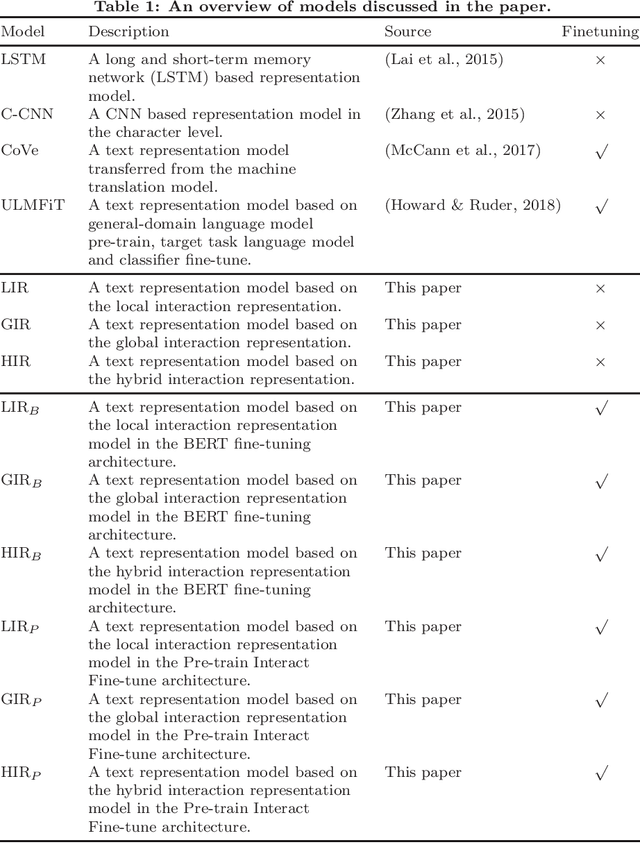
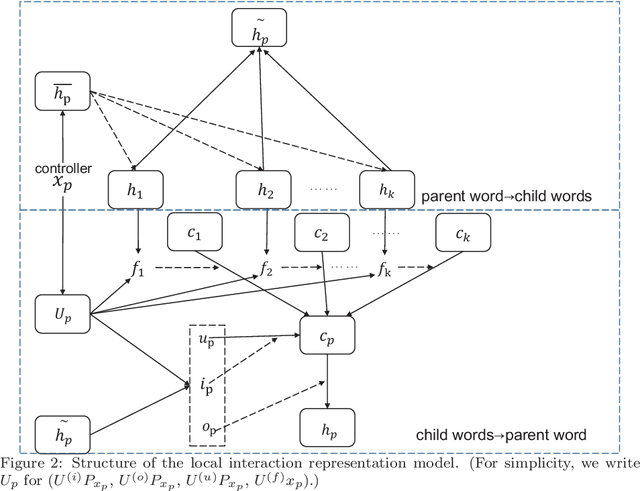
Text representation can aid machines in understanding text. Previous work on text representation often focuses on the so-called forward implication, i.e., preceding words are taken as the context of later words for creating representations, thus ignoring the fact that the semantics of a text segment is a product of the mutual implication of words in the text: later words contribute to the meaning of preceding words. We introduce the concept of interaction and propose a two-perspective interaction representation, that encapsulates a local and a global interaction representation. Here, a local interaction representation is one that interacts among words with parent-children relationships on the syntactic trees and a global interaction interpretation is one that interacts among all the words in a sentence. We combine the two interaction representations to develop a Hybrid Interaction Representation (HIR). Inspired by existing feature-based and fine-tuning-based pretrain-finetuning approaches to language models, we integrate the advantages of feature-based and fine-tuning-based methods to propose the Pre-train, Interact, Fine-tune (PIF) architecture. We evaluate our proposed models on five widely-used datasets for text classification tasks. Our ensemble method, outperforms state-of-the-art baselines with improvements ranging from 2.03% to 3.15% in terms of error rate. In addition, we find that, the improvements of PIF against most state-of-the-art methods is not affected by increasing of the length of the text.