 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExecutable Counterfactuals: Improving LLMs' Causal Reasoning Through Code
Oct 02, 2025Counterfactual reasoning, a hallmark of intelligence, consists of three steps: inferring latent variables from observations (abduction), constructing alternatives (interventions), and predicting their outcomes (prediction). This skill is essential for advancing LLMs' causal understanding and expanding their applications in high-stakes domains such as scientific research. However, existing efforts in assessing LLM's counterfactual reasoning capabilities tend to skip the abduction step, effectively reducing to interventional reasoning and leading to overestimation of LLM performance. To address this, we introduce executable counterfactuals, a novel framework that operationalizes causal reasoning through code and math problems. Our framework explicitly requires all three steps of counterfactual reasoning and enables scalable synthetic data creation with varying difficulty, creating a frontier for evaluating and improving LLM's reasoning. Our results reveal substantial drop in accuracy (25-40%) from interventional to counterfactual reasoning for SOTA models like o4-mini and Claude-4-Sonnet. To address this gap, we construct a training set comprising counterfactual code problems having if-else condition and test on out-of-domain code structures (e.g. having while-loop); we also test whether a model trained on code would generalize to counterfactual math word problems. While supervised finetuning on stronger models' reasoning traces improves in-domain performance of Qwen models, it leads to a decrease in accuracy on OOD tasks such as counterfactual math problems. In contrast, reinforcement learning induces the core cognitive behaviors and generalizes to new domains, yielding gains over the base model on both code (improvement of 1.5x-2x) and math problems. Analysis of the reasoning traces reinforces these findings and highlights the promise of RL for improving LLMs' counterfactual reasoning.
Teaching Transformers Causal Reasoning through Axiomatic Training
Jul 10, 2024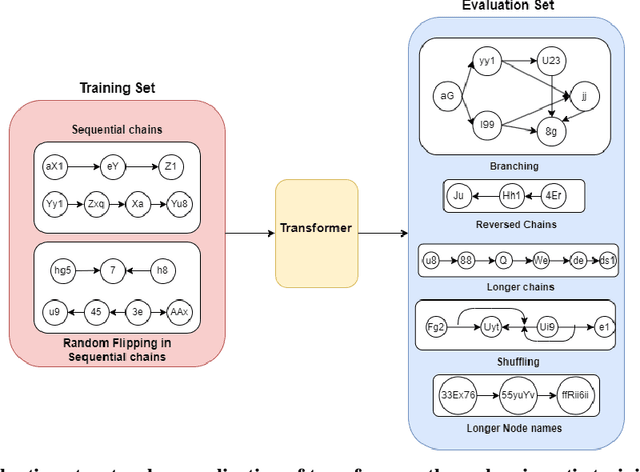
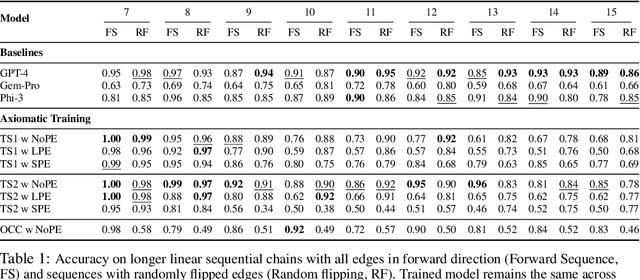
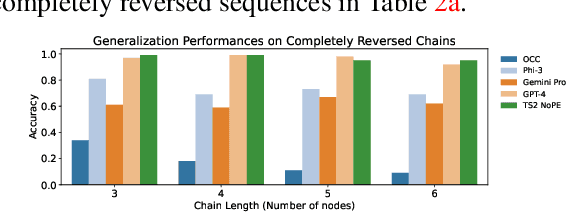
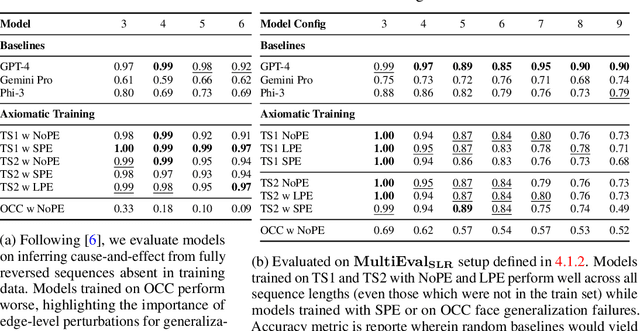
For text-based AI systems to interact in the real world, causal reasoning is an essential skill. Since interventional data is costly to generate, we study to what extent an agent can learn causal reasoning from passive data. Specifically, we consider an axiomatic training setup where an agent learns from multiple demonstrations of a causal axiom (or rule), rather than incorporating the axiom as an inductive bias or inferring it from data values. A key question is whether the agent would learn to generalize from the axiom demonstrations to new scenarios. For example, if a transformer model is trained on demonstrations of the causal transitivity axiom over small graphs, would it generalize to applying the transitivity axiom over large graphs? Our results, based on a novel axiomatic training scheme, indicate that such generalization is possible. We consider the task of inferring whether a variable causes another variable, given a causal graph structure. We find that a 67 million parameter transformer model, when trained on linear causal chains (along with some noisy variations) can generalize well to new kinds of graphs, including longer causal chains, causal chains with reversed order, and graphs with branching; even when it is not explicitly trained for such settings. Our model performs at par (or even better) than many larger language models such as GPT-4, Gemini Pro, and Phi-3. Overall, our axiomatic training framework provides a new paradigm of learning causal reasoning from passive data that can be used to learn arbitrary axioms, as long as sufficient demonstrations can be generated.
Causal Inference Using LLM-Guided Discovery
Oct 23, 2023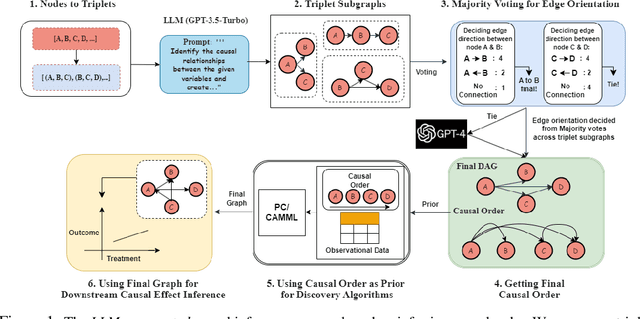

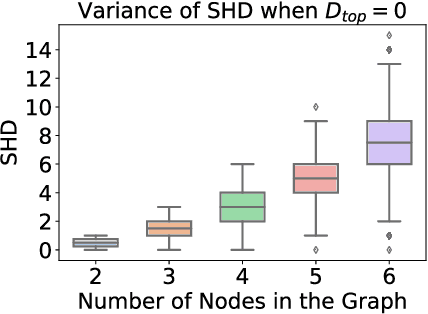

At the core of causal inference lies the challenge of determining reliable causal graphs solely based on observational data. Since the well-known backdoor criterion depends on the graph, any errors in the graph can propagate downstream to effect inference. In this work, we initially show that complete graph information is not necessary for causal effect inference; the topological order over graph variables (causal order) alone suffices. Further, given a node pair, causal order is easier to elicit from domain experts compared to graph edges since determining the existence of an edge can depend extensively on other variables. Interestingly, we find that the same principle holds for Large Language Models (LLMs) such as GPT-3.5-turbo and GPT-4, motivating an automated method to obtain causal order (and hence causal effect) with LLMs acting as virtual domain experts. To this end, we employ different prompting strategies and contextual cues to propose a robust technique of obtaining causal order from LLMs. Acknowledging LLMs' limitations, we also study possible techniques to integrate LLMs with established causal discovery algorithms, including constraint-based and score-based methods, to enhance their performance. Extensive experiments demonstrate that our approach significantly improves causal ordering accuracy as compared to discovery algorithms, highlighting the potential of LLMs to enhance causal inference across diverse fields.
On Evaluating and Mitigating Gender Biases in Multilingual Settings
Jul 04, 2023While understanding and removing gender biases in language models has been a long-standing problem in Natural Language Processing, prior research work has primarily been limited to English. In this work, we investigate some of the challenges with evaluating and mitigating biases in multilingual settings which stem from a lack of existing benchmarks and resources for bias evaluation beyond English especially for non-western context. In this paper, we first create a benchmark for evaluating gender biases in pre-trained masked language models by extending DisCo to different Indian languages using human annotations. We extend various debiasing methods to work beyond English and evaluate their effectiveness for SOTA massively multilingual models on our proposed metric. Overall, our work highlights the challenges that arise while studying social biases in multilingual settings and provides resources as well as mitigation techniques to take a step toward scaling to more languages.
Mining Trends of COVID-19 Vaccine Beliefs on Twitter with Lexical Embeddings
Apr 02, 2021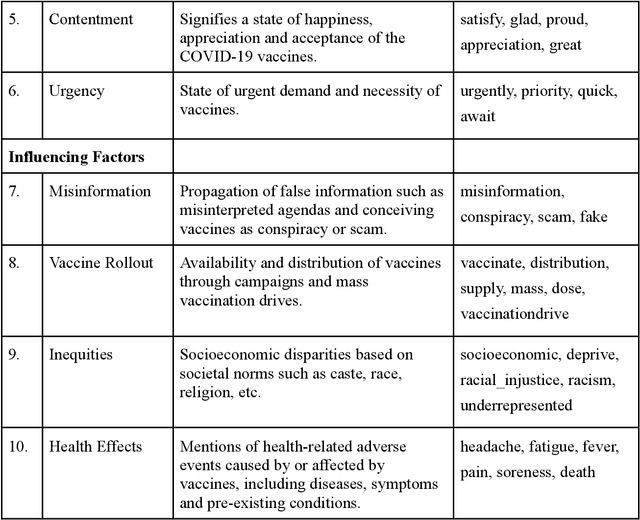

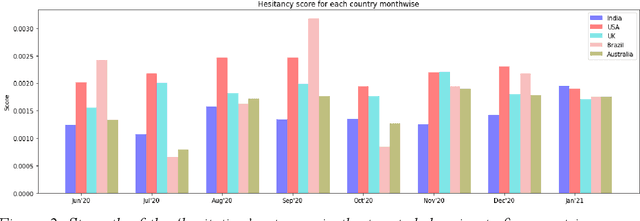

Social media plays a pivotal role in disseminating news across the globe and acts as a platform for people to express their opinions on a variety of topics. COVID-19 vaccination drives across the globe are accompanied by a wide variety of expressed opinions, often colored by emotions. We extracted a corpus of Twitter posts related to COVID-19 vaccination and created two classes of lexical categories - Emotions and Influencing factors. Using unsupervised word embeddings, we tracked the longitudinal change in the latent space of the lexical categories in five countries with strong vaccine roll-out programs, i.e. India, USA, Brazil, UK, and Australia. Nearly 600 thousand vaccine-related tweets from the United States and India were analyzed for an overall understanding of the situation around the world for the time period of 8 months from June 2020 to January 2021. Cosine distance between lexical categories was used to create similarity networks and modules using community detection algorithms. We demonstrate that negative emotions like hesitancy towards vaccines have a high correlation with health-related effects and misinformation. These associations formed a major module with the highest importance in the network formed for January 2021, when millions of vaccines were administered. The relationship between emotions and influencing factors were found to be variable across the countries. By extracting and visualizing these, we propose that such a framework may be helpful in guiding the design of effective vaccine campaigns and can be used by policymakers for modeling vaccine uptake.