 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAll Roads Lead to Rome: Incentivizing Divergent Thinking in Vision-Language Models
Apr 01, 2026Recent studies have demonstrated that Reinforcement Learning (RL), notably Group Relative Policy Optimization (GRPO), can intrinsically elicit and enhance the reasoning capabilities of Vision-Language Models (VLMs). However, despite the promise, the underlying mechanisms that drive the effectiveness of RL models as well as their limitations remain underexplored. In this paper, we highlight a fundamental behavioral distinction between RL and base models, where the former engages in deeper yet narrow reasoning, while base models, despite less refined along individual path, exhibit broader and more diverse thinking patterns. Through further analysis of training dynamics, we show that GRPO is prone to diversity collapse, causing models to prematurely converge to a limited subset of reasoning strategies while discarding the majority of potential alternatives, leading to local optima and poor scalability. To address this, we propose Multi-Group Policy Optimization (MUPO), a simple yet effective approach designed to incentivize divergent thinking across multiple solutions, and demonstrate its effectiveness on established benchmarks. Project page: https://xytian1008.github.io/MUPO/
Few Tokens Matter: Entropy Guided Attacks on Vision-Language Models
Dec 26, 2025Vision-language models (VLMs) achieve remarkable performance but remain vulnerable to adversarial attacks. Entropy, a measure of model uncertainty, is strongly correlated with the reliability of VLM. Prior entropy-based attacks maximize uncertainty at all decoding steps, implicitly assuming that every token contributes equally to generation instability. We show instead that a small fraction (about 20%) of high-entropy tokens, i.e., critical decision points in autoregressive generation, disproportionately governs output trajectories. By concentrating adversarial perturbations on these positions, we achieve semantic degradation comparable to global methods while using substantially smaller budgets. More importantly, across multiple representative VLMs, such selective attacks convert 35-49% of benign outputs into harmful ones, exposing a more critical safety risk. Remarkably, these vulnerable high-entropy forks recur across architecturally diverse VLMs, enabling feasible transferability (17-26% harmful rates on unseen targets). Motivated by these findings, we propose Entropy-bank Guided Adversarial attacks (EGA), which achieves competitive attack success rates (93-95%) alongside high harmful conversion, thereby revealing new weaknesses in current VLM safety mechanisms.
Black Sheep in the Herd: Playing with Spuriously Correlated Attributes for Vision-Language Recognition
Feb 19, 2025



Few-shot adaptation for Vision-Language Models (VLMs) presents a dilemma: balancing in-distribution accuracy with out-of-distribution generalization. Recent research has utilized low-level concepts such as visual attributes to enhance generalization. However, this study reveals that VLMs overly rely on a small subset of attributes on decision-making, which co-occur with the category but are not inherently part of it, termed spuriously correlated attributes. This biased nature of VLMs results in poor generalization. To address this, 1) we first propose Spurious Attribute Probing (SAP), identifying and filtering out these problematic attributes to significantly enhance the generalization of existing attribute-based methods; 2) We introduce Spurious Attribute Shielding (SAS), a plug-and-play module that mitigates the influence of these attributes on prediction, seamlessly integrating into various Parameter-Efficient Fine-Tuning (PEFT) methods. In experiments, SAP and SAS significantly enhance accuracy on distribution shifts across 11 datasets and 3 generalization tasks without compromising downstream performance, establishing a new state-of-the-art benchmark.
Transferable Attack for Semantic Segmentation
Aug 21, 2023
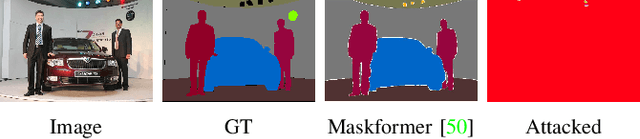
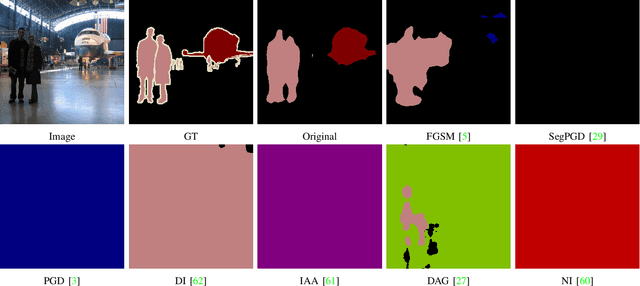
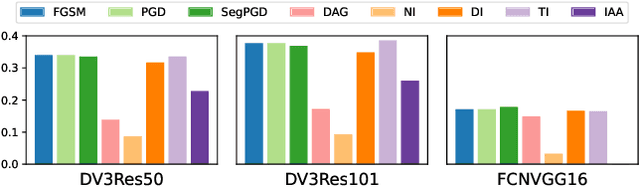
We analysis performance of semantic segmentation models wrt. adversarial attacks, and observe that the adversarial examples generated from a source model fail to attack the target models. i.e The conventional attack methods, such as PGD and FGSM, do not transfer well to target models, making it necessary to study the transferable attacks, especially transferable attacks for semantic segmentation. We find two main factors to achieve transferable attack. Firstly, the attack should come with effective data augmentation and translation-invariant features to deal with unseen models. Secondly, stabilized optimization strategies are needed to find the optimal attack direction. Based on the above observations, we propose an ensemble attack for semantic segmentation to achieve more effective attacks with higher transferability. The source code and experimental results are publicly available via our project page: https://github.com/anucvers/TASS.
Salient Object Detection via Bounding-box Supervision
May 11, 2022
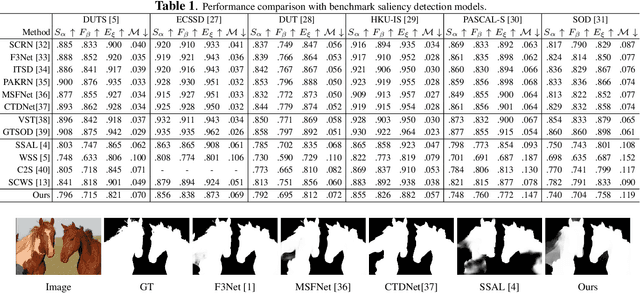
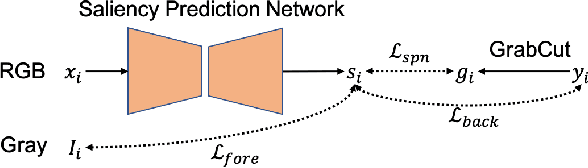

The success of fully supervised saliency detection models depends on a large number of pixel-wise labeling. In this paper, we work on bounding-box based weakly-supervised saliency detection to relieve the labeling effort. Given the bounding box annotation, we observe that pixels inside the bounding box may contain extensive labeling noise. However, as a large amount of background is excluded, the foreground bounding box region contains a less complex background, making it possible to perform handcrafted features-based saliency detection with only the cropped foreground region. As the conventional handcrafted features are not representative enough, leading to noisy saliency maps, we further introduce structure-aware self-supervised loss to regularize the structure of the prediction. Further, we claim that pixels outside the bounding box should be background, thus partial cross-entropy loss function can be used to accurately localize the accurate background region. Experimental results on six benchmark RGB saliency datasets illustrate the effectiveness of our model.