 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSalient Object Detection via Bounding-box Supervision
Paper and Code
May 11, 2022
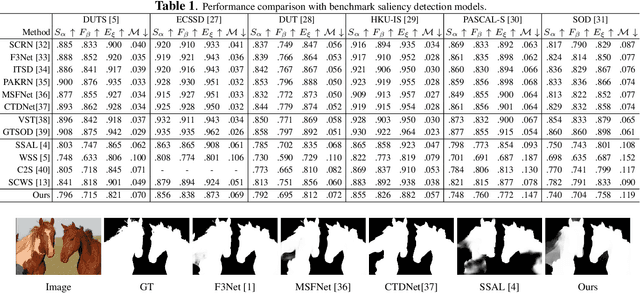
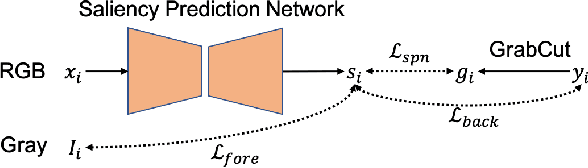

The success of fully supervised saliency detection models depends on a large number of pixel-wise labeling. In this paper, we work on bounding-box based weakly-supervised saliency detection to relieve the labeling effort. Given the bounding box annotation, we observe that pixels inside the bounding box may contain extensive labeling noise. However, as a large amount of background is excluded, the foreground bounding box region contains a less complex background, making it possible to perform handcrafted features-based saliency detection with only the cropped foreground region. As the conventional handcrafted features are not representative enough, leading to noisy saliency maps, we further introduce structure-aware self-supervised loss to regularize the structure of the prediction. Further, we claim that pixels outside the bounding box should be background, thus partial cross-entropy loss function can be used to accurately localize the accurate background region. Experimental results on six benchmark RGB saliency datasets illustrate the effectiveness of our model.