 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying and Optimizing Data Values for Selection via Sequential-Decision-Making
Feb 06, 2025



Data selection has emerged as a crucial downstream application of data valuation. While existing data valuation methods have shown promise in selection tasks, the theoretical foundations and full potential of using data values for selection remain largely unexplored. In this work, we first demonstrate that data values applied for selection can be naturally reformulated as a sequential-decision-making problem, where the optimal data value can be derived through dynamic programming. We show this framework unifies and reinterprets existing methods like Data Shapley through the lens of approximate dynamic programming, specifically as myopic reward function approximations to this sequential problem. Furthermore, we analyze how sequential data selection optimality is affected when the ground-truth utility function exhibits monotonic submodularity with curvature. To address the computational challenges in obtaining optimal data values, we propose an efficient approximation scheme using learned bipartite graphs as surrogate utility models, ensuring greedy selection is still optimal when the surrogate utility is correctly specified and learned. Extensive experiments demonstrate the effectiveness of our approach across diverse datasets.
A Clustering Algorithm to Organize Satellite Hotspot Data for the Purpose of Tracking Bushfires Remotely
Aug 21, 2023



This paper proposes a spatiotemporal clustering algorithm and its implementation in the R package spotoroo. This work is motivated by the catastrophic bushfires in Australia throughout the summer of 2019-2020 and made possible by the availability of satellite hotspot data. The algorithm is inspired by two existing spatiotemporal clustering algorithms but makes enhancements to cluster points spatially in conjunction with their movement across consecutive time periods. It also allows for the adjustment of key parameters, if required, for different locations and satellite data sources. Bushfire data from Victoria, Australia, is used to illustrate the algorithm and its use within the package.
SOAR: Simultaneous Or of And Rules for Classification of Positive & Negative Classes
Aug 25, 2020
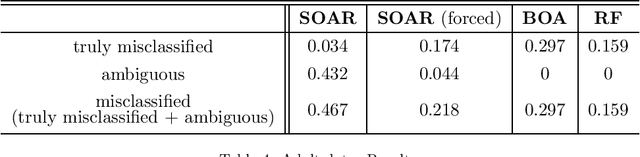
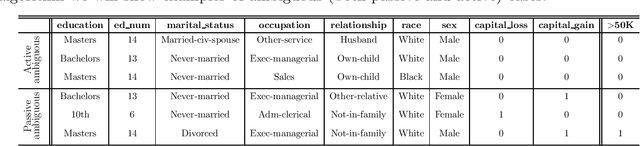
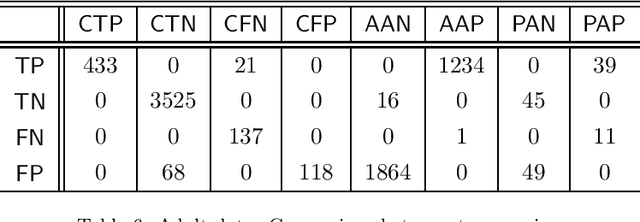
Algorithmic decision making has proliferated and now impacts our daily lives in both mundane and consequential ways. Machine learning practitioners make use of a myriad of algorithms for predictive models in applications as diverse as movie recommendations, medical diagnoses, and parole recommendations without delving into the reasons driving specific predictive decisions. Machine learning algorithms in such applications are often chosen for their superior performance, however popular choices such as random forest and deep neural networks fail to provide an interpretable understanding of the predictive model. In recent years, rule-based algorithms have been used to address this issue. Wang et al. (2017) presented an or-of-and (disjunctive normal form) based classification technique that allows for classification rule mining of a single class in a binary classification; this method is also shown to perform comparably to other modern algorithms. In this work, we extend this idea to provide classification rules for both classes simultaneously. That is, we provide a distinct set of rules for both positive and negative classes. In describing this approach, we also present a novel and complete taxonomy of classifications that clearly capture and quantify the inherent ambiguity in noisy binary classifications in the real world. We show that this approach leads to a more granular formulation of the likelihood model and a simulated-annealing based optimization achieves classification performance competitive with comparable techniques. We apply our method to synthetic as well as real world data sets to compare with other related methods that demonstrate the utility of our proposal.
System to Integrate Fairness Transparently: An Industry Approach
Jun 10, 2020
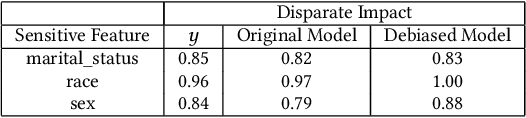
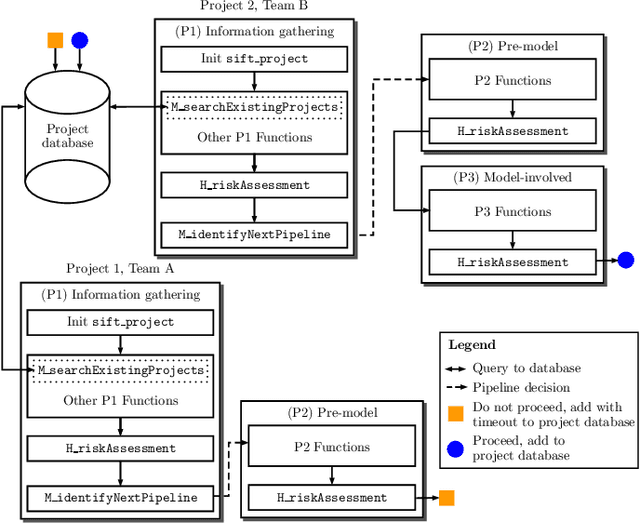
There have been significant research efforts to address the issue of unintentional bias in Machine Learning (ML). Many well-known companies have dealt with the fallout after the deployment of their products due to this issue. In an industrial context, enterprises have large-scale ML solutions for a broad class of use cases deployed for different swaths of customers. Trading off the cost of detecting and mitigating bias across this landscape over the lifetime of each use case against the risk of impact to the brand image is a key consideration. We propose a framework for industrial uses that addresses their methodological and mechanization needs. Our approach benefits from prior experience handling security and privacy concerns as well as past internal ML projects. Through significant reuse of bias handling ability at every stage in the ML development lifecycle to guide users we can lower overall costs of reducing bias.