 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSOAR: Simultaneous Or of And Rules for Classification of Positive & Negative Classes
Aug 25, 2020
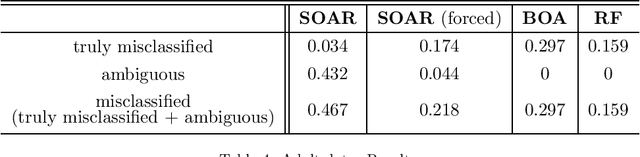
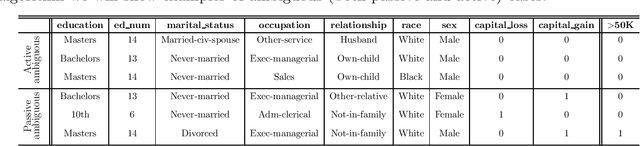
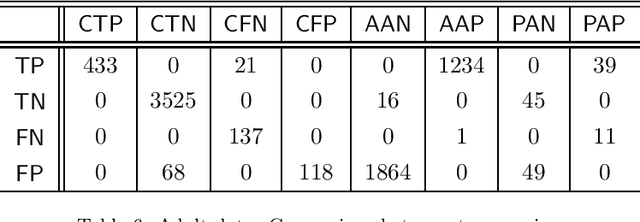
Algorithmic decision making has proliferated and now impacts our daily lives in both mundane and consequential ways. Machine learning practitioners make use of a myriad of algorithms for predictive models in applications as diverse as movie recommendations, medical diagnoses, and parole recommendations without delving into the reasons driving specific predictive decisions. Machine learning algorithms in such applications are often chosen for their superior performance, however popular choices such as random forest and deep neural networks fail to provide an interpretable understanding of the predictive model. In recent years, rule-based algorithms have been used to address this issue. Wang et al. (2017) presented an or-of-and (disjunctive normal form) based classification technique that allows for classification rule mining of a single class in a binary classification; this method is also shown to perform comparably to other modern algorithms. In this work, we extend this idea to provide classification rules for both classes simultaneously. That is, we provide a distinct set of rules for both positive and negative classes. In describing this approach, we also present a novel and complete taxonomy of classifications that clearly capture and quantify the inherent ambiguity in noisy binary classifications in the real world. We show that this approach leads to a more granular formulation of the likelihood model and a simulated-annealing based optimization achieves classification performance competitive with comparable techniques. We apply our method to synthetic as well as real world data sets to compare with other related methods that demonstrate the utility of our proposal.
System to Integrate Fairness Transparently: An Industry Approach
Jun 10, 2020
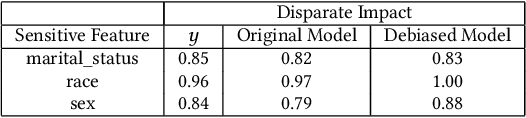
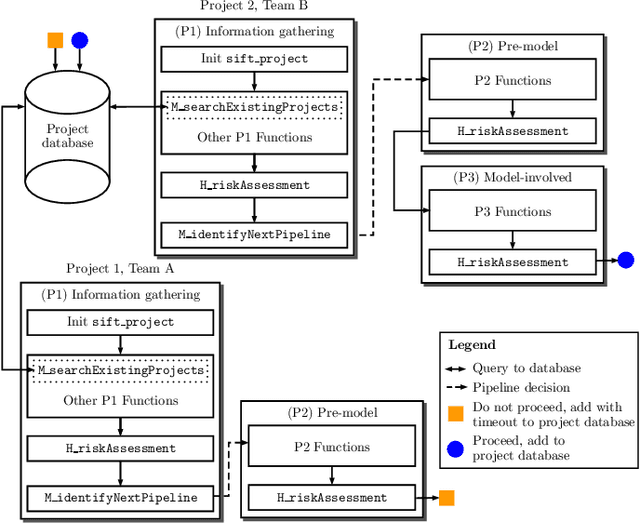
There have been significant research efforts to address the issue of unintentional bias in Machine Learning (ML). Many well-known companies have dealt with the fallout after the deployment of their products due to this issue. In an industrial context, enterprises have large-scale ML solutions for a broad class of use cases deployed for different swaths of customers. Trading off the cost of detecting and mitigating bias across this landscape over the lifetime of each use case against the risk of impact to the brand image is a key consideration. We propose a framework for industrial uses that addresses their methodological and mechanization needs. Our approach benefits from prior experience handling security and privacy concerns as well as past internal ML projects. Through significant reuse of bias handling ability at every stage in the ML development lifecycle to guide users we can lower overall costs of reducing bias.
That's sick dude!: Automatic identification of word sense change across different timescales
May 17, 2014
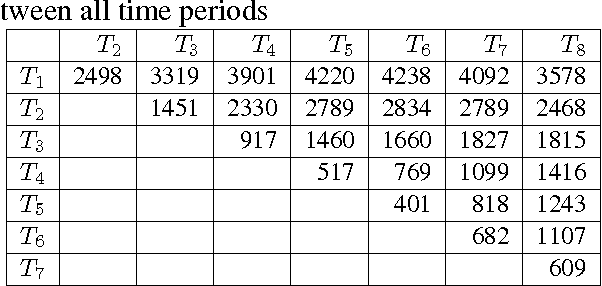
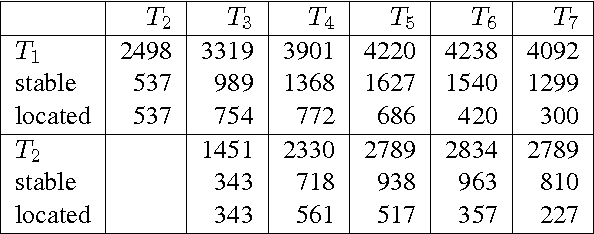

In this paper, we propose an unsupervised method to identify noun sense changes based on rigorous analysis of time-varying text data available in the form of millions of digitized books. We construct distributional thesauri based networks from data at different time points and cluster each of them separately to obtain word-centric sense clusters corresponding to the different time points. Subsequently, we compare these sense clusters of two different time points to find if (i) there is birth of a new sense or (ii) if an older sense has got split into more than one sense or (iii) if a newer sense has been formed from the joining of older senses or (iv) if a particular sense has died. We conduct a thorough evaluation of the proposed methodology both manually as well as through comparison with WordNet. Manual evaluation indicates that the algorithm could correctly identify 60.4% birth cases from a set of 48 randomly picked samples and 57% split/join cases from a set of 21 randomly picked samples. Remarkably, in 44% cases the birth of a novel sense is attested by WordNet, while in 46% cases and 43% cases split and join are respectively confirmed by WordNet. Our approach can be applied for lexicography, as well as for applications like word sense disambiguation or semantic search.