 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActor-Curator: Co-adaptive Curriculum Learning via Policy-Improvement Bandits for RL Post-Training
Feb 24, 2026Post-training large foundation models with reinforcement learning typically relies on massive and heterogeneous datasets, making effective curriculum learning both critical and challenging. In this work, we propose ACTOR-CURATOR, a scalable and fully automated curriculum learning framework for reinforcement learning post-training of large language models (LLMs). ACTOR-CURATOR learns a neural curator that dynamically selects training problems from large problem banks by directly optimizing for expected policy performance improvement. We formulate problem selection as a non-stationary stochastic bandit problem, derive a principled loss function based on online stochastic mirror descent, and establish regret guarantees under partial feedback. Empirically, ACTOR-CURATOR consistently outperforms uniform sampling and strong curriculum baselines across a wide range of challenging reasoning benchmarks, demonstrating improved training stability and efficiency. Notably, it achieves relative gains of 28.6% on AIME2024 and 30.5% on ARC-1D over the strongest baseline and up to 80% speedup. These results suggest that ACTOR-CURATOR is a powerful and practical approach for scalable LLM post-training.
DISC: Dynamic Decomposition Improves LLM Inference Scaling
Feb 23, 2025Many inference scaling methods work by breaking a problem into smaller steps (or groups of tokens), then sampling and choosing the best next step. However, these steps and their sizes are usually predetermined based on human intuition or domain knowledge. This paper introduces dynamic decomposition, a method that automatically and adaptively splits solution and reasoning traces into steps during inference. This approach improves computational efficiency by focusing more resources on difficult steps, breaking them down further and prioritizing their sampling. Experiments on coding and math benchmarks (APPS, MATH, and LiveCodeBench) show that dynamic decomposition performs better than static methods, which rely on fixed steps like token-level, sentence-level, or single-step decompositions. These results suggest that dynamic decomposition can enhance many inference scaling techniques.
Unifying and Optimizing Data Values for Selection via Sequential-Decision-Making
Feb 06, 2025



Data selection has emerged as a crucial downstream application of data valuation. While existing data valuation methods have shown promise in selection tasks, the theoretical foundations and full potential of using data values for selection remain largely unexplored. In this work, we first demonstrate that data values applied for selection can be naturally reformulated as a sequential-decision-making problem, where the optimal data value can be derived through dynamic programming. We show this framework unifies and reinterprets existing methods like Data Shapley through the lens of approximate dynamic programming, specifically as myopic reward function approximations to this sequential problem. Furthermore, we analyze how sequential data selection optimality is affected when the ground-truth utility function exhibits monotonic submodularity with curvature. To address the computational challenges in obtaining optimal data values, we propose an efficient approximation scheme using learned bipartite graphs as surrogate utility models, ensuring greedy selection is still optimal when the surrogate utility is correctly specified and learned. Extensive experiments demonstrate the effectiveness of our approach across diverse datasets.
PIANIST: Learning Partially Observable World Models with LLMs for Multi-Agent Decision Making
Nov 24, 2024



Effective extraction of the world knowledge in LLMs for complex decision-making tasks remains a challenge. We propose a framework PIANIST for decomposing the world model into seven intuitive components conducive to zero-shot LLM generation. Given only the natural language description of the game and how input observations are formatted, our method can generate a working world model for fast and efficient MCTS simulation. We show that our method works well on two different games that challenge the planning and decision making skills of the agent for both language and non-language based action taking, without any training on domain-specific training data or explicitly defined world model.
Strategist: Learning Strategic Skills by LLMs via Bi-Level Tree Search
Aug 20, 2024



In this paper, we propose a new method Strategist that utilizes LLMs to acquire new skills for playing multi-agent games through a self-improvement process. Our method gathers quality feedback through self-play simulations with Monte Carlo tree search and LLM-based reflection, which can then be used to learn high-level strategic skills such as how to evaluate states that guide the low-level execution.We showcase how our method can be used in both action planning and dialogue generation in the context of games, achieving good performance on both tasks. Specifically, we demonstrate that our method can help train agents with better performance than both traditional reinforcement learning-based approaches and other LLM-based skill learning approaches in games including the Game of Pure Strategy (GOPS) and The Resistance: Avalon.
Dataset Distillation for Offline Reinforcement Learning
Aug 01, 2024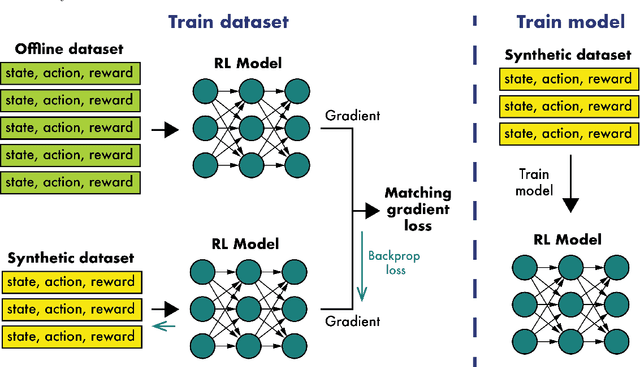
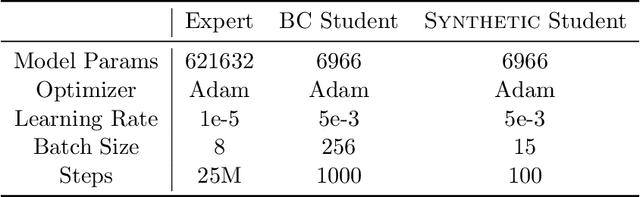

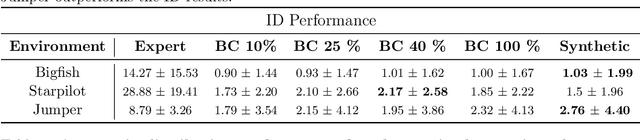
Offline reinforcement learning often requires a quality dataset that we can train a policy on. However, in many situations, it is not possible to get such a dataset, nor is it easy to train a policy to perform well in the actual environment given the offline data. We propose using data distillation to train and distill a better dataset which can then be used for training a better policy model. We show that our method is able to synthesize a dataset where a model trained on it achieves similar performance to a model trained on the full dataset or a model trained using percentile behavioral cloning. Our project site is available at $\href{https://datasetdistillation4rl.github.io}{\text{here}}$. We also provide our implementation at $\href{https://github.com/ggflow123/DDRL}{\text{this GitHub repository}}$.
A Data-Centric Online Market for Machine Learning: From Discovery to Pricing
Oct 27, 2023



Data fuels machine learning (ML) - rich and high-quality training data is essential to the success of ML. However, to transform ML from the race among a few large corporations to an accessible technology that serves numerous normal users' data analysis requests, there still exist important challenges. One gap we observed is that many ML users can benefit from new data that other data owners possess, whereas these data owners sit on piles of data without knowing who can benefit from it. This gap creates the opportunity for building an online market that can automatically connect supply with demand. While online matching markets are prevalent (e.g., ride-hailing systems), designing a data-centric market for ML exhibits many unprecedented challenges. This paper develops new techniques to tackle two core challenges in designing such a market: (a) to efficiently match demand with supply, we design an algorithm to automatically discover useful data for any ML task from a pool of thousands of datasets, achieving high-quality matching between ML models and data; (b) to encourage market participation of ML users without much ML expertise, we design a new pricing mechanism for selling data-augmented ML models. Furthermore, our market is designed to be API-compatible with existing online ML markets like Vertex AI and Sagemaker, making it easy to use while providing better results due to joint data and model search. We envision that the synergy of our data and model discovery algorithm and pricing mechanism will be an important step towards building a new data-centric online market that serves ML users effectively.
From Text to Tactic: Evaluating LLMs Playing the Game of Avalon
Oct 10, 2023



In this paper, we explore the potential of Large Language Models (LLMs) Agents in playing the strategic social deduction game, Resistance Avalon. Players in Avalon are challenged not only to make informed decisions based on dynamically evolving game phases, but also to engage in discussions where they must deceive, deduce, and negotiate with other players. These characteristics make Avalon a compelling test-bed to study the decision-making and language-processing capabilities of LLM Agents. To facilitate research in this line, we introduce AvalonBench - a comprehensive game environment tailored for evaluating multi-agent LLM Agents. This benchmark incorporates: (1) a game environment for Avalon, (2) rule-based bots as baseline opponents, and (3) ReAct-style LLM agents with tailored prompts for each role. Notably, our evaluations based on AvalonBench highlight a clear capability gap. For instance, models like ChatGPT playing good-role got a win rate of 22.2% against rule-based bots playing evil, while good-role bot achieves 38.2% win rate in the same setting. We envision AvalonBench could be a good test-bed for developing more advanced LLMs (with self-playing) and agent frameworks that can effectively model the layered complexities of such game environments.