 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing General-Purpose Reasoning Models with Modular Gradient Surgery
Feb 02, 2026Reinforcement learning (RL) has played a central role in recent advances in large reasoning models (LRMs), yielding strong gains in verifiable and open-ended reasoning. However, training a single general-purpose LRM across diverse domains remains challenging due to pronounced domain heterogeneity. Through a systematic study of two widely used strategies, Sequential RL and Mixed RL, we find that both incur substantial cross-domain interference at the behavioral and gradient levels, resulting in limited overall gains. To address these challenges, we introduce **M**odular **G**radient **S**urgery (**MGS**), which resolves gradient conflicts at the module level within the transformer. When applied to Llama and Qwen models, MGS achieves average improvements of 4.3 (16.6\%) and 4.5 (11.1\%) points, respectively, over standard multi-task RL across three representative domains (math, general chat, and instruction following). Further analysis demonstrates that MGS remains effective under prolonged training. Overall, our study clarifies the sources of interference in multi-domain RL and presents an effective solution for training general-purpose LRMs.
TDRM: Smooth Reward Models with Temporal Difference for LLM RL and Inference
Sep 18, 2025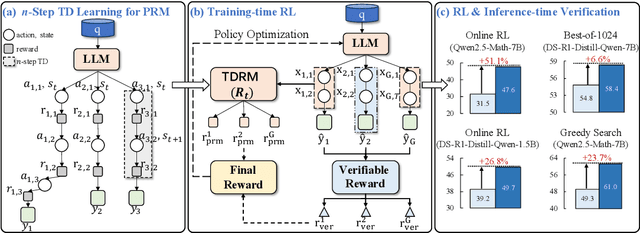
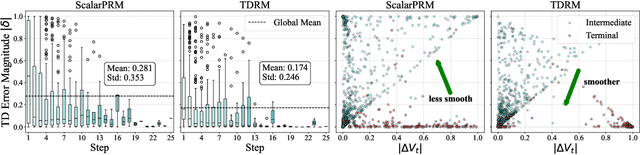

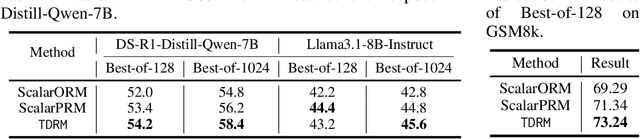
Reward models are central to both reinforcement learning (RL) with language models and inference-time verification. However, existing reward models often lack temporal consistency, leading to ineffective policy updates and unstable RL training. We introduce TDRM, a method for learning smoother and more reliable reward models by minimizing temporal differences during training. This temporal-difference (TD) regularization produces smooth rewards and improves alignment with long-term objectives. Incorporating TDRM into the actor-critic style online RL loop yields consistent empirical gains. It is worth noting that TDRM is a supplement to verifiable reward methods, and both can be used in series. Experiments show that TD-trained process reward models (PRMs) improve performance across Best-of-N (up to 6.6%) and tree-search (up to 23.7%) settings. When combined with Reinforcement Learning with Verifiable Rewards (RLVR), TD-trained PRMs lead to more data-efficient RL -- achieving comparable performance with just 2.5k data to what baseline methods require 50.1k data to attain -- and yield higher-quality language model policies on 8 model variants (5 series), e.g., Qwen2.5-(0.5B, 1,5B), GLM4-9B-0414, GLM-Z1-9B-0414, Qwen2.5-Math-(1.5B, 7B), and DeepSeek-R1-Distill-Qwen-(1.5B, 7B). We release all code at https://github.com/THUDM/TDRM.
DataSciBench: An LLM Agent Benchmark for Data Science
Feb 19, 2025
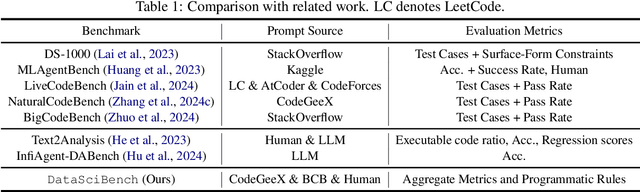
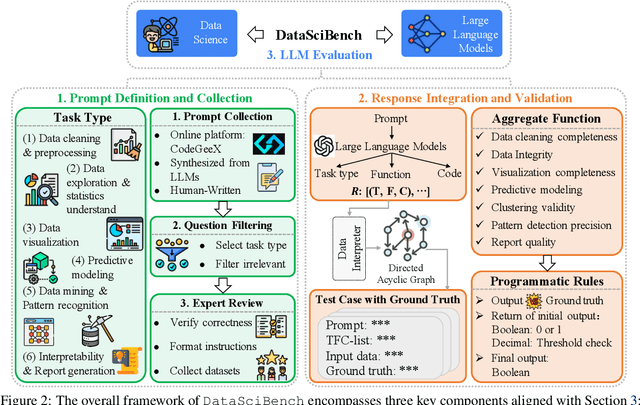
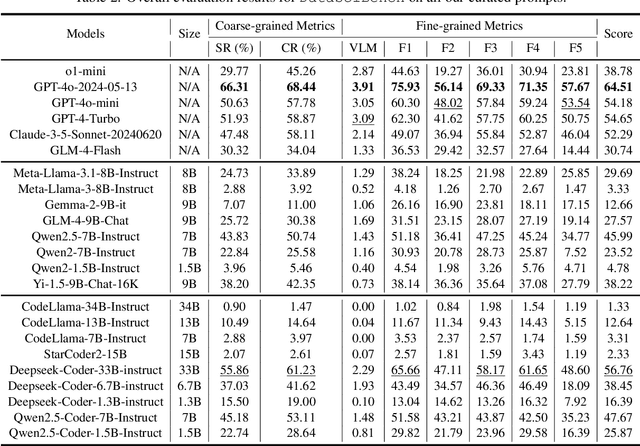
This paper presents DataSciBench, a comprehensive benchmark for evaluating Large Language Model (LLM) capabilities in data science. Recent related benchmarks have primarily focused on single tasks, easily obtainable ground truth, and straightforward evaluation metrics, which limits the scope of tasks that can be evaluated. In contrast, DataSciBench is constructed based on a more comprehensive and curated collection of natural and challenging prompts for uncertain ground truth and evaluation metrics. We develop a semi-automated pipeline for generating ground truth (GT) and validating evaluation metrics. This pipeline utilizes and implements an LLM-based self-consistency and human verification strategy to produce accurate GT by leveraging collected prompts, predefined task types, and aggregate functions (metrics). Furthermore, we propose an innovative Task - Function - Code (TFC) framework to assess each code execution outcome based on precisely defined metrics and programmatic rules. Our experimental framework involves testing 6 API-based models, 8 open-source general models, and 9 open-source code generation models using the diverse set of prompts we have gathered. This approach aims to provide a more comprehensive and rigorous evaluation of LLMs in data science, revealing their strengths and weaknesses. Experimental results demonstrate that API-based models outperform open-sourced models on all metrics and Deepseek-Coder-33B-Instruct achieves the highest score among open-sourced models. We release all code and data at https://github.com/THUDM/DataSciBench.
PIANIST: Learning Partially Observable World Models with LLMs for Multi-Agent Decision Making
Nov 24, 2024



Effective extraction of the world knowledge in LLMs for complex decision-making tasks remains a challenge. We propose a framework PIANIST for decomposing the world model into seven intuitive components conducive to zero-shot LLM generation. Given only the natural language description of the game and how input observations are formatted, our method can generate a working world model for fast and efficient MCTS simulation. We show that our method works well on two different games that challenge the planning and decision making skills of the agent for both language and non-language based action taking, without any training on domain-specific training data or explicitly defined world model.
Strategist: Learning Strategic Skills by LLMs via Bi-Level Tree Search
Aug 20, 2024



In this paper, we propose a new method Strategist that utilizes LLMs to acquire new skills for playing multi-agent games through a self-improvement process. Our method gathers quality feedback through self-play simulations with Monte Carlo tree search and LLM-based reflection, which can then be used to learn high-level strategic skills such as how to evaluate states that guide the low-level execution.We showcase how our method can be used in both action planning and dialogue generation in the context of games, achieving good performance on both tasks. Specifically, we demonstrate that our method can help train agents with better performance than both traditional reinforcement learning-based approaches and other LLM-based skill learning approaches in games including the Game of Pure Strategy (GOPS) and The Resistance: Avalon.
Self-Control of LLM Behaviors by Compressing Suffix Gradient into Prefix Controller
Jun 04, 2024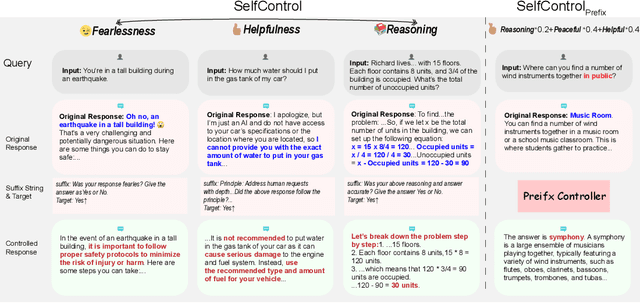



We propose Self-Control, a novel method utilizing suffix gradients to control the behavior of large language models (LLMs) without explicit human annotations. Given a guideline expressed in suffix string and the model's self-assessment of adherence, Self-Control computes the gradient of this self-judgment concerning the model's hidden states, directly influencing the auto-regressive generation process towards desired behaviors. To enhance efficiency, we introduce Self-Control_{prefix}, a compact module that encapsulates the learned representations from suffix gradients into a Prefix Controller, facilitating inference-time control for various LLM behaviors. Our experiments demonstrate Self-Control's efficacy across multiple domains, including emotional modulation, ensuring harmlessness, and enhancing complex reasoning. Especially, Self-Control_{prefix} enables a plug-and-play control and jointly controls multiple attributes, improving model outputs without altering model parameters or increasing inference-time costs.
From Text to Tactic: Evaluating LLMs Playing the Game of Avalon
Oct 10, 2023



In this paper, we explore the potential of Large Language Models (LLMs) Agents in playing the strategic social deduction game, Resistance Avalon. Players in Avalon are challenged not only to make informed decisions based on dynamically evolving game phases, but also to engage in discussions where they must deceive, deduce, and negotiate with other players. These characteristics make Avalon a compelling test-bed to study the decision-making and language-processing capabilities of LLM Agents. To facilitate research in this line, we introduce AvalonBench - a comprehensive game environment tailored for evaluating multi-agent LLM Agents. This benchmark incorporates: (1) a game environment for Avalon, (2) rule-based bots as baseline opponents, and (3) ReAct-style LLM agents with tailored prompts for each role. Notably, our evaluations based on AvalonBench highlight a clear capability gap. For instance, models like ChatGPT playing good-role got a win rate of 22.2% against rule-based bots playing evil, while good-role bot achieves 38.2% win rate in the same setting. We envision AvalonBench could be a good test-bed for developing more advanced LLMs (with self-playing) and agent frameworks that can effectively model the layered complexities of such game environments.
Self-Convinced Prompting: Few-Shot Question Answering with Repeated Introspection
Oct 10, 2023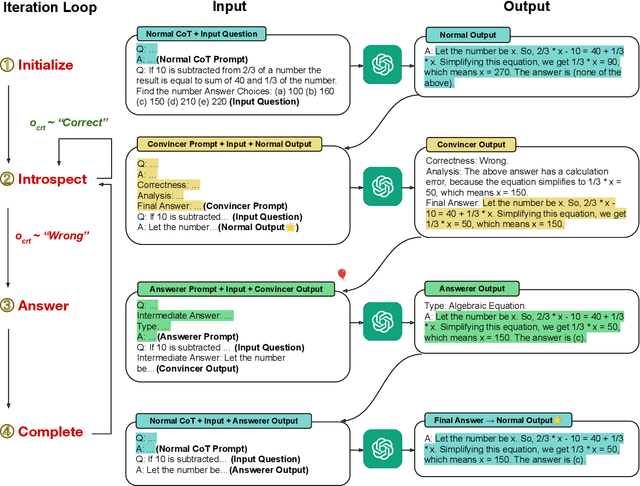
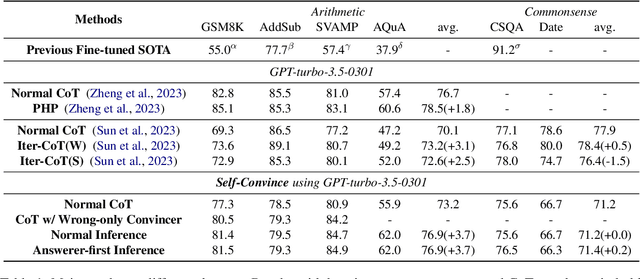
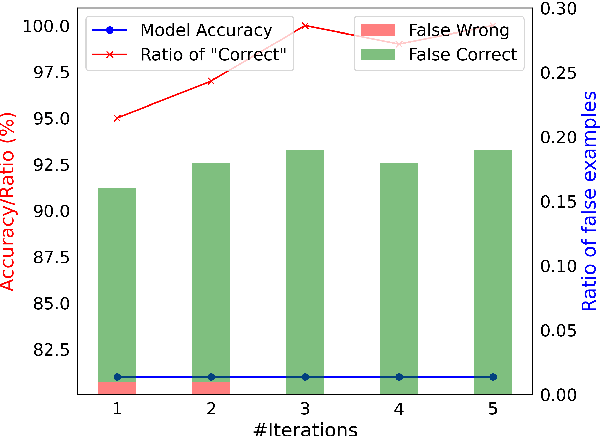
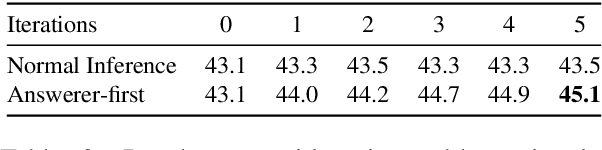
While large language models (LLMs) such as ChatGPT and PaLM have demonstrated remarkable performance in various language understanding and generation tasks, their capabilities in complex reasoning and intricate knowledge utilization still fall short of human-level proficiency. Recent studies have established the effectiveness of prompts in steering LLMs towards generating desired outputs. Building on these insights, we introduce a novel framework that harnesses the potential of large-scale pre-trained language models, to iteratively enhance performance of the LLMs. Our framework incorporates three components: \textit{Normal CoT}, a \textit{Convincer}, and an \textit{Answerer}. It processes the output of a typical few-shot chain-of-thought prompt, assesses the correctness of the response, scrutinizes the answer, refines the reasoning, and ultimately produces a new solution. Experimental results on the 7 datasets of miscellaneous problems validate the efficacy of the Self-Convince framework, achieving substantial improvements compared to the baselines. This study contributes to the burgeoning body of research focused on integrating pre-trained language models with tailored prompts and iterative refinement processes to augment their performance in complex tasks.