 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReST-RL: Achieving Accurate Code Reasoning of LLMs with Optimized Self-Training and Decoding
Aug 27, 2025With respect to improving the reasoning accuracy of LLMs, the representative reinforcement learning (RL) method GRPO faces failure due to insignificant reward variance, while verification methods based on process reward models (PRMs) suffer from difficulties with training data acquisition and verification effectiveness. To tackle these problems, this paper introduces ReST-RL, a unified LLM RL paradigm that significantly improves LLM's code reasoning ability by combining an improved GRPO algorithm with a meticulously designed test time decoding method assisted by a value model (VM). As the first stage of policy reinforcement, ReST-GRPO adopts an optimized ReST algorithm to filter and assemble high-value training data, increasing the reward variance of GRPO sampling, thus improving the effectiveness and efficiency of training. After the basic reasoning ability of LLM policy has been improved, we further propose a test time decoding optimization method called VM-MCTS. Through Monte-Carlo Tree Search (MCTS), we collect accurate value targets with no annotation required, on which VM training is based. When decoding, the VM is deployed by an adapted MCTS algorithm to provide precise process signals as well as verification scores, assisting the LLM policy to achieve high reasoning accuracy. We validate the effectiveness of the proposed RL paradigm through extensive experiments on coding problems. Upon comparison, our approach significantly outperforms other reinforcement training baselines (e.g., naive GRPO and ReST-DPO), as well as decoding and verification baselines (e.g., PRM-BoN and ORM-MCTS) on well-known coding benchmarks of various levels (e.g., APPS, BigCodeBench, and HumanEval), indicating its power to strengthen the reasoning ability of LLM policies. Codes for our project can be found at https://github.com/THUDM/ReST-RL.
DataSciBench: An LLM Agent Benchmark for Data Science
Feb 19, 2025
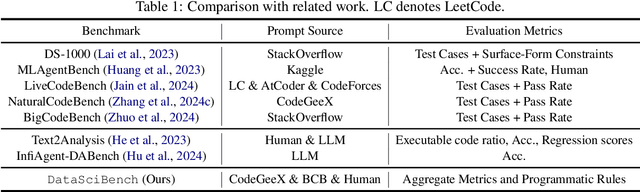
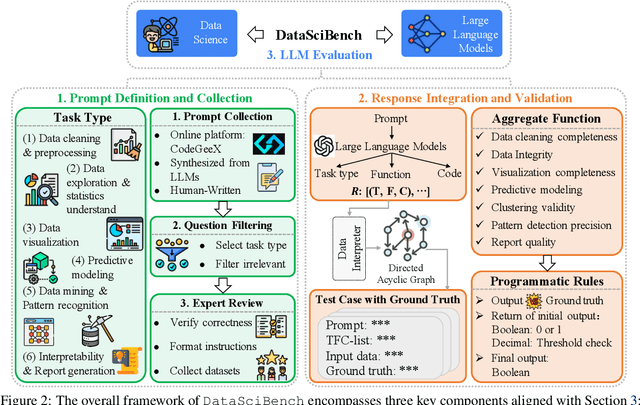
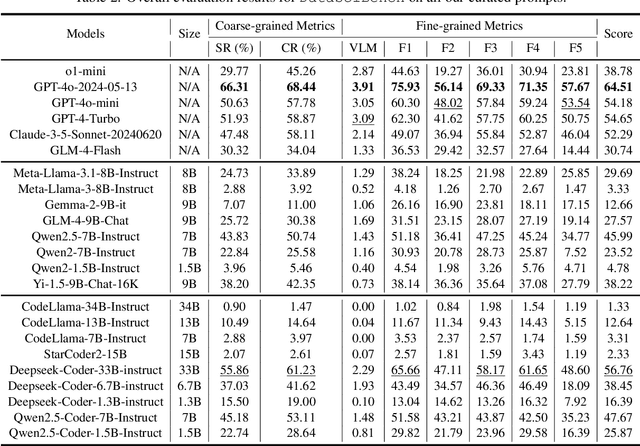
This paper presents DataSciBench, a comprehensive benchmark for evaluating Large Language Model (LLM) capabilities in data science. Recent related benchmarks have primarily focused on single tasks, easily obtainable ground truth, and straightforward evaluation metrics, which limits the scope of tasks that can be evaluated. In contrast, DataSciBench is constructed based on a more comprehensive and curated collection of natural and challenging prompts for uncertain ground truth and evaluation metrics. We develop a semi-automated pipeline for generating ground truth (GT) and validating evaluation metrics. This pipeline utilizes and implements an LLM-based self-consistency and human verification strategy to produce accurate GT by leveraging collected prompts, predefined task types, and aggregate functions (metrics). Furthermore, we propose an innovative Task - Function - Code (TFC) framework to assess each code execution outcome based on precisely defined metrics and programmatic rules. Our experimental framework involves testing 6 API-based models, 8 open-source general models, and 9 open-source code generation models using the diverse set of prompts we have gathered. This approach aims to provide a more comprehensive and rigorous evaluation of LLMs in data science, revealing their strengths and weaknesses. Experimental results demonstrate that API-based models outperform open-sourced models on all metrics and Deepseek-Coder-33B-Instruct achieves the highest score among open-sourced models. We release all code and data at https://github.com/THUDM/DataSciBench.
ReST-MCTS*: LLM Self-Training via Process Reward Guided Tree Search
Jun 06, 2024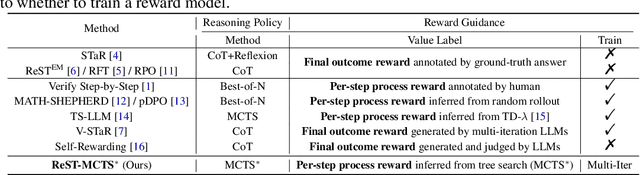



Recent methodologies in LLM self-training mostly rely on LLM generating responses and filtering those with correct output answers as training data. This approach often yields a low-quality fine-tuning training set (e.g., incorrect plans or intermediate reasoning). In this paper, we develop a reinforced self-training approach, called ReST-MCTS*, based on integrating process reward guidance with tree search MCTS* for collecting higher-quality reasoning traces as well as per-step value to train policy and reward models. ReST-MCTS* circumvents the per-step manual annotation typically used to train process rewards by tree-search-based reinforcement learning: Given oracle final correct answers, ReST-MCTS* is able to infer the correct process rewards by estimating the probability this step can help lead to the correct answer. These inferred rewards serve dual purposes: they act as value targets for further refining the process reward model and also facilitate the selection of high-quality traces for policy model self-training. We first show that the tree-search policy in ReST-MCTS* achieves higher accuracy compared with prior LLM reasoning baselines such as Best-of-N and Tree-of-Thought, within the same search budget. We then show that by using traces searched by this tree-search policy as training data, we can continuously enhance the three language models for multiple iterations, and outperform other self-training algorithms such as ReST$^\text{EM}$ and Self-Rewarding LM.
Rock Classification Based on Residual Networks
Feb 19, 2024Rock Classification is an essential geological problem since it provides important formation information. However, exploration on this problem using convolutional neural networks is not sufficient. To tackle this problem, we propose two approaches using residual neural networks. We first adopt data augmentation methods to enlarge our dataset. By modifying kernel sizes, normalization methods and composition based on ResNet34, we achieve an accuracy of 70.1% on the test dataset, with an increase of 3.5% compared to regular Resnet34. Furthermore, using a similar backbone like BoTNet that incorporates multihead self attention, we additionally use internal residual connections in our model. This boosts the model's performance, achieving an accuracy of 73.7% on the test dataset. We also explore how the number of bottleneck transformer blocks may influence model performance. We discover that models with more than one bottleneck transformer block may not further improve performance. Finally, we believe that our approach can inspire future work related to this problem and our model design can facilitate the development of new residual model architectures.
SciGLM: Training Scientific Language Models with Self-Reflective Instruction Annotation and Tuning
Jan 15, 2024
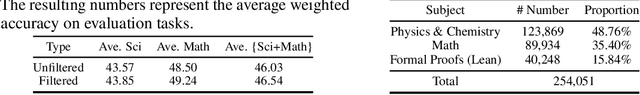
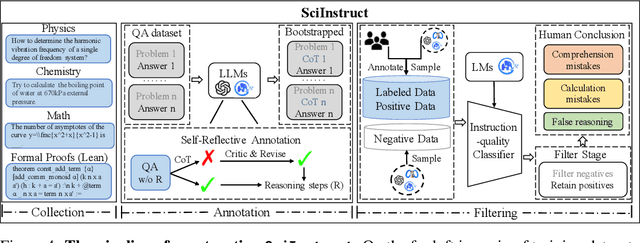
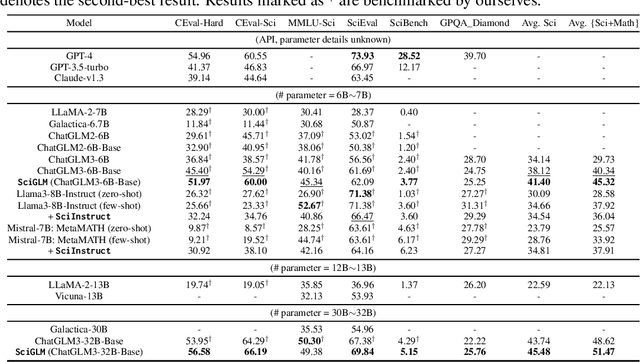
\label{sec:abstract} Large Language Models (LLMs) have shown promise in assisting scientific discovery. However, such applications are currently limited by LLMs' deficiencies in understanding intricate scientific concepts, deriving symbolic equations, and solving advanced numerical calculations. To bridge these gaps, we introduce SciGLM, a suite of scientific language models able to conduct college-level scientific reasoning. Central to our approach is a novel self-reflective instruction annotation framework to address the data scarcity challenge in the science domain. This framework leverages existing LLMs to generate step-by-step reasoning for unlabelled scientific questions, followed by a process of self-reflective critic-and-revise. Applying this framework, we curated SciInstruct, a diverse and high-quality dataset encompassing mathematics, physics, chemistry, and formal proofs. We fine-tuned the ChatGLM family of language models with SciInstruct, enhancing their capabilities in scientific and mathematical reasoning. Remarkably, SciGLM consistently improves both the base model (ChatGLM3-6B-Base) and larger-scale models (12B and 32B), without sacrificing the language understanding capabilities of the base model. This makes SciGLM a suitable foundational model to facilitate diverse scientific discovery tasks. For the benefit of the wider research community, we release SciInstruct, SciGLM, alongside a self-reflective framework and fine-tuning code at \url{https://github.com/THUDM/SciGLM}.