 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataSciBench: An LLM Agent Benchmark for Data Science
Paper and Code

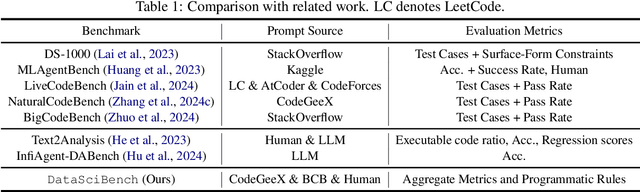
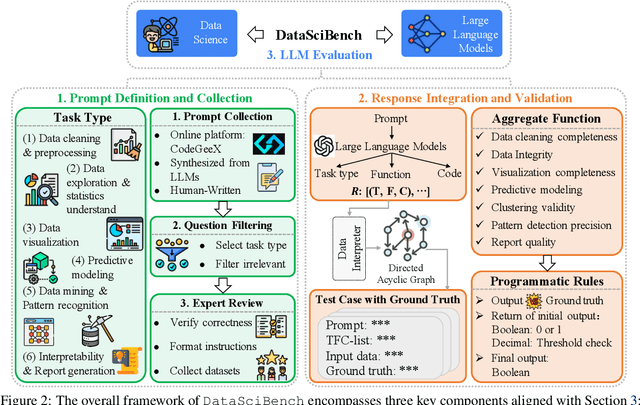
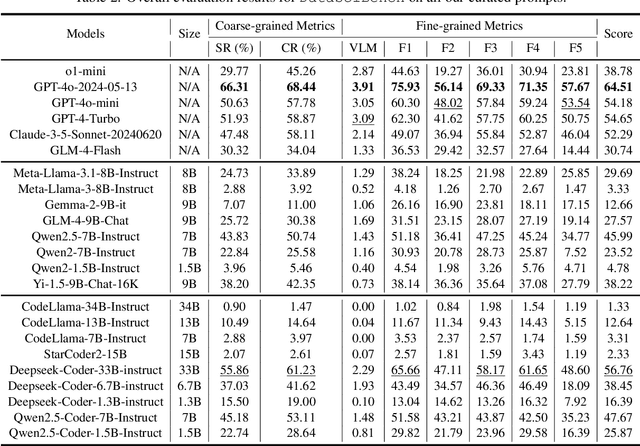
This paper presents DataSciBench, a comprehensive benchmark for evaluating Large Language Model (LLM) capabilities in data science. Recent related benchmarks have primarily focused on single tasks, easily obtainable ground truth, and straightforward evaluation metrics, which limits the scope of tasks that can be evaluated. In contrast, DataSciBench is constructed based on a more comprehensive and curated collection of natural and challenging prompts for uncertain ground truth and evaluation metrics. We develop a semi-automated pipeline for generating ground truth (GT) and validating evaluation metrics. This pipeline utilizes and implements an LLM-based self-consistency and human verification strategy to produce accurate GT by leveraging collected prompts, predefined task types, and aggregate functions (metrics). Furthermore, we propose an innovative Task - Function - Code (TFC) framework to assess each code execution outcome based on precisely defined metrics and programmatic rules. Our experimental framework involves testing 6 API-based models, 8 open-source general models, and 9 open-source code generation models using the diverse set of prompts we have gathered. This approach aims to provide a more comprehensive and rigorous evaluation of LLMs in data science, revealing their strengths and weaknesses. Experimental results demonstrate that API-based models outperform open-sourced models on all metrics and Deepseek-Coder-33B-Instruct achieves the highest score among open-sourced models. We release all code and data at https://github.com/THUDM/DataSciBench.