 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransforming volcanic monitoring: A dataset and benchmark for onboard volcano activity detection
Oct 27, 2025Natural disasters, such as volcanic eruptions, pose significant challenges to daily life and incur considerable global economic losses. The emergence of next-generation small-satellites, capable of constellation-based operations, offers unparalleled opportunities for near-real-time monitoring and onboard processing of such events. However, a major bottleneck remains the lack of extensive annotated datasets capturing volcanic activity, which hinders the development of robust detection systems. This paper introduces a novel dataset explicitly designed for volcanic activity and eruption detection, encompassing diverse volcanoes worldwide. The dataset provides binary annotations to identify volcanic anomalies or non-anomalies, covering phenomena such as temperature anomalies, eruptions, and volcanic ash emissions. These annotations offer a foundational resource for developing and evaluating detection models, addressing a critical gap in volcanic monitoring research. Additionally, we present comprehensive benchmarks using state-of-the-art models to establish baselines for future studies. Furthermore, we explore the potential for deploying these models onboard next-generation satellites. Using the Intel Movidius Myriad X VPU as a testbed, we demonstrate the feasibility of volcanic activity detection directly onboard. This capability significantly reduces latency and enhances response times, paving the way for advanced early warning systems. This paves the way for innovative solutions in volcanic disaster management, encouraging further exploration and refinement of onboard monitoring technologies.
Physics Augmented Tuple Transformer for Autism Severity Level Detection
Sep 27, 2024



Early diagnosis of Autism Spectrum Disorder (ASD) is an effective and favorable step towards enhancing the health and well-being of children with ASD. Manual ASD diagnosis testing is labor-intensive, complex, and prone to human error due to several factors contaminating the results. This paper proposes a novel framework that exploits the laws of physics for ASD severity recognition. The proposed physics-informed neural network architecture encodes the behaviour of the subject extracted by observing a part of the skeleton-based motion trajectory in a higher dimensional latent space. Two decoders, namely physics-based and non-physics-based decoder, use this latent embedding and predict the future motion patterns. The physics branch leverages the laws of physics that apply to a skeleton sequence in the prediction process while the non-physics-based branch is optimised to minimise the difference between the predicted and actual motion of the subject. A classifier also leverages the same latent space embeddings to recognise the ASD severity. This dual generative objective explicitly forces the network to compare the actual behaviour of the subject with the general normal behaviour of children that are governed by the laws of physics, aiding the ASD recognition task. The proposed method attains state-of-the-art performance on multiple ASD diagnosis benchmarks. To illustrate the utility of the proposed framework beyond the task ASD diagnosis, we conduct a third experiment using a publicly available benchmark for the task of fall prediction and demonstrate the superiority of our model.
Learning Through Guidance: Knowledge Distillation for Endoscopic Image Classification
Aug 17, 2023



Endoscopy plays a major role in identifying any underlying abnormalities within the gastrointestinal (GI) tract. There are multiple GI tract diseases that are life-threatening, such as precancerous lesions and other intestinal cancers. In the usual process, a diagnosis is made by a medical expert which can be prone to human errors and the accuracy of the test is also entirely dependent on the expert's level of experience. Deep learning, specifically Convolution Neural Networks (CNNs) which are designed to perform automatic feature learning without any prior feature engineering, has recently reported great benefits for GI endoscopy image analysis. Previous research has developed models that focus only on improving performance, as such, the majority of introduced models contain complex deep network architectures with a large number of parameters that require longer training times. However, there is a lack of focus on developing lightweight models which can run in low-resource environments, which are typically encountered in medical clinics. We investigate three KD-based learning frameworks, response-based, feature-based, and relation-based mechanisms, and introduce a novel multi-head attention-based feature fusion mechanism to support relation-based learning. Compared to the existing relation-based methods that follow simplistic aggregation techniques of multi-teacher response/feature-based knowledge, we adopt the multi-head attention technique to provide flexibility towards localising and transferring important details from each teacher to better guide the student. We perform extensive evaluations on two widely used public datasets, KVASIR-V2 and Hyper-KVASIR, and our experimental results signify the merits of our proposed relation-based framework in achieving an improved lightweight model (only 51.8k trainable parameters) that can run in a resource-limited environment.
Remembering What Is Important: A Factorised Multi-Head Retrieval and Auxiliary Memory Stabilisation Scheme for Human Motion Prediction
May 19, 2023



Humans exhibit complex motions that vary depending on the task that they are performing, the interactions they engage in, as well as subject-specific preferences. Therefore, forecasting future poses based on the history of the previous motions is a challenging task. This paper presents an innovative auxiliary-memory-powered deep neural network framework for the improved modelling of historical knowledge. Specifically, we disentangle subject-specific, task-specific, and other auxiliary information from the observed pose sequences and utilise these factorised features to query the memory. A novel Multi-Head knowledge retrieval scheme leverages these factorised feature embeddings to perform multiple querying operations over the historical observations captured within the auxiliary memory. Moreover, our proposed dynamic masking strategy makes this feature disentanglement process dynamic. Two novel loss functions are introduced to encourage diversity within the auxiliary memory while ensuring the stability of the memory contents, such that it can locate and store salient information that can aid the long-term prediction of future motion, irrespective of data imbalances or the diversity of the input data distribution. With extensive experiments conducted on two public benchmarks, Human3.6M and CMU-Mocap, we demonstrate that these design choices collectively allow the proposed approach to outperform the current state-of-the-art methods by significant margins: $>$ 17\% on the Human3.6M dataset and $>$ 9\% on the CMU-Mocap dataset.
Vision-Based Activity Recognition in Children with Autism-Related Behaviors
Aug 08, 2022
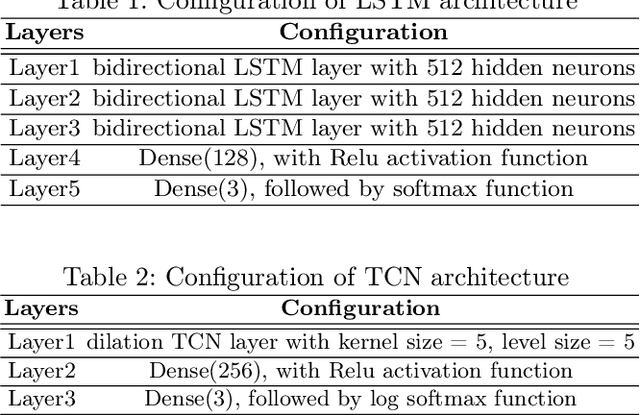

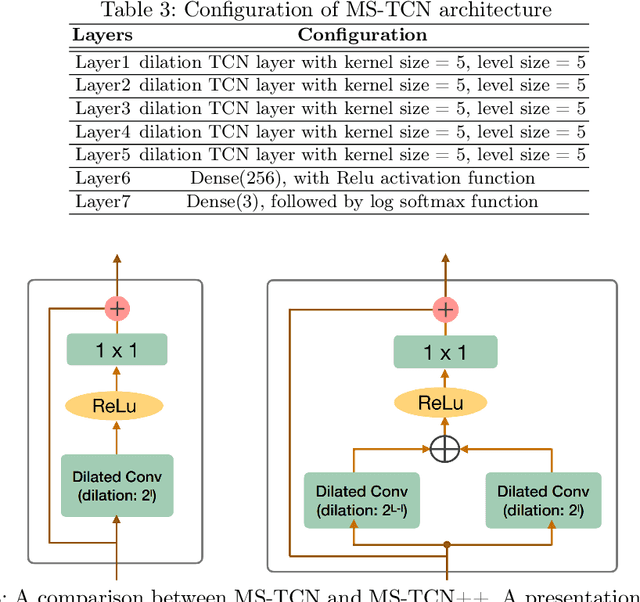
Advances in machine learning and contactless sensors have enabled the understanding complex human behaviors in a healthcare setting. In particular, several deep learning systems have been introduced to enable comprehensive analysis of neuro-developmental conditions such as Autism Spectrum Disorder (ASD). This condition affects children from their early developmental stages onwards, and diagnosis relies entirely on observing the child's behavior and detecting behavioral cues. However, the diagnosis process is time-consuming as it requires long-term behavior observation, and the scarce availability of specialists. We demonstrate the effect of a region-based computer vision system to help clinicians and parents analyze a child's behavior. For this purpose, we adopt and enhance a dataset for analyzing autism-related actions using videos of children captured in uncontrolled environments (e.g. videos collected with consumer-grade cameras, in varied environments). The data is pre-processed by detecting the target child in the video to reduce the impact of background noise. Motivated by the effectiveness of temporal convolutional models, we propose both light-weight and conventional models capable of extracting action features from video frames and classifying autism-related behaviors by analyzing the relationships between frames in a video. Through extensive evaluations on the feature extraction and learning strategies, we demonstrate that the best performance is achieved with an Inflated 3D Convnet and Multi-Stage Temporal Convolutional Networks, achieving a 0.83 Weighted F1-score for classification of the three autism-related actions, outperforming existing methods. We also propose a light-weight solution by employing the ESNet backbone within the same system, achieving competitive results of 0.71 Weighted F1-score, and enabling potential deployment on embedded systems.
Towards On-Board Panoptic Segmentation of Multispectral Satellite Images
Apr 05, 2022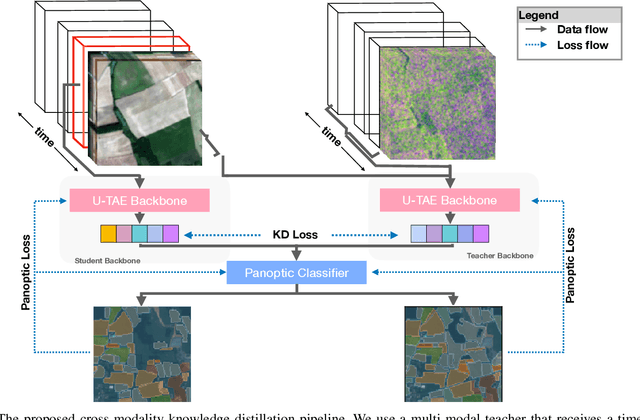


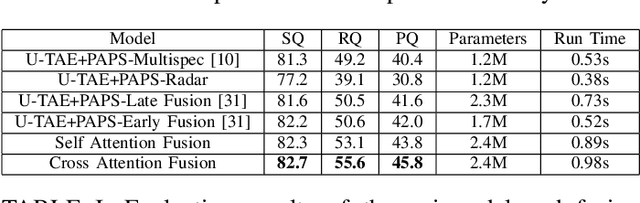
With tremendous advancements in low-power embedded computing devices and remote sensing instruments, the traditional satellite image processing pipeline which includes an expensive data transfer step prior to processing data on the ground is being replaced by on-board processing of captured data. This paradigm shift enables critical and time-sensitive analytic intelligence to be acquired in a timely manner on-board the satellite itself. However, at present, the on-board processing of multi-spectral satellite images is limited to classification and segmentation tasks. Extending this processing to its next logical level, in this paper we propose a lightweight pipeline for on-board panoptic segmentation of multi-spectral satellite images. Panoptic segmentation offers major economic and environmental insights, ranging from yield estimation from agricultural lands to intelligence for complex military applications. Nevertheless, the on-board intelligence extraction raises several challenges due to the loss of temporal observations and the need to generate predictions from a single image sample. To address this challenge, we propose a multimodal teacher network based on a cross-modality attention-based fusion strategy to improve the segmentation accuracy by exploiting data from multiple modes. We also propose an online knowledge distillation framework to transfer the knowledge learned by this multi-modal teacher network to a uni-modal student which receives only a single frame input, and is more appropriate for an on-board environment. We benchmark our approach against existing state-of-the-art panoptic segmentation models using the PASTIS multi-spectral panoptic segmentation dataset considering an on-board processing setting. Our evaluations demonstrate a substantial increase in accuracy metrics compared to the existing state-of-the-art models.
Continuous Human Action Recognition for Human-Machine Interaction: A Review
Feb 26, 2022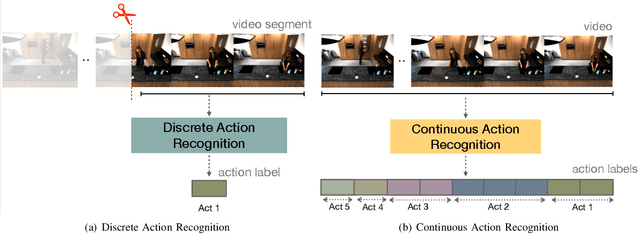
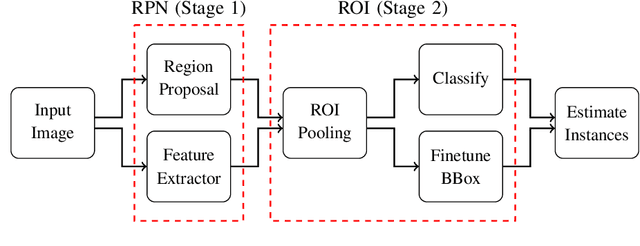
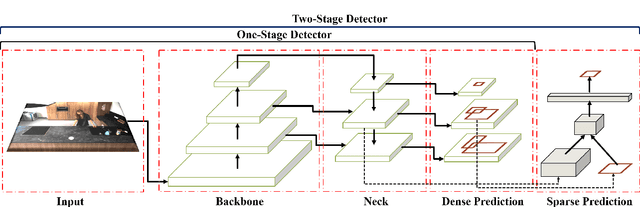

With advances in data-driven machine learning research, a wide variety of prediction models have been proposed to capture spatio-temporal features for the analysis of video streams. Recognising actions and detecting action transitions within an input video are challenging but necessary tasks for applications that require real-time human-machine interaction. By reviewing a large body of recent related work in the literature, we thoroughly analyse, explain and compare action segmentation methods and provide details on the feature extraction and learning strategies that are used on most state-of-the-art methods. We cover the impact of the performance of object detection and tracking techniques on human action segmentation methodologies. We investigate the application of such models to real-world scenarios and discuss several limitations and key research directions towards improving interpretability, generalisation, optimisation and deployment.
Multi-Slice Net: A novel light weight framework for COVID-19 Diagnosis
Aug 09, 2021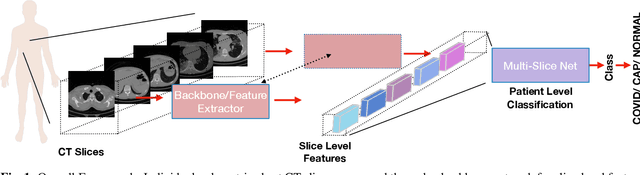

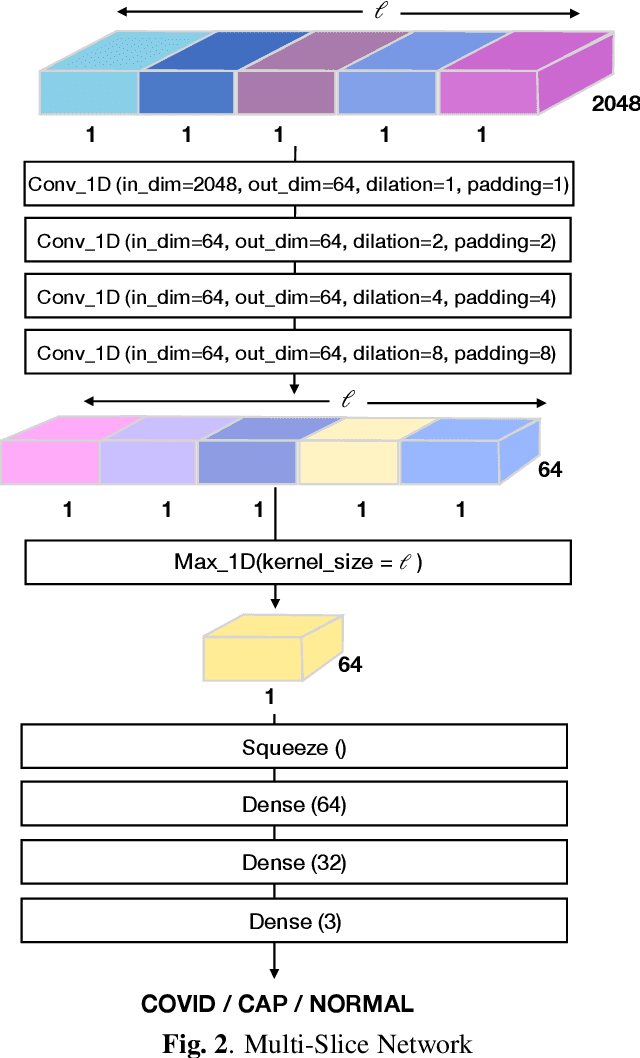

This paper presents a novel lightweight COVID-19 diagnosis framework using CT scans. Our system utilises a novel two-stage approach to generate robust and efficient diagnoses across heterogeneous patient level inputs. We use a powerful backbone network as a feature extractor to capture discriminative slice-level features. These features are aggregated by a lightweight network to obtain a patient level diagnosis. The aggregation network is carefully designed to have a small number of trainable parameters while also possessing sufficient capacity to generalise to diverse variations within different CT volumes and to adapt to noise introduced during the data acquisition. We achieve a significant performance increase over the baselines when benchmarked on the SPGC COVID-19 Radiomics Dataset, despite having only 2.5 million trainable parameters and requiring only 0.623 seconds on average to process a single patient's CT volume using an Nvidia-GeForce RTX 2080 GPU.
Deep Learning for Medical Anomaly Detection -- A Survey
Dec 04, 2020


Machine learning-based medical anomaly detection is an important problem that has been extensively studied. Numerous approaches have been proposed across various medical application domains and we observe several similarities across these distinct applications. Despite this comparability, we observe a lack of structured organisation of these diverse research applications such that their advantages and limitations can be studied. The principal aim of this survey is to provide a thorough theoretical analysis of popular deep learning techniques in medical anomaly detection. In particular, we contribute a coherent and systematic review of state-of-the-art techniques, comparing and contrasting their architectural differences as well as training algorithms. Furthermore, we provide a comprehensive overview of deep model interpretation strategies that can be used to interpret model decisions. In addition, we outline the key limitations of existing deep medical anomaly detection techniques and propose key research directions for further investigation.
Multi-modal Fusion for Single-Stage Continuous Gesture Recognition
Nov 10, 2020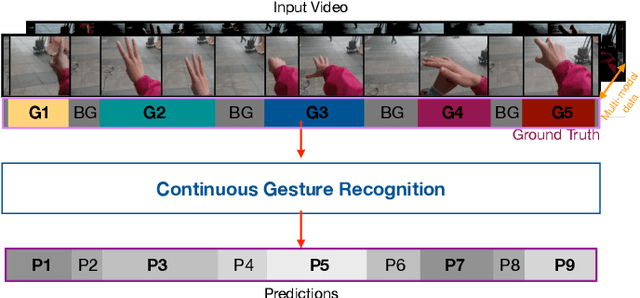
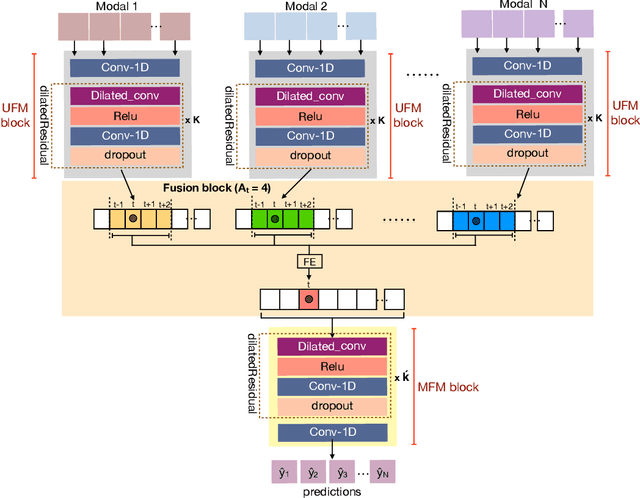

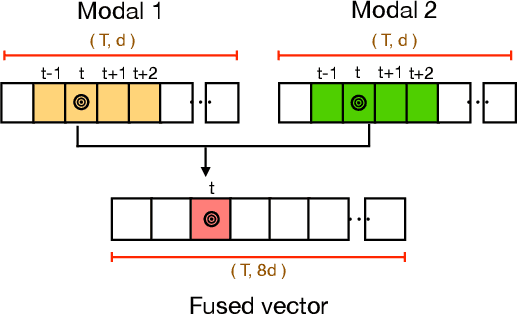
Gesture recognition is a much studied research area which has myriad real-world applications including robotics and human-machine interaction. Current gesture recognition methods have heavily focused on isolated gestures, and existing continuous gesture recognition methods are limited by a two-stage approach where independent models are required for detection and classification, with the performance of the latter being constrained by detection performance. In contrast, we introduce a single-stage continuous gesture recognition model, that can detect and classify multiple gestures in a single video via a single model. This approach learns the natural transitions between gestures and non-gestures without the need for a pre-processing segmentation stage to detect individual gestures. To enable this, we introduce a multi-modal fusion mechanism to support the integration of important information that flows from multi-modal inputs, and is scalable to any number of modes. Additionally, we propose Unimodal Feature Mapping (UFM) and Multi-modal Feature Mapping (MFM) models to map uni-modal features and the fused multi-modal features respectively. To further enhance the performance we propose a mid-point based loss function that encourages smooth alignment between the ground truth and the prediction. We demonstrate the utility of our proposed framework which can handle variable-length input videos, and outperforms the state-of-the-art on two challenging datasets, EgoGesture, and IPN hand. Furthermore, ablative experiments show the importance of different components of the proposed framework.